










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkRevista EIA
Print version ISSN 1794-1237
Rev.EIA.Esc.Ing.Antioq no.25 Envigado Jan./June 2016
APLICACIÓN DE MAPAS DE KOHONEN PARA LA PRIORIZACIÓN DE ZONAS DE MERCADO: UNA APROXIMACIÓN PRÁCTICA
APPLICATION OF KOHONEN MAPS FOR THE PRIORITIZATION OF MARKET AREAS: A PRACTICAL APPROACH
APLICAÇÃO DE MAPAS DE KOHONEN PARA A PRIORIZAÇÃO DE ÁREAS DE MARCADO: UMA APROXIMAÇÃO PRÁTICA
Harol Mauricio Gámez Albán1, Juan Pablo Orejuela Cabrera2, Óscar Ancízar Salas Achipiz3, Juan José Bravo Bastidas4
1 Ingeniero Industrial, Universidad del Valle, Investigador en LOGYCA / INVESTIGACIÓN. Avenida el Dorado # 92-32, Torre 5, Piso 5, Bogotá, Colombia: / Tel.: (4) 314 637 73 02. Correo electrónico: hgamez@logyca.org.
2 Magister en Ingeniería Industrial, Universidad del Valle, Profesor Asistente en Universidad del Valle.
3 Ingeniero Industrial, Universidad del Valle, Coordinador, Coomeva.
4 Doctor en Ingeniería Industrial, Universidad del Valle, Profesor Asistente en Universidad del Valle.
Artículo recibido: 12-V-2015 / Aprobado: 02-VI-2016
Disponible online: 30 de octubre de 2016
Discusión abierta hasta octubre de 2017
RESUMEN
Este artículo presenta una metodología basada en redes neuronales para realizar priorización de zonas de mercado visto desde un enfoque empresarial. En esta investigación se intenta dar solución a la incertidumbre que existe en la mayoría de las organizaciones en torno a la prioridad que tiene una zona de mercado; para ello se hace una búsqueda de los criterios más relevantes que las empresas tienen en cuenta para asignar prioridades a ciertos clientes. La problemática se sustenta por la ausencia de herramientas que permitan determinar la prioridad de una zona de mercado y la falta de una interrelación efectiva entre los departamentos de logística y mercadeo. Para ello se ocupan los mapas de Kohonen que son un tipo de red neuronal que facilita el agrupamiento de clientes y permiten determinar cuáles de ellos son los que impactan con mayor frecuencia los criterios de priorización previamente establecidos. Finalmente, se presentan tres escenarios con fin de validar la propuesta formulada y ver qué comportamiento tienen las redes neuronales en temas de priorización de zonas de mercado.
PALABRAS CLAVE: redes neuronales; mapas de Kohonen; zonas de mercado; logística; mercadeo.
ABSTRACT
This paper introduces a methodology based on neural networks to prioritize some market areas with a business approach. In this research, we try to resolve the uncertainty that exists in most organizations around the priority of a market area by conducting a search of the most relevant criteria businesses consider in order to assign priorities to certain clients. The problem is sustained by a lack of tools to estimate the priority of a market area and by the lack of an effective interface between logistics and marketing departments. To address this situation, we used Kohonen maps, a type of neural network that facilitates customer grouping and makes it possible to determine which of them most frequently impact the previously established priority criteria. Finally, three scenarios are proposed to validate the proposal made and see what behavior the neural networks have in terms of prioritizing marketing areas.
KEY WORDS: Neural networks; Kohonen maps; Market areas; Logistics; Marketing.
RESUMO
Este artigo apresenta uma metodologia baseada em redes neurais para a priorização de áreas de mercado visto desde uma abordagem empresarial. Nesta pesquisa tenta-se resolver a incerteza que existe na maioria das organizações em torno à prioridade de uma área de mercado; para fazer uma pesquisa dos critérios mais importantes que as empresas têm em conta para atribuir prioridades a certos clientes. A questão se suporta pela falta de ferramentas para determinar a prioridade de uma área de mercado e da falta de uma interface eficaz entre logística e departamentos de marketing. Para isto se fazem os mapas de Kohonen que são um tipo de rede neural para facilitar o agrupamento de clientes e permitir- lhes determinar quais são os critérios que impactam mais frequentemente os critérios de priorização previamente estabelecidos. Finalmente, apresentam-se três cenários para validar a proposta e ver que o comportamento tem as redes neurais nas áreas de priorização de áreas de marketing.
