










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkProspectiva
Print version ISSN 1692-8261
Prospect. vol.14 no.1 Barranquilla Jan./June 2016
https://doi.org/10.15665/rp.v14i1.640
Clasificación de los frutos de café según su estado de maduración y detección de la broca mediante técnicas de procesamiento de imágenes
Classification of coffee fruits based on ripeness and broca detection using image processing techniques
Jean Carlos Herrera Pérez1, Silfri Manuel Medina Ortiz1, Gabriel Enrique Martínez Llano 1,
Kelvin de Jesús Beleño Sáenz2, Julie Stephany Berrio Pérez2
1 Ingeniero Mecatrónico, 2MSc. Docente Tiempo Completo,
1,2Grupo de Investigación en Ingeniería Mecatrónica (GIIM), Universidad Autónoma del Caribe. Barranquilla, Colombia. E-mail: jean.herrera@uautonoma.edu.co
Recibido 30/11/2014 Aceptado 09/12/2015
Cite this article as: J. Herrera, S. Medina, G. Martinez, K. Beleño, J. Berrio, "Classification of coffee fruits based on ripeness and broca detection using image processing techniques, Prospect, Vol 14, N° 1, 15-22, 2016.
Doi: http://dx.doi.org/10.15665/rp.v14i1.640
RESUMEN
En el presente artículo se plantea el desarrollo de dos algoritmos de procesamiento de imágenes para la identificación del café idóneo para producción, uno de acuerdo al color de este (estado de maduración) y otro para detectar la plaga de la broca. El clasificador de color consta de varias etapas: una base de conocimiento que consta de un banco de imágenes de frutos de café maduro y verde, una etapa de preprocesado para limpiar impurezas y filtrar ruido en la imagen; prosigue la segmentación para extraer el objeto de interés. Luego se extraen las características de color de la imagen y por último el proceso de reconocimiento e interpretación, el cual consta de una red neuronal artificial que clasifica los frutos en maduros o verdes. Por otra parte, el algoritmo de detección de broca fue desarrollado mediante un criterio de binarización, esto para buscar las zonas negras en la imagen, como el orificio dejado por esta plaga sobre el fruto de café. El clasificador por redes neuronales propuesto tuvo una efectividad de 97% al detectar los estados de madurez de los frutos de café, demostrando así que las técnicas de visión artificial para el control de calidad en los frutos de café son un método viable y poco invasivo.
Palabras clave: Extracción de Características; Redes Neuronales Artificiales; Análisis de color de imágenes, Procesamiento de imágenes; Segmentación de imágenes; Clasificación de imágenes, Visión artificial.
ABSTRACT
In the present article is proposed the development of two algorithms, one to determine if a coffee fruit is proper for production based on its color (ripeness) and the other one to detect the presence of the "broca" plague. The color classifier consists of several stages: a knowledge database, which has a bank of coffee-fruits images in ripe and unripe state; a stage of pre-processing to clean up noise in the image; next, the segmentation process to extract the object of study, then follows the color-characteristics extraction process. Finally, the classifier, which consists of an artificial neural network where fruits are classified ripe or unripe. On the other hand, the broca detection algorithm was developed by means of binarization, in order to search for dark zones in the image, as it is the aperture made by the broca on the coffee. The artificial neural network proposed had an effectiveness of 97% at detecting the ripe state of the coffee fruits, therefore demonstrating the viability and the minimal invasion of the method proposed for the quality control of coffee fruits.
Key words: Feature Extraction; Artificial Neural Networks; Image color analysis; Image analysis; Image segmentation; Image classification; Machine vision.
1. INTRODUCCIÓN
Si hay algo por lo que Colombia es mundialmente reconocida es por la calidad de su café. Este fruto es cultivado en la zona conocida como Eje Cafetero, el cual se caracteriza por ubicarse a 2100 MSNM, presentando un clima templado con tendencia a presentar lluvias durante gran parte del año.
