











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. INTRODUCCIÓN
En la actualidad los lenguajes de señas son el método efectivo para la comunicación verbal de las personas sordas, con dificultades auditivas y de las personas que tienen dificultades para hablar. No existe un lenguaje de señas universal, y casi cada país tiene su propia lengua de señas nacional. Todos los lenguajes de señas usan signos visual-cinéticos para la comunicación humano-humano combinando gestos manuales con articulación de labios y mímicas faciales. También poseen una gramática específica y simplificada que es muy diferente de la de las lenguas habladas acústicas.
Las lenguas de los signos son habladas (en silencio) por cien millones de personas sordas en todo el mundo. En total hay al menos 138 idiomas de señas vigentes según el catálogo de Etnología, y muchos de ellos son lenguas oficiales (nacionales) u oficiales de la comunicación humana en algunos países como Estados Unidos, Finlandia, la República Checa, Francia, la Federación de Rusia (desde 2013), etc. De acuerdo con las estadísticas de las organizaciones médicas, alrededor del 0,1% de la población de cualquier país es absolutamente sorda y la mayoría de esas personas se comunican únicamente por lenguaje de señas.
Muchas personas que nacieron sordas incluso no son capaces de leer. Además de los lenguajes de las lenguas de conversación, también hay alfabetos que se utilizan para deletrear letras (nombres, palabras raras, signos desconocidos, etc.), letra por letra [1].
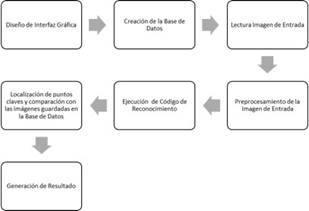
En este artículo se presenta el desarrollo de un sistema de reconocimiento de gestos no móviles del lenguaje de señas colombiano, mediante el procesamiento digital de imágenes. El Sistema se divide principalmente en cuatro fases: adquisición de imagen, procesamiento de la imagen, reconocimiento de la imagen y muestra de resultado.
Según estadísticas arrojadas por el Departamento Administrativo Nacional de Estadística (DANE), en Colombia el 6,4% de los habitantes tiene una limitación permanente; de este grupo el 17,3% de las personas, tienen limitaciones permanentes para oír, es decir, que, de cada 100 colombianos con limitación, 17 presentan algún tipo de discapacidad permanente auditiva [2].
La comunicación mediante el lenguaje de señas es casi imprescindible en el día a día de un ser humano que sufre de limitación auditiva, pues a partir de ella puede entrar a relacionarse con las personas que le rodean y a la vez con su entorno, por lo que se hace un reto aprender cada una de las señas que conforman su sistema de comunicación, y más aún para las personas sin discapacidad al momento de lograr descifrar el mensaje proporcionado por esta población. Es por esto que surge la necesidad de desarrollar una herramienta que permita reconocer los gestos que son realizados por personas con discapacidad auditiva, con el fin de brindar una herramienta didáctica que permita a las personas que están aprendiendo este tipo de lenguaje (discapacitados o no discapacitados); lo puedan hacer de una manera más interactiva y amigable con su entorno.
“El lenguaje de señas se caracteriza por ser visual y corporal, es decir la comunicación se establece con el cuerpo en un espacio determinado” [3].
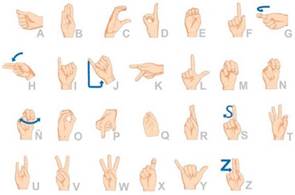
El Lenguaje de Señas Colombiano (LSC) fue reconocido en el año 1996 y es el lenguaje oficial utilizado por la comunidad sorda del país. El LSC consta de 27 señas que representan a cada una de las letras del alfabeto, mediante la unión de varias señas se puede lograr expresar palabras, frases e ideas completas. En la implementación del sistema solamente se utilizan 20 señas no móviles del LSC debido a que esta investigación se basa principalmente en el análisis y tratamiento de imágenes. La figura 1 contiene todos los caracteres que representan el alfabeto en el LSC.