PALAVRAS-CHAVE: Redes neurais; Mapas de Kohonen; Áreas de mercado; Logística; Marketing.
1. INTRODUCCIÓN
La importancia de la logística para la competitividad de las empresas ha hecho que se vean en la necesidad de establecer indicadores para medir el comportamiento de aquellas variables que directa e indirectamente tienen repercusión sobre ellas, además los cambios en el entorno de los negocios ocasionan que las empresas vean la necesidad de medirse en el campo logístico con el fin de diseñar estrategias competitivas que les permitan contrarrestar dichos cambios en los negocios. Dado lo anterior, las empresas deben estar preparadas mediante estrategias comerciales para mantener sus mercados, pues hoy en día es de vital importancia que las organizaciones tengan en cuenta dentro de sus planes de mercadeo criterios logísticos como una herramienta para mejorar su competitividad.
Desde el punto de vista de mercadeo las variables clásicas que normalmente intervienen y que ayudan a contrarrestar los cambios son: Precio: entendido como el valor de intercambio del producto, el cual está determinado por la utilidad o la satisfacción derivada de la compra; Plaza: elementos que permiten conseguir que un producto llegue satisfactoriamente al cliente; Producto: cualquier bien, servicio, idea, lugar, organización o institución que se ofrezca en un mercado para su adquisición, uso o consumo y que satisfaga una necesidad; Promoción: La forma como la empresa determinara la comunicación con el cliente.
Estas variables permiten a las empresas tener un buen indicador para medir sus niveles de competitividad, lo que obliga al área logística a estar atenta a dichas variables para establecer y programar sus despachos de manera oportuna, en el momento adecuado, en el lugar indicado, al costo adecuado, en las manos del cliente final y satisfaciendo plenamente sus necesidades, surgiendo así la necesidad de generar para las compañías criterios que les permitan medir la prioridad que tiene cada una de sus zonas geográficas de mercado.
Hasta el momento se puede decir que no se ha trabajado de manera directa en priorización de zonas de mercado, pero se han desarrollado estudios que buscan, mediante herramientas matemáticas y/o estadísticas, describir el comportamiento de los clientes para que faciliten el proceso de toma de decisiones.
Teniendo en cuenta lo anterior, se pueden destacar varios trabajos que tratan de acercarce a al estudio de clientes, y por ende, la priorización de zonas de mercado como es el de Kiang y Kumar (2001) que ocupan los mapas de Kohonen para encontrar clústers dentro de un conjunto de datos llegando a buenos resultados cuando se requieren hacer trabajos en minería de datos con este tipo de herramientas. Curry et al. (2001) también implementan los mapas auto-organizados para clasificar los grupos de clientes en la industria hotelera, tratando de encontrar correlaciones entre los clientes y el rendimiento de los hoteles. Estos mismos Curry et al. (2003) hacen un análisis general del proceso de segmentación de mercados y análisis de clústers ocupando mapas de Kohonen, y muestran las ventajas de ocupar este tipo de red neuronal en comparación con otros métodos tradicionales de segmentación.
El estudio realizado por Chul y Ho (2004)presenta una segmentación del mercado de los videojuegos usando mapas auto-organizados, se convierte en uno de los primeros estudios en hacer un acercamiento formal a la priorización de zonas de mercado, puesto que utilizan la segmentación como herramienta para determinar la ubicación de los clientes con ciertas características y centran las estrategias de mercadeo sobre estos segmentos para determinar cierto grado de importancia de cada uno de los segmentos. Aunque el objetivo del estudio es identificar las características del mercado de los videojuegos en Japón y Corea del Sur, en este estudio se identifican los segmentos de edad, género, estudios y una gran cantidad de características de los clientes de este mercado, mediante el uso de los mapas autoorganizados para segmentar de manera eficiente y reducir el impacto que presentan los datos atípicos generados por analizar dos países diferentes. Nuevamente Kiang y Kumar (2004) realizan una comparación entre los mapas de Kohonen y el algortimo k-means para realizar segmentación de mercados, obteniendo que los SOM (Self Organizing Map) presentan mejores resultados en todos los casos y escenarios evaluados. Kuo et al. (2006) en su investigación presentan una metodología para identificar las características de ciertos grupos de clientes de una zona determinada y el proceso de agrupación en subgrupos con características particulares.