El procesado del café en Colombia es realizado manualmente. Los caficultores recolectan el fruto directamente del árbol, para luego ser despulpado, bien sea a mano o con un despulpador mecánico. Luego es lavado, proceso en el cual se remueven muchas impurezas; posteriormente los granos son esparcidos a terreno abierto donde el sol les incida directamente hasta que los granos se sequen. Por último, el café es molido e inspeccionado para después de ser empacado y estar listo para su distribución.
Debido al factor humano, este proceso es propenso a errores, además de que genera un gran desgaste físico en los caficultores. Con base en la experiencia de distintos ingenieros a nivel global y local, se plantea el diseño de un sistema de visión artificial que automatice una parte del procesado del café, específicamente diseñado para clasificar el café bueno y el malo. Esto con miras a futuro de un sistema que realice automáticamente la producción completa del café. Este sistema se ubicará entre las etapas de recolección y despulpado. Esto con el objetivo de evitar granos de café en mal estado en el posterior proceso de despulpado, ya sea por falta de maduración, sobre-maduración, o algún otro defecto presente en el fruto.
De manera general, el sistema consistirá en una etapa de adquisición de la imagen de los frutos de café a analizar en un ambiente de iluminación controlada. Posterior a esta fase se procesará la imagen con el objetivo de eliminar impurezas o ruido presente en ella. Como tercera etapa se aplicará un algoritmo de segmentación para aislar el fruto del fondo; esto con el objetivo de extraer las características principales del café, empezando así con el cuarto paso del sistema de clasificación. Este último, consistirá en un algoritmo de reconocimiento de patrones formado por una base de conocimiento previo en la que se encuentran imágenes de referencia de los frutos de café buenos y malos; sobre los cuales se efectúa la comparación.
En España, se emplea la visión artificial para la automatización de la inspección de los gajos de mandarina, haciendo uso de distintos tipos de redes neuronales para la clasificación feed forward con distintas funciones de activación, siendo la función tan-sig (T) la que obtuvo mejores resultados con un índice de fiabilidad del 92,5%, tipo Elman cuyo índice de fiabilidad fue del 93% y la de tipo Radial Basis, con un ancho (spread) del 10, obtuvieron un dice de fiabilidad del 98% [1].
A nivel nacional ya se han realizados trabajos basados en visión artificial con frutos de café para medir el estado de maduración de los granos, como Ramos Jimena et al [2] donde presenta un método de identificación de las cuatro etapas de maduración de los frutos del café y su implementación en un circuito electrónico, método basado en la representación de color HSV (Hue-Saturation-Value). O el realizado por Sandoval de la Universidad Nacional sede Manizales. Ella empleó 3 tipos de algoritmos de clasificación, no sin antes haber procesado un total de 208 características morfológicas y resumirlas a sólo 9. Implementó clasificadores bayesianos, redes neuronales y clustering difuso. Obteniendo diferentes resultados para cada uno, el clasificador bayesiano tuvo el menor error con un valor de 5 %, mientras que la técnica de clustering difuso fue la de respuesta más rápida alcanzando un valor de 0.1ms, con un error máximo del 19 % [3].
Muchos autores de proyectos relacionados con el procesamiento de imágenes también consideraron lo beneficioso que sería emplear sistemas de visión artificial para la selección de frutas y verduras de calidad en la industria colombiana. Es por eso que Díaz J. en [4], diseñó un selector de granos buenos de café. Al igual que en los proyectos anteriormente mostrados, Díaz J. también utilizó varios métodos de clasificación con la intención de encontrar el más óptimo. Entre los más característicos probó el método de comparación de plantillas y la comparación de histogramas. Observó que la clasificación de histogramas resultaba más eficiente, sin embargo en ocasiones arrojaba falsos positivos. Para corregir este detalle, se sugirió estudiar los histogramas de los granos de café en formato RGB en lugar de la escala de grises como se hizo al principio.