Por otro lado, el procesamiento de imágenes consiste en todos los métodos y técnicas implementados para extraer información de la imagen. La segmentación es una de esas técnicas la cual básicamente busca separar el fondo del objeto de interés. Las imágenes en su mayoría están compuestas por zonas que tienen características similares (nivel de gris, textura, momentos, etc.). Generalmente estas zonas corresponden a objetos de la imagen. La segmentación de una imagen consiste en la división o partición de la imagen en varias zonas o regiones homogéneas y disjuntas a partir de su contorno, su conectividad, o en términos de un conjunto de características de los píxeles de la imagen que permitan discriminar unas regiones de otras. Entre las características utilizadas en la segmentación encontramos: los tonos de gris, la textura, los momentos, la magnitud del gradiente, la dirección de los bordes, entre otras [4].
Actualmente existen varios enfoques de reconocimiento de objetos, de los cuales los más conocidos son:
Reconocimiento estadístico: se basa en la determinación y uso de funciones de probabilidad [5].
Reconocimiento sintáctico: analiza la estructura de los objetos, por ejemplo: el esqueleto [6].
Reconocimiento de redes neuronales: constituye la técnica más reciente y trata de imitar el funcionamiento de los sistemas biológicos [7].
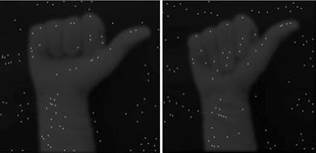
En el desarrollo del sistema de reconocimiento de gestos no móviles se utilizó el reconocimiento estadístico mediante el cual, para la detección de gesto de la mano, fue necesario hallar los puntos clave característicos de cada imagen con el fin de poder compararlos con la imagen de entrada y finalmente si existe una coincidencia mostrar la imagen de salida obtenida. Este método se conoce como SIFT (Scale Invariant Features Transform) introducido por David Lowe en 1999, es considerado una de las mejores técnicas de procesamiento de imágenes, ya que la información obtenida de la imagen se transforma en coordenadas invariantes de escala, rotación y luminosidad. Lo primero que se realiza es obtener un conjunto de puntos de la imagen, los cuales serán denominados “puntos clave”, de acuerdo con el paso por cada etapa, el número de puntos claves se irá reduciendo y quedarán los más importantes para ser usados en la comparación. Su idea principal es la transformación de la imagen a una representación compuesta de “puntos de interés”.
Esos puntos contienen la información característica de la imagen que luego son usados para la detección de muestras [8].
El algoritmo se realiza mediante 4 etapas:
Construcción de Pirámides de Scale-Space: en esta etapa se representa la imagen en diferentes escalas y tamaños. Mediante la función de diferencia gaussiana se identifican los posibles puntos de interés que son invariables a escala y orientación [9].
Localización de puntos clave: en esta etapa se localizan los puntos que se mantienen invariables en escala. Esto se realiza mediante la comparación de cada pixel con su pixel vecino. Los puntos clave son seleccionados en base a las medidas de su estabilidad [10].
Asignación de orientación: en esta en esta etapa se asigna a cada punto clave una orientación de acuerdo con las direcciones del gradiente y a la zona que rodea dicho punto [11].
Descriptor de puntos clave: esta etapa consiste en calcular un descriptor para la región de la imagen local que sea fácilmente identificable, sin embargo, tan invariable como sea posible a las variaciones restantes, tales como el cambio en la iluminación o el punto de vista 3D [12].
Durante los últimos años se han realizado trabajos relacionados con sistemas de reconocimiento de señas, como el de Ansari (2017), el cual reconoce gestos con diversas técnicas de extracción de características y máquinas de vectores de soporte como un clasificador. Propone un enfoque hibrido entre SIFT y HoG (histograma orientado de gradientes) combinados como una característica entre esas encontramos SIFT [13].
El sistema de reconocimiento y traducción del lenguaje de señas desarrollado por Raziq y Latif (2016), implemento un dispositivo USB, que tiene la capacidad de obtener una descripción precisa de la mano y su movimiento mediante la técnica de leap motion. El sistema está compuesto por módulos de comunicación, preparación. El módulo de preparación permite utilizar los datos recibidos para entrenar el sistema y el módulo de comunicación captura el movimiento y envía la información al algoritmo que permite detectar y reconocer el signo para luego convertirlo a texto [14].