Un estudio un poco más cercano al de priorización de zonas es el realizado por Bravo, Orejuela y Osorio (2007) en el que se abordan algunos indicadores para medir la priorización en transporte y en el que se plantea la necesidad de establecer algunos indicadores en priorización de zonas de mercado. De manera similar, Montoya (2007) realiza segmentación de clientes por intermedio de análisis de factores, lo cual permite validar datos construidos a raíz de un estudio previo de mercado mediante la incursión de matrices con (n) variables y (k) factores. Esto se hace con el fin de reducir el número de variables que se pueden encontrar en el análisis de las zonas de mercado y así facilitar el estudio. Finalmente, se obtiene una clasificación de clientes de acuerdo a unas características identificadas en la investigación de mercado, facilitando de esta manera la toma de decisiones por parte de los departamentos de mercadeo.
Por otro lado, Bigné et al. (2010) hacen una comparación entre las redes neuronales y los métodos tradicionales para hacer un acercamiento a la segmentación de mercados resaltando la superioridad de los SOM sobre la clusterización jerárquica para hacer segmentación. Soldic-Aleksic (2012) propone la combinación de dos modelos de minería de datos para hacer segmentación de mercados, para ello utilizan los mapas de Kohonen y árboles de decisión donde el primero de ellos se ocupa para visualización y clusterización, mientras que el segundo lo ocupa para tener una mejor visualización desde el punto de vista estadístico alcanzando resultados favorables con la combinación de ambos métodos.
Seret, Verbraken y Baesens (2014) implementan un nuevo método para realizar clusterización de clientes que directamente repercuten en decisiones de mercadeo. Los autores proponen un método de priorización de variables que, según sus atributos, permiten entender las diferencias de ciertos clientes. Meschino et al. (2015), plantean el uso de datos fuzzy para clusterización de datos mediantes los mapas auto-organizados llegando a conclusiones importantes en el campo, dado que los datos normalmente tienen un comportamientos estocástico y no siempre son determinísticos.
Finalmente, la mayoría de los estudios que existen a la fecha se basan principalmente en segmentación de mercados utilizando diversas herramientas y metodologías para facilitar la toma de decisiones, mientras que para el caso de priorización de zonas de mercado existen solo aproximaciones y sugerencias, de la importancia de tener en cuenta un criterio de priorización de zonas de mercado para la toma decisiones en cuanto a asignación de recursos.
Lo anterior da una clara muestra de la necesidad de diseñar una metodología para la priorización de zonas de mercado; es por eso que en este estudio se presenta una metodología que en cierta medida trata de dar solución a la problemática de encontrar una herramienta para la priorización de zonas de clientes. En la sección 2 se presenta todo el marco teórico de la herramienta ocupada para realizar el proceso de priorización; en la sección 3 se muestra el caso estudio; en la sección 4 se presentan los resultados y hallazgos más relevantes y, finalmente, en la sección 5 se presentan los conclusiones.
2. MARCO TEÓRICO
2.1. Redes neuronales
Las redes neuronales están encargadas de obtener los pesos ponderados que permiten medir la importancia que tienen los distintos criterios de priorización dentro de las zonas de mercado, y así poder, de alguna manera, emular el comportamiento de dichas zonas.
Para el desarrollo de la metodología se presenta una breve descripción de las redes neuronales y el comportamiento que muestra tanto en el ámbito biológico como en la aplicación en el área de mercadeo y logística. El mapa auto-organizado es la herramienta visual que emplean las redes neuronales para visualizar el comportamiento de acuerdo a los pesos ponderados. Finalmente, se encuentra un caso de estudio donde se someten a análisis tres escenarios con sus respectivos resultados computacionales simulados en Matlab.