Se sabe que la visión artificial no sólo ha servido para la identificación de frutos tipo baya, como el café, sino que también puede aplicarse a frutas de formas más irregulares. Luis Silva y Sergio Lizcano en [5], diseñaron un sistema que pudiera seleccionar las frutas que presentaran el grado de maduración más adecuado para tener la fruta en el punto de mayor calidad. El sistema fue provisto con fotografías de piñas en sus diversas fases (maduras, verdes, sobre-maduradas). Lo que lo diferencia del proyecto anterior no es tanto su algoritmo de clasificación, sino que analizaron las frutas en un espacio de color diferente al convencional RGB; en su lugar usaron el espacio de color HSV porque evidenciaron que en dicho espacio se podía analizar de manera más directa las cualidades que definen la maduración de la piña. El clasificador propuesto por los autores obtuvo un desempeño del 96.36%.
Resolver un problema por medio de procesamiento de imágenes permite tomar una gran diversidad de herramientas matemáticas para poder llegar a la solución deseada. Beleño y Meza en [6], de la Universidad Autónoma de Caribe, diseñaron un clasificador de frutos de café basados en su textura. Para ello se extrajeron las características de los granos mediante la transformada de Wavelet y se eligieron las más relevantes por medio de un análisis de Fisher. El algoritmo de clasificación fue una red neuronal de 2 neuronas de entrada, 10 en la capa oculta y 5 neuronas en la capa de salida, entrenadas por medio del método de entrenamiento backpropagation.
Investigadores de la Universidad Nacional de Colombia sede Manizales, emplean la visión artificial para caracterizar la rugosidad del café en su etapa de desarrollo verde y maduro. Estos autores emplearon el barrido por la técnica de la Microscopia de Fuerza Atómica (MFA) en el modo de contacto intermitente (MFA-I), obteniendo valores de rugosidad media (Ra) y cuadrática media (RMS) para la identificación de frutos maduros [7].
Otra aplicación de la visión artificial en la agricultura es la realizada en [8], en la cual se propone un sistema que clasifique la fruta Arazá, proveniente de la selva Amazonía colombiana, según su estado de maduración. Los autores utilizaron estrategias de aprendizaje híbridas con redes neuronales y sistemas difusos y las implementaron en plataformas FPGA y DSP. Además, evaluaron dos formas de tomar la imagen, una por medio de un recuadro centrado en el fruto y la otra una imagen total. Se encontró que la implementación del primer método tenía un consumo menor en hardware que el segundo. Sin embargo, al analizar la imagen completa se obtiene una mayor precisión, exactamente del 90%. En contraste, al analizar la imagen por medio de un recuadro centrado se obtuvo un 70% de precisión.
2. METODOLOGÍA
El diseño de este sistema de visión artificial está basado en un estudio implementado de tipo descriptivo debido a su gran énfasis en el análisis de las características fundamentales de los frutos de café. La selección de dichos patrones está basada en los trabajos realizados en otras áreas del Eje Cafetero y en otros países.
2.1 Esquema general
En la figura 1 se observa el esquema general propuesto para el clasificador de color. La primera etapa consta de la adquisición de las imágenes, luego esas pasan por procesos como la segmentación y extracción de características. El tipo de clasificador es una red neuronal de base radial, por lo tanto las características extraídas en la etapa anterior pasan por un proceso de entrenamiento, y luego hacen parte de la base de conocimiento. Una vez entrenada la red neuronal, esta será capaz de identificar un fruto de café que haga parte de las imágenes de prueba como maduro o verde.
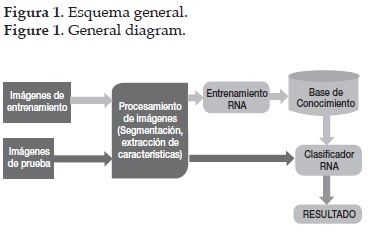
2.2 Adquisición de imágenes
Las imágenes fueron tomadas en un ambiente de luz controlada, con iluminación de tipo difusa y con dos fuentes de luz de tipo fluorescente. Además se usó un fondo blanco, con el objetivo de facilitar el proceso de segmentación más adelante. En la figura 2 se observa el sistema de iluminación usado para la captura de las imágenes. Las fotografías fueron tomadas a una distancia de 15 cm aproximadamente (dependiendo del diámetro del fruto), con una cámara de 5 MP con una distancia focal de 3.54 mm y una apertura de 2.6. Los algoritmos fueron implementados con el software Matlab empleando la "Image Processing Toolbox".