Auquilla y col. (2015), realizaron el proyecto de “Reconocimiento de caracteres del alfabeto dactilológico mediante redes neuronales artificiales”, por medio de las imágenes adquiridas por una cámara digital, procesan y segmentan esta imagen de entrada mediante técnicas de tratamiento digital para luego ser enviadas a un clasificador basado en Redes Neuronales Artificiales (RNA) que permite identificar el carácter mostrado [15].
En el trabajo de Rodríguez y col. (2014), se realiza un prototipo traductor de señales manuales a texto legible utilizando una cámara Kinect. El sistema es capaz de tomar los puntos de una escena captada por medio del sensor de profundidad de Kinect, aplicar un filtro para eliminar el ruido y posteriormente mostrar el Mesh o Maya que reconstruya la imagen de la escena en 2D, estableciendo la diferencia de distancia con el cambio de color. La aplicación desarrollada en Open CV proyecta la localización de la mano y luego toma una captura del gesto manual para finalmente esta pueda ser comparada con la base de datos de los gestos y cuente con su traducción respectiva [16].
Betancur y col. (2013), proponen un sistema integrado de hardware y software para el reconocimiento de lenguaje dactilológico. El hardware consiste en un sistema inalámbrico adherido a un guante, el cual posee un conjunto de sensores que permite capturar las señales generadas por los movimientos gestuales de la mano. El software trabaja con un modelo de adaptación de redes neuronales que permite la identificación de las vocales que conforman el lenguaje de señas colombiano. Se obtuvo un resultado del 78% de reconocimiento de las vocales en el sistema integrado [17].
En el trabajo documentado en Priego-Pérez (2012), se presenta un sistema para reconocer la información contenida en imágenes del lenguaje de señas. Su autor establece dos etapas: en la etapa de reconocimiento utiliza la cámara de un dispositivo Kinect2, mediante la cual se adquiere nuevos patrones que posteriormente se comparan con los ya almacenados en la base de conocimiento del sistema durante la etapa de aprendizaje. En general, el enfoque se basa en una estimación de similitud entre la imagen adquirida y la del patrón almacenado, considerando únicamente valores de similitud que superen el 90% [18].
Chiguano y col. (2011), desarrollaron un sistema que traduce el lenguaje de señas e implementan un entrenador de este. El sistema fue desarrollado en LabView, concluyendo que el desempeño del sistema depende en gran medida de las condiciones del ambiente bajo el cual se realice la adquisición de la imagen, puesto que este último al ser controlado, arrojaba una imagen más limpia facilitando el tratamiento de la misma, pero reduciendo la flexibilidad de la aplicación para su uso en cualquier condición [19].
Kelly y col. (2010), realizaron un sistema de reconocimiento de señas en el lenguaje de señas americano. El sistema obtenía la imagen de una cámara digital para luego realizar la ubicación de la mano y segmentación de esta imagen mediante un algoritmo robusto que permitía obtener el contorno de la mano. Mediante una función de tamaño se convertía esta imagen digital en una binaria y esta información se almacenó en una matriz que contenía el contorno del gesto [20].
El trabajo de Razo-Gil y col. (2009), se considera únicamente aquellas letras que se representan en el alfabeto dactilológico sin la necesidad de ejercer movimiento, mediante un método de valor umbral para el procesamiento y segmentación de las imágenes que logra separar unos objetos de otros con el objetivo de identificar las regiones de interés de acuerdo con la postura en la que se encuentre la mano del sujeto. El objetivo de este enfoque es conseguir extraer características relevantes que se puedan medir [21].
Como se puede observar en los trabajos analizados, es importante iniciar con un tratamiento de imágenes, para luego continuar con el proceso de reconocimiento y utilización del sistema, con el fin de garantizar resultados y minimizar probabilidades de error en la aplicación diseñada [21].