Según Caicedo y López (2009) las redes neuronales artificiales (RNA) surgen como un intento para emular el funcionamiento de las neuronas de nuestro cerebro. En este sentido las RNA siguen una tendencia diferente a los enfoques clásicos de la inteligencia artificial que tratan de modelar la inteligencia humana buscando imitar los procesos de razonamiento que ocurren en nuestro cerebro.
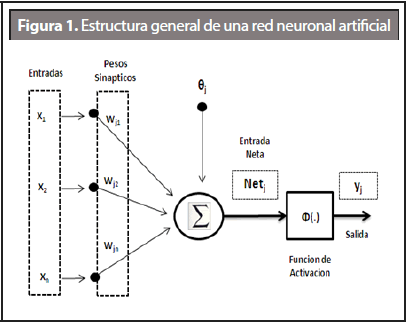
La estructura clásica de una red neuronal se puede apreciar en la Figura 1, donde el vector de entrada se define como X = [x1, x2,..., xn]. La información recibida por la neurona es modificada por un vector de pesos sinápticos cuyo papel es de emular la sinapsis existente entre las neuronas biológicas. El parámetro θj se conoce como el bias o umbral de una neurona, y finalmente el parámetro yj es la salida o resultado final de la red neuronal.
2.2. Mapas auto-organizados de Kohonen
Los mapas Auto-Organizados (SOM, por su nombre en inglés Self-Organizing Maps) fueron presentados por Teuvo Kohonen en 1982, por lo que también reciben el nombre de Mapas Auto-organizados de Kohonen o Redes Neuronales de Kohonen, estos mapas están inspirados en la capacidad del cerebro humano de reconocer y extraer rasgos o características relevantes del mundo que los rodea (Caicedo y López, 2009).
La idea básica del SOM es crear una imagen de un espacio multidimensional de entrada en un espacio de salida de menor dimensión. Se trata de un modelo de dos capas de neuronas, como se observa en la Figura 2. La primera capa de entrada y la segunda de procesamiento. Las neuronas de la capa de entrada se limitan a recoger y canalizar la información. La capa de salida o procesamiento está ligada a la capa de entrada a través de los pesos sinápticos de las conexiones.
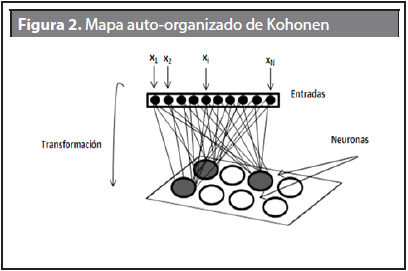
El mapa auto-organizado de Kohonen está constituido por dos niveles de neuronas, el de entrada y el de salida. Pero solo en el nivel de salida se genera procesamiento de información, por lo que recibe el nombre de capa de salida, y la red pertenece al tipo monocapa. La conectividad es total, es decir, todas las neuronas de la capa de salida reciben los estímulos de las neuronas de entrada.
El aprendizaje en el modelo auto-organizado de Kohonen está regido por la Ecuación 1 que define la variación de los pesos δwr en este algoritmo, en donde la neurona ganadora y sus vecinas, modifican su vector de pesos sumándole una fracción de la distancia existente entre el vector de entrada y el vector de pesos en el instante t del algoritmo.
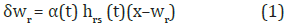
Donde x es el vector de entrada, δwr es la variación del vector de pesos para la neurona r-esima, α(t) tasa de aprendizaje, hrs (t) es la función de vecindad, wr es el vector de pesos de la neurona r-esima y t el índice de iteración.
En una red neuronal las conexiones entre neuronas tienen un determinado peso wr , el cual tiene como función principal de atenuar o amplificar los valores que se desean propagar hacia la neurona. La tasa de aprendizaje α(t) se calcula con base en la Ecuación 2, donde αf y αi corresponden a las tasas de aprendizaje final e inicial respectivamente; tmax es el número máximo de iteraciones.