Un total de 248 frutos de café se recolectaron para su uso en el presente estudio, 70 frutos verdes y 178 frutos maduros. Para el entrenamiento del clasificador se tomaron 30 capturas para cada estado de maduración del fruto, para un total de 60 imágenes para dicha etapa; equivalentes a un 24.19% del total de frutos recolectados. Para la evaluación del rendimiento del clasificador se usaron 80 frutos, 40 para cada estado de maduración; equivalentes al 32.26% del total recolectado. En la figura 3 se observa una captura de uno de los frutos de café verde.

2.3 Segmentación
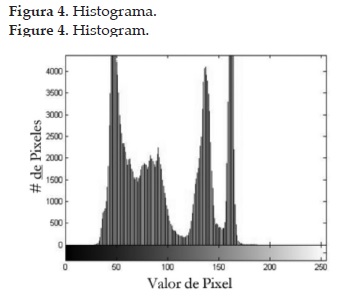
El proceso de segmentación consiste en distinguir y separar cada uno de los objetos presentes en la escena de la imagen. En el caso particular de este artículo, se requiere separar el fruto de café del fondo. De esta manera, en la etapa de extracción de características se obtendrán las propiedades relacionadas únicamente con el fruto de café y no de objetos ajenos que puedan perturbar el proceso de clasificación. Al analizar el histograma (ver figura 4) de las capturas en escala de grises, se observa el contraste entre el fondo y el café. Por lo tanto, se usa como técnica de segmentación la binarización, específicamente el método de Otsu. Este método permite hallar el umbral óptimo entre dos distribuciones gaussianas de forma automática [9].
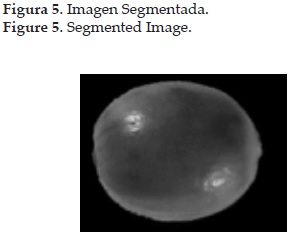
En esta imagen ha sido eliminada la información innecesaria (el fondo, ver figura 5) para el proceso de entrenamiento y clasificación, dejando solo la pertinente al problema, el fruto de café.
2.4 Modelos de color
Como característica principal de un fruto de café apto para producción se encuentra su nivel de maduración. Un café verde no es adecuado para el proceso, conllevando en un resultado muy malo en el producto final en lo que a sabor respecta. Por lo tanto, se extraen características de colores, específicamente de los modelos de color RGB, HSI y L*a*b*.
Conversión RGB a HSI: Una de las grandes ventajas del uso del modelo de color HSI es su capacidad de describir los colores como un humano lo haría, por su tono y saturación, en contraste con el modelo RGB, el cual representa un color con base a las proporciones de los colores primarios (rojo, verde y azul). Debido a que las imágenes obtenidas por la cámara se encuentran en el modelo RGB, esas deben ser convertidas al espacio HSI previo a cualquier operación. Las ecuaciones 1, 2, 3 y 4 permiten convertir al espacio de color HSI por medio de las componentes RGB [10], [11] Deben ser transformadas al espacio HSI y al L*a*b*.
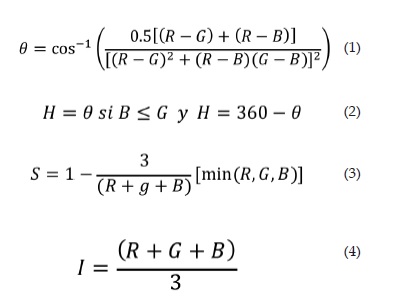
Conversión RGB a L*a*b*: El modelo CIE L*a*b* es un estándar internacional para la medición de color, adoptada por la Comisión International d'Eclairage (CIE) en 1976. Al igual que el modelo HSI, L*a*b* separa la información de intensidad de las componentes relacionadas con el color. La componente L* almacena los valores de intensidad (con un rango de 0 a 100), los valores de a* oscilan entre verde y rojo; y los valores de b* varían de azul a amarillo (rango de -120 a 120 para ambas componentes cromáticas). Las ecuaciones 5, 6, 7, 8 y 9 expresan la transformación del modelo RGB a L*b*a* [12], [13].