2. METODOLOGÍA
En la figura 2 se muestra todas las etapas utilizadas para el diseño y la ejecución del sistema de reconocimiento de gestos no móviles. Como entorno de programación y diseño de la interfaz se utilizó Matlab, primero se realizó la captura de imágenes y la creación de la base de datos del sistema; la cual está conformada por 60 fotografías de tres patrones distintos. La captura de imágenes de prueba se da a partir de la cámara digital Canon PowerShot A4000 IS Azul, la cual nos brinda una alta calidad de las fotografías capturadas teniendo en cuenta sus 16 Megapíxeles y Zoom Óptico 8x.
La imagen de entrada del sistema es sometida a un preprocesamiento para disminuir el ruido y también se hace un cambio en las dimensiones para disminuir el costo computacional, quedando en un tamaño de 640x480 pixeles.
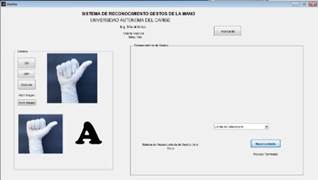
Interfaz gráfica
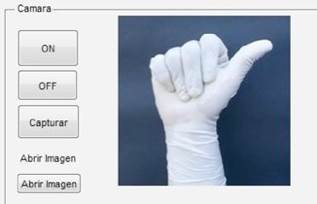
La interfaz se desarrolló por medio de GUIDE (Graphical User Interface Development Environment) del entorno de Matlab, el cual consta de una ventana, que se distribuye de la siguiente forma:
Encabezado: nombre del proyecto, estudiantes, y universidad.
Captura de Imagen: caja para la visualización de la imagen a tomar por parte de la cámara, y la cual posee los siguientes comandos:
Encender cámara: comando utilizado para que la cámara aparezca en el cuadro principal donde se encuentra el logo más grande la Universidad Autónoma del Caribe.
Apagar cámara: comando utilizado para dejar de utilizarla cámara.
Capturar: comando utilizado para realizar captura de imágenes.
Abrir imagen: comando utilizado para abrir las imágenes capturadas.
Visualización de caracteres del Lenguaje de Señas Colombiano e imagen capturada de entrada al algoritmo principal.
Visualización de imagen de salida.
Información del proyecto.

2.2 Función de reconocimiento
La función de reconocimiento recibe la imagen de entrada la convierte en escala de grises y mediante la técnica de SIFT los puntos de interés de la imagen de entrada para que estos puedan ser comparado con los puntos de interés de las imágenes que se encuentran en la base de datos del sistema, al final la función si encuentra dos imágenes con puntos de interés iguales o similares significa que ha encontrado la señal y letra correspondiente al lenguaje de señas colombiano. Si la función no encuentra ninguna relación entre los puntos de interés de la imagen de entrada y las que se encuentran en la base de datos simplemente el sistema arrojará que no ha sido posible identificar la seña y que lo intente nuevamente.
2.3 Scale Invariant Features Transform (SIFT)
SIFT es un método propuesto por David Lowe, en donde una imagen se transforma la información en coordenadas invariantes de escala y rotación. El algoritmo permite extraer puntos estables y de interés de una imagen. El conjunto de estos puntos de interés representa descripciones características que son utilizadas para identificar un objeto en otras imágenes [8].
Los puntos de interés SIFT contienen información en una región circulas de una imagen, y contienen cuatro parámetros importantes: el centro de coordenadas X e Y, la escala (radio de la región) y el ángulo de orientación expresado en radianes.
La secuencia del cálculo de los puntos de interés SIFT es dividida en 6 etapas:
Construcción de un espacio de escala: una imagen con varios detalles incluye mucha información que debe reducirse; para ello, se utiliza un conjunto de operaciones como: suavizado Gaussiano, generación de octavas de la imagen (reducir el tamaño en un octavo) y aplicación del suavizado en las octavas. Los conjuntos de nuevas imágenes son utilizados en la siguiente etapa.
Aproximación del método LoG (Laplaciano Gaussiano): los puntos de interés SIFT se encuentran principalmente en los bordes y esquinas de una imagen, que a su vez pueden obtenerse tras aplicar el Laplaciano Gaussiano a la imagen suavizada; no obstante, este proceso es costoso computacionalmente. Lowe [8] demostró que el Laplaciano Gaussiano puede aproximarse a la Diferencia de Gaussianos de dos imágenes obtenidas a partir de la reducción de Octavas de una misma imagen. De este modo, se consigue un conjunto de puntos de interés iniciales invariantes a los cambios de escala.