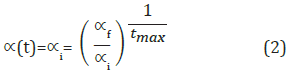
Con esta expresión lo que se busca es que la tasa de aprendizaje siga una función exponencial con el fin de tener al inicio del proceso fuertes variaciones en los pesos y, a medida que avance el proceso, las variaciones disminuyan para así garantizar que al inicio del proceso las neuronas se distribuyan lo más rápido posible entre los datos representativos de la base de entrenamiento.
La función de vecindad se define con la Ecuación 3, donde d es la distancia euclidiana entre la neurona ganadora (s) y la neurona (r) a la cual se le modifican los pesos. El rango de vecindad σ(t) es variable y se define con la Ecuación 4, donde σi y σf corresponde a los rangos de vecindad inicial y final respectivamente.
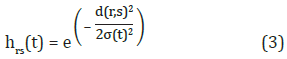
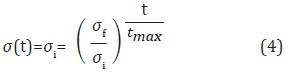
Una neurona será ganadora cuando su distancia euclidiana hacia el vector de entrada, (para este caso los valores de criterios de priorización) sea la mínima. La Ecuación 5 muestra el resultado.

La vecindad es una función exponencial, cuya característica hace que las neuronas más alejadas de la unidad ganadora se vean afectadas en sus pesos sinápticos en menor proporción que las más cercanas.
En resumen, los mapas de Kohonen son un tipo de red neuronal no supervisado donde no hay un patrón de entrenamiento para los datos de entrada, a diferencia de las redes supervisadas que sí poseen ese patrón o maestro de entrenamiento para los datos de entrada.
2.3. Criterios de priorización
Para estimar la prioridad de una zona de mercado se definen los siguientes criterios de priorización con base en el trabajo de campo, donde se entrevistó a diferentes tipos de expertos que trabajan en logística y mercadeo; adicional, fueron entrevistados expertos académicos (logística y mercadeo) que desde el punto de vista de la academia hicieron su aporte para la selección de los criterios de priorización. Los criterios resultantes fueron los siguientes:
- Demanda promedio (por los diferentes sku's)
- Inventarios de seguridad promedio (stock's de seguridad)
- Lead time: tiempo de tránsito
- Nivel de participación de la empresa en las zonas (según la distribución de la demanda clasificadas por zonas)
- Permanencia en la zona (tiempo total que lleva la compañía atendiendo dicha zona de mercado)
- Implantación de la competencia en la zona (número de compañías que atienden esa zona con productos similares y/o sustitutos)
- Distancia al centro de distribución (qué tan distante es la zona de mercado al centro de distribución más cercano de la compañía).
2.4. Algoritmo de simulación
Teniendo identificados los criterios finales de priorización, se diseña el caso estudio para 3 zonas geográficas. Se generan valores aleatorios comprendidos entre una serie de rangos (máximo y mínimo) para cada uno de los criterios definidos, y a su vez se replica para los tres escenarios ya preestablecidos.
El algoritmo del mapa de Kohonen se compone de los siguientes 6 pasos:
- Se define la arquitectura de la red, con N neuronas en la capa de entrada y M neuronas en la capa de salida. A su vez se definen aleatoriamente los parámetros de control: σi, σf, αi, αf y tmax.
- Se selecciona un vector de entrada X = [x1, x2,..., xn] aleatoriamente, tal que pertenezca al conjunto de patrones de entrenamiento.
- Se determina el índice de la neurona ganadora s con base en la mínima distancia entre el vector de entrada y los vectores de pesos de las neuronas. s = min (x - wi).
- Se modifican los pesos de la neurona r - ésima de acuerdo con δwr = α(t) hrs (t)(x - wr):
- Se incrementa el parámetro t
- Si t < tmax se retorna la paso 2
La red neuronal de Kohonen se programa en el ambiente de computo Matlab, haciendo uso de la aplicación de redes neuronales de los toolboxes.
3. CASO DE ESTUDIO
Para el caso de estudio se debe decidir cuál de las (n) zonas de mercado que tiene una empresa puede ser la más prioritaria en un periodo determinado, de tal manera que se logre administrar y asignar de manera más eficiente los recursos de distribución (entiéndase por recursos de distribución: personal, bodegas, sistemas de comunicación, camiones de carga, etc.).