Donde Xw, Yw y Zw son los valores tri-estímulo CIE XYZ del punto blanco de referencia.
2.5 Extracción de características
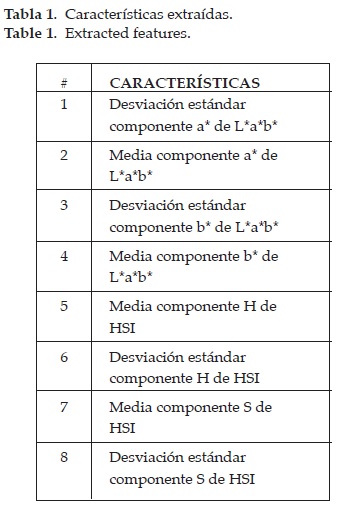
Debido a que se analizará la aptitud del café para el proceso de producción de acuerdo a su estado de madurez, las características adecuadas a analizar son las de color. A través de la media y la desviación estándar se puede cuantificar la información con respecto al color de los frutos. Pero para lograr esto, se deben seleccionar las componentes de los modelos de color adecuados para dicho proceso. Como se mencionó en la sección anterior, las componentes a* y b* del espacio de color L*a*b*, determinan que cantidad de color hay en la fruta. Siendo a* la variación entre rojo y verde; y b* entre amarillo y azul. De igual manera, las componentes H y S del espacio HSI son las componentes que guardan la información de color. Por lo tanto, estas cuatro componentes son analizadas. Como ya se ha mencionado, para poder estudiarlas se necesita una medida de ellas. Por lo tanto, se calcula la media y la desviación estándar de las componentes a*, b*, H y S; obteniendo un total de 8 características (ver tabla 1), 2 por cada componente de la captura analizada. La media y la desviación estándar están representadas por 10 y 11 respectivamente. Donde, N es la cantidad total de pixeles en la imagen y X el pixel analizado [14], [15].
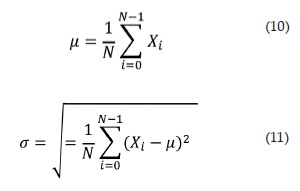
2.6 Algoritmo de clasificación
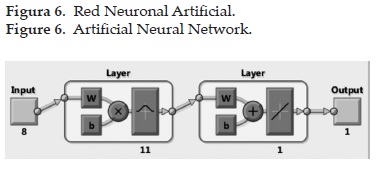
Como clasificador se implementó una red neuronal de base radial (ver figura 6) empleando la "Neural NetWork Toolbox" de Matlab. Dicha red está conformada por un vector de entrada de 8 posiciones (correspondientes a las características extraídas de la imagen), una capa oculta con 11 neuronas, las cuales presentan la función de activación de base radial en 12. Y por último la capa de salida con una sola neurona de activación lineal, caracterizada por 13 [16]. El error cuadrático medio alcanzado con 11 iteraciones por esta red neuronal fue de 0.00859569.
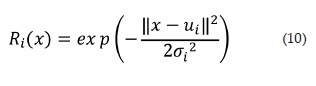
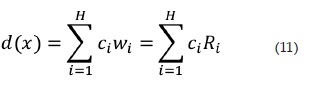
2.7 Detección de broca
Para desarrollar el algoritmo de detección de broca se parte desde la posición de la cámara, esta debe encontrarse frente al ombligo del fruto de café, el cual es el punto de entrada de la plaga hacia el fruto. En cuanto al algoritmo, se utilizó segmentación mediante el método del valor umbral (ver ecuación 14) con el fin de detectar las zonas oscuras en la imagen, debido al agujero que deja la broca sobre el café, la cual es evidencia de la presencia de ella.