Detección de los puntos de interés: se obtienen los puntos de interés a partir de los máximos y mínimos de la Diferencia de Gaussianos. Lowe [8] propone buscarlos alrededor de los 26 vecinos de un pixel a partir de la segunda imagen de Octava, ya que es la primera imagen en la que los 26 vecinos existen.
Eliminación de puntos de interés con características de bajo contraste y ubicados en esquinas: consta de dos posibles criterios de eliminación: El primero consiste en que, si la magnitud de la intensidad de un pixel en el DoG es menor a determinado valor, es rechazado. El segundo calcula los valores de dos gradientes perpendiculares en un punto de interés, si las gradientes son pequeñas (región plana), o si una es grande y la otra pequeña (borde) son eliminadas.
Asignación de la orientación para los puntos de interés: en esta etapa se asigna una orientación a los puntos de interés anteriores para otorgarles la propiedad “Invariancia a la Rotación”. Se calcula la dirección y la magnitud de las gradientes de cada punto de interés, se forma un histograma de orientación, y la orientación más prominente de la región es asignada al punto de interés.
Generación de las características SIFT: finalmente, con la rotación y escala invariantes, se realiza una última representación que facilite la identificación de las características de los puntos de interés [22].
3. RESULTADOS Y DISCUSIÓN
En esta sección se comparten los resultados obtenidos durante el proceso de creación, organización, elaboración e implementación del proyecto.
3.1 Recolección de base de datos
Realizamos la base de datos teniendo en cuenta únicamente las 20 señas no móviles del lenguaje de señas colombiano. Todas las señas fueron realizadas con la mano derecha por 4 personas diferentes, cada seña fue fotografiada en fondo negro 3 veces. Por lo tanto, cada persona aportó 60 imágenes que formaron parte de nuestra base de datos.
En nuestra primera base de datos se realizó la captura de la mano derecha sin importar la tez del color de piel, sin embargo, se determinó que era necesario regular esta variable y por esto se realizó una segunda base de datos con la captura de las señas usando un guante quirúrgico de color blanco.
Las imágenes se guardaron en formato de archivo “.jpg”. Las imágenes contenidas en la base de datos son: A, B, C, D, E, F, I, K, L, M, N, O, P, Q, R, T, U, V, W, Y.
3.2 Sistema de reconocimiento
Durante la realización de pruebas al sistema de reconocimiento de gestos no móviles del lenguaje de señas colombiano, se ejecuta inicialmente el algoritmo principal, en el cual se encuentra el código desarrollado para la Interfaz de Usuario y en el que a su vez se lee la imagen de entrada que puede estar guardada en el ordenador, o capturada por medio de la cámara del mismo con dimensiones 640x480.
Una vez elegida la imagen, ésta se despliega en la parte superior de la interfaz, como se observa en la figura 5.
Posteriormente se ejecuta el proceso de reconocimiento, pulsando un botón llamado de la misma forma “Reconocimiento”, con el fin de encontrar los puntos claves o característicos de la imagen de entrada y las imágenes que se encuentran en la base de datos, y realizando una comparación donde se determina cuál es la imagen encontrada en la base de datos que se asocia a la imagen ingresada al sistema.
3.3 Resultado sistema reconocimiento: prueba 1
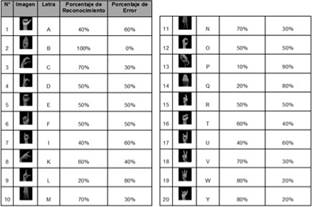
En la primera prueba se realizó la captura de las señas sin cubrir la mano con ningún elemento. Tres personas de diferente tez realizaron todas las señas no móviles del lenguaje de señas colombianos tres veces para el reconocimiento de la misma. La prueba fue realizada utilizando la cámara que se encontraba en el ordenador y el fondo de la imagen de entrada era negra iluminado con luz natural todas las capturas fueran realizadas mediante los mismos parámetros.