Con base en estos criterios seleccionados se realiza el caso estudio bajo los siguientes supuestos y condiciones:
- Se utilizan los 7 criterios de priorización mencionados anteriormente.
- Se considera 3 zonas geográficas y que se denominan con las letras A, B y C. Cada una con características específicas.
- Para el criterio de demanda, se considera la demanda total promedio de los clientes que hacen parte de las 3 zonas geográficas.
- Se considera el inventario de seguridad promedio por parte de los clientes ubicados en las tres zonas geográficas.
- Para el tiempo de reposición, se considera el tiempo que existe desde que la carga sale del CD del proveedor hasta la llegada al cliente final ubicado en cualquiera de las 3 zonas geográficas.
- El criterio nivel de participación hace referencia al (%) total de participación que tiene el proveedor en cada una de las tres zonas geográficas.
- El criterio zona potencial, se maneja como el potencial total de demanda que existe en la zona.
- La permanencia en la zona, hace referencia al tiempo que lleva el proveedor distribuyendo los productos en cada una de las tres zonas.
- Para el criterio de fletes, se asume que el proveedor es quien costeará el 100% del flete. Para este caso el valor de este criterio estaría asociado a la cantidad de carga y al total de distancia que existe entre el proveedor y el cliente final.
- En total se manejan 50 clientes por cada zona, o sea que se tienen 150 clientes por las 3 zonas geográficas.
- Para generar cada uno de los valores se utiliza la herramienta de Excel que obtiene valores aleatorios según el rango mínimo y máximo dado a cada criterio para cada zona geográfica.
- Se define un caso hipotético de rango de valores para cada uno de los 7 criterios, partiendo del supuesto que dichos valores deben estar inicialmente en conflicto, es decir que el valor de los criterios no debe evidenciar una preferencia inmediata de una zona frente a las demás.
Se hizo un estudio de campo por medio de encuestas detalladas, donde se le preguntó a expertos (personas que trabajan en roles logísticos y de mercadeo) cuáles de los criterios de priorización son más relevantes al momento de definir la prioridad de una zona de mercado. La encuesta consistía en un par de preguntas específicas que conllevaban a la determinación del porcentaje de participación de cada criterio de priorización según el rol donde se encontraba el experto. También, se realizó un estudio estadístico que dio como resultado un número determinado de encuestas a realizar para que la muestra fuese significativa. La Tabla 1 muestra los resultados consolidados de las encuestas realizadas.
3.1. Escenario 1: caso en conflicto
En este escenario se muestra el caso en conflicto de criterios, donde visualizar la zona prioritaria a simple vista sea imposible de determinar. En la Tabla 2 se presentan los rangos de valores que tiene cada uno de los 7 criterios para las 3 zonas de mercado.
3.2. Escenario 2: variación demanda e inventarios
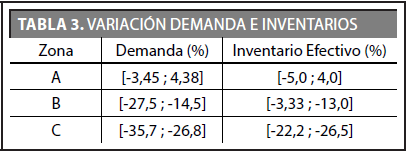
En este escenario se pretende ver cuánto podrían variar los resultados finales, en caso de modificar los valores de demanda e inventarios, conociendo de antemano que estos criterios tienen un peso del 25% y el 15% respectivamente en la elección de la zona prioritaria.
La Tabla 3 presenta los cambios efectuados en los criterios mencionados, luego el resto de los criterios quedan igual como en el escenario 1.
3.3. Escenario 3: variación lead time y fletes
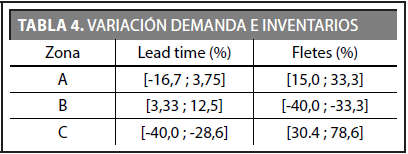
Este escenario es similar al anterior, pero en este caso los criterios que se modifican son lead time y fletes, los cuales tienen pesos porcentuales de 16% y 20% que corresponden al segundo y tercer criterio en orden de importancia para la decisión final de priorización.
La Tabla 4 muestra la variación porcentual que presenta cada criterio y, como en el caso anterior, el rango de valores para los 5 criterios restantes continúa igual como en el caso en conflicto.