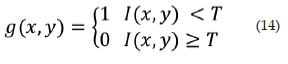
Donde, I(x,y) es la imagen de entrada en escala de grises, g(x,y)es la imagen resultante binarizada, y T es el umbral definido para la operación de binarización. Como el algoritmo se basa en detectar las zonas más oscuras de la imagen, el umbral T escogido fue de 30, ya que valores mayores pueden llevar a falsas detecciones.
3. RESULTADOS Y DISCUSIÓN
Para la prueba del clasificador se usaron un total de 80 imágenes, 40 de frutos maduros y 40 de frutos verdes. Para analizar el rendimiento del clasificador se utilizó la curva ROC (Reciever Operating Characteristic). Éste representa la relación existente entre las muestras clasificadas adecuadamente (verdaderos positivos) y las muestras que no pertenecen a la clase pero fueron clasificadas como tal. El desempeño en la curva ROC se mide por medio del área bajo su curva (AUC por sus siglas en inglés). Mientras mayor sea el área, mayor es la efectividad del clasificador [17].
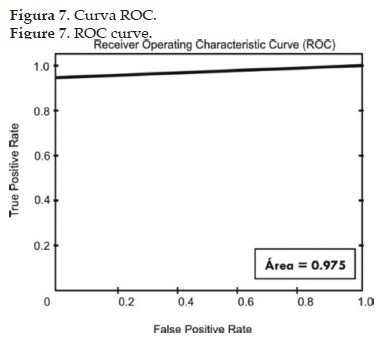
En la figura 7 se observa la curva ROC para el clasificador usado en esta investigación. Este presentó un área bajo la curva de 0.975, por lo tanto el clasificador tiene un gran rendimiento, dado que una clasificación perfecta tiene un área igual a 1; y el clasificador propuesto se acerca bastante a esta cifra. En relación al algoritmo de detección de brocas, como se observa en la figura 8a, el café presenta un orificio en su superficie causado por la broca; al aplicar el criterio de binarización de la ecuación 14 se obtiene como resultado la imagen de la figura 8b, una detección correcta de la broca.

Los resultados de esta investigación confirman la gran utilidad de los clasificadores de color para la detección de los cafés buenos y malos, además de corroborar lo que distintos autores han realizado y recomendado en investigaciones similares. Como claramente recalcó Díaz J. en la conclusión de su trabajo, es mucho más eficiente utilizar una escala de colores que la escala de grises a la hora de evaluar la calidad de los frutos de café. Esto se evidencia en los resultados obtenidos por otros autores, como Sandoval en [3] que obtuvo un 95% de rendimiento, Silva y Lizcano en [5] obteniendo 96.36%, pero en su caso clasificando piñas de acuerdo a su maduración, y la presente investigación logrando 97.5%; obteniendo así una pequeña mejora en relación a trabajos previos.
Sin embargo, algo que no se ha tenido en cuenta en otras investigaciones es el análisis de la broca mediante visión artificial. Dicho análisis es propuesto en este artículo, y se logró un resultado satisfactorio al detectar la broca en el fruto, sin embargo; resta desarrollar con mayor profundidad el algoritmo para lograr un mayor nivel de confiabilidad.
4. CONCLUSIONES
- Los resultados mostrados por la curva ROC indican que la red neuronal de base radial se desempeña de manera óptima como clasificador para detectar la maduración del café. Además, usando un algoritmo con bajo costo computacional y simple de implementar, como lo es la segmentación por el método del valor umbral, fue posible detectar adecuadamente un orificio dejado por una broca sobre un fruto de café.
- Con base a los resultados obtenidos, se puede concluir que es posible la utilización de técnicas de visión artificial para el control de calidad de los frutos de café, tendiendo como principal ventaja el ser un método no invasivo y que mantiene al mínimo el contacto con el producto tratado.
- Con miras a una futura implementación en la industria, como futura investigación se propone el diseño de un sistema mecánico que separe los frutos de café buenos de los malos, logrando así un sistema completo de clasificación de frutos de café.