El porcentaje de error en esta primera prueba fue de un 54%, las señas no estaban siendo reconocidas satisfactoriamente, las condiciones de iluminación y el color de tez de la piel de los participantes afecto la fiabilidad del sistema. Solamente fueron reconocidas con un porcentaje del 70% o mayor las letras B, C, M, N, V, W, Y. En la figura 7, se encuentran documentados el porcentaje de reconocimiento y error de cada seña.
3.4 Resultados sistema de reconocimiento: prueba 2
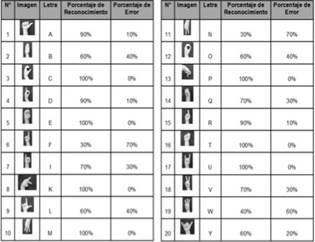
Durante la segunda prueba se capturaron imágenes utilizando un guante quirúrgico, con el fin de estandarizar el sistema, para minimizar los errores arrojados en la primera prueba. Tres personas de diferente tez realizaron todas las señas no móviles del lenguaje de señas colombianos tres veces para el reconocimiento de la misma. La prueba fue realizada utilizando la cámara que se encontraba en el ordenador y el fondo de la imagen de entrada era negro, las condiciones de luz eran las óptimas y todas las pruebas fueran realizadas mediante estos mismos parámetros. Los resultados obtenidos arrojaron un porcentaje de fiabilidad del 77%, en esta prueba las señas de las letras A, C, D, K, M, P, R, T, U obtuvieron un porcentaje de reconocimiento mayor del 90% incluso algunas reconocidas en su totalidad. En la figura 8, se encuentran documentado el porcentaje de reconocimiento y error de cada seña para la segunda prueba.
3.5 Análisis comparativo
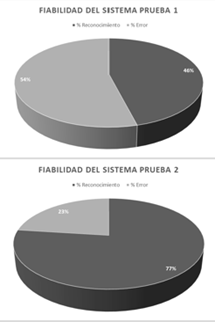
Los sistemas que implementan procesamiento de imagen digital requieren que la captura de las imágenes tenga condiciones de ambiente adecuado, en la primera prueba se utilizó luz natural, este factor y además el realizar las señas sin tener en cuenta la tez de la piel disminuyó la eficiencia del sistema de reconocimiento de señas no móviles. En la primera prueba se obtuvo un porcentaje de éxito del 54% el sistema solamente identificaba la mitad de las señas.
En la segunda prueba se utilizó una luz blanca frontal para iluminar correctamente las señas a realizar y además la mano se cubrió con un guante de color blanco. Al implementar estos dos cambios se obtuvo un porcentaje de éxito de 77%, las señas de las letras A, C, D, E, I, K, L, M, O, P, Q, R, T, U mejoraron su porcentaje de fiabilidad en comparación a la primera prueba; solo las señas de las letras B, F, N, W, Y mostraron una disminución en el proceso de reconocimiento.
4. CONCLUSIONES
Actualmente, la implementación de aplicaciones utilizando el procesamiento digital de imágenes es de gran auge, debido al sin número de análisis que se pueden realizar por medio de la captura de imágenes o videos, para solventar distintas necesidades.
El algoritmo de reconocimiento se encarga de extraer características intrínsecas de las imágenes de entrada y base de datos, que resulten ser claves al momento de realizar la comparación que permita determinar la señal correspondiente al Lenguaje de Señas Colombiano. Además, se encarga de recibir una imagen de una señal del Lenguaje de Señas Colombiano dada por el usuario, y hallar con el mejor grado de certeza posible, en una base de datos.
Para el reconocimiento preciso y fiable, las características extraídas de la imagen de entrada deben ser detectables incluso en los cambios en la escala de la imagen, el ruido y la iluminación. Se encuentra una mejor respuesta del sistema, con la utilización de un elemento que estandarice la mano con respecto a los factores de color, utilizando un guante, en este caso, tipo quirúrgico. Las condiciones de luz deben ser adecuadas para obtener un resultado preciso.