REFERENCIAS
[1] J.S. Muro, P.N. Lorente, P.A. Garau, C.F. Andrés and B.M Al-Hadithi. "Solución basada en visión artificial para la inspección automatizada de gajos de mandarina", 2014. [Online]. Disponible: http://www.interempresas.net/Horticola/Articulos/122395-Solucion-basada-en-vision-artificial-para-la-inspeccion-automatizada-de-gajos-de-mandarina.html [ Links ]
[2] P. Ramos, J. Sanz and C. Oliveros. "Identificación y clasificación de frutos de café en tiempo real a través de la medición de color", 2014. [Online]. Disponible: http://hdl.handle.net/10778/506 [ Links ]
[3] Z. L. S. Niño and F. A. P. Ortiz, "Caracterización de café cereza empleando técnicas de visión artificial", Revista Facultad Nacional de Agronomía- Medellín, 60 (2), 4105-4127, 2007. [ Links ]
[4] J. A. D. Acevedo, "Diseño de un sistema de selección de café mediante la caracterización de imágenes", ENGI Revista Electrónica de la Facultad de Ingeniería, 1(2), 2013. [ Links ]
[5] L. A. Silva and S. Lizcano, "Evaluación del estado de maduración de la piña en su variedad perolera mediante técnicas de visión artificial", Iteckne, 9 (1), 2012. [ Links ]
[6] O. Álvarez and N. Beleño, "Clasificador de Textura de los Frutos de Café Según su Etapa de Maduración Utilizando Transformada de Wavelet", Tesis Pregrado. Barranquilla, Universidad Autónoma del Caribe. 2012. [ Links ]
[7] Y. Cardona, C. Oliveros, D. Arias, A. Devia, J. Arcila, and F. A Álvarez, "Caracterización de la rugosidad de frutos del café variedad Colombia en dos estados de desarrollo", Cenicafé, 59 (3), 204-213, 2008. [ Links ]
[8] M. Tovar, H. Vargas, Y. Bermeo. (2015, Junio) Artificial Vision in Agricultural Products Classification. Presentado en VII Congreso Iberoamericano de Telemática, 2015. [Online] Disponible: http://www.researchandinnovationbook.com/PROCEEDINGS/CITA2015/Archives/papers/paper50.pdf [ Links ]
[9] M. Nixon. Feature Extraction & Image Processing. Feature Extraction and Image Processing Series. Elsevier Science, 2008. [Online]. Disponible: http://books.google.com.co/books?id=97QebyNxyaYC [ Links ]
[10] R. Gonzalez and R. Woods, Digital Image Processing. Pearson Prentice Hall, 2008. [Online]. Disponible: http://books.google.com.co/books?id=8uGOnjRGEzoC [ Links ]
[11] T. Acharya and A. Ray, Image Processing Principles and Applications. Wiley Interscience, 2005. [Online]. Disponible: https://books.google.com.co/books?isbn=0471745782 [ Links ]
[12] V. S. M. Neelamma K. Patil, "Color and texture based identification and classification of food grains using different color models and haralick features," International Journal on Computer Science and Engineering (IJCSE), 3, (12), Dec 2011. [ Links ]
[13] L. Rastislav and N. Konstantinos, Fundamentals of Artificial Neural Networks. CRC Press, 2006. [Online]. Disponible: https://books.google.com.co/books?isbn=1420009788 [ Links ]
[14] D. Savakar, "Identification and classification of bulk fruits images using artificial neural networks," International Journal of Engineering and Innovative Technology (IJEIT), 1, (3), March 2012. [ Links ]
[15] M. Hassoun, Fundamentals of Artificial Neural Networks. A Bradford Book, 1995. [Online]. Disponible: https://books.google.com.co/books?isbn=026208239X [ Links ]
[16] J. Jang, C. Sun, and E. Mizutani, Neuro-fuzzy and soft computing: a computational approach to learning and machine intelligence, ser. MATLAB curriculum series. Prentice Hall, 1997. [Online]. Disponible: http://books.google.com.co/books?id=vN5QAAAAMAAJ [ Links ]
[17] G. Daza, L. G. Sánchez, and J. F. Suárez, "Selección de características orientada a sistemas de reconocimiento de granos maduros de café", Scientia et Technica., 3, (35), 2007. [ Links ]