4. RESULTADOS
La red neuronal se programa en Matlab, y procesa y emite dos resultados primordiales: un mapa auto-organizado y un mapa con el análisis de planos. A continuación se muestra cada escenario en particular y su correspondiente análisis de priorización.
4.1. Resultados escenario 1: caso en conflicto
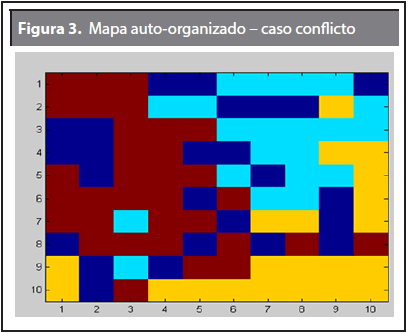
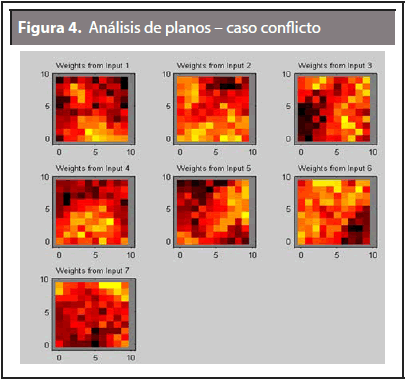
Los resultados de la red neuronal programada en Matlab normalmente arrojan dos resultados principales mostrados en las Figuras 3 y 4. La primera de ellas (Figura 3) presenta la visualización de las categorías detectadas por el mapa auto-organizado, es decir las tres zonas de mercado (es una representación en un plano de las zonas de mercado en estudio); mientras que la Figura 4 corresponde al análisis de planos para las diferentes entradas que se utilizan, que para este caso son los siete criterios de priorización. Los resultados de esta figura muestran la intensidad que tiene cada criterio de priorización en el mapa auto-organizado (zonas de mercado). Entre más oscuro, más intenso es dicho criterio sobre la zona que recae. Por ejemplo, el criterio número 4 tiene un alto grado de intensidad sobre la zona roja según la Figura 3.
Para validar la muestra y parte de los resultados de cada escenario se realizaron 20 réplicas uniformemente distribuidas según los rangos donde se mueven los valores de los criterios de priorización, mientras que para el caso de enteramiento y validación de resultados se utilizó el mismo conjunto de datos. En todos los escenarios, y para mayor facilidad en la consecución de los resultados, la topología de las redes utilizadas fue de 10 x 10 para un total de 100 neuronas en cada caso.
El resultado de la Figura 3 indica que la zona A (Azul claro) se ubica en la parte superior derecha del mapa, la zona B (Amarillo) se ubica en la parte inferior derecha del mapa, y la zona C (Roja) está en la parte izquierda del mapa, y finalmente el color azul oscuro indica las neuronas que no encontraron patrón alguno y por ende no lograron activarse. Para este caso hay algunas neuronas que se activaron pero quedaron fuera de la zona asignada, como es el caso de la zona B que tiene dos neuronas ubicadas en la parte inferior izquierda.
La Figura 4 indica la intensidad del criterio de priorización en la representación final del mapa auto- organizado, donde dicha intensidad indica mayor participación o mayor relevancia del criterio dentro de la zona de mercado. El criterio establecido para calificar los resultados de intensidad de los mapas se hace con una escala de 1 a 5 (definida a priori para estimar las calificaciones); en este caso entre más intensidad tenga el criterio su calificación será mayor.
La Tabla 5 en su primera columna muestra el peso que tiene cada criterio (tomados de la Tabla 1 anterior), luego se tiene la calificación que obtuvo cada criterio en cada una de las zonas de acuerdo a las Figuras 3 y 4. Siguiente a esto se indica el peso ponderado que corresponde al producto del peso por la calificación para luego hacer la suma por zona y obtener el total por cada una.
El dato de 3,2 que obtuvo la zona A en el criterio de demanda viene dado por la intensidad intermedia que presenta la primer cuadrícula de la Figura 4 sobre el mapa auto-organizado (Figura 3); esta intensidad intermedia (es el valor medio de la escala 1 a 5, es decir 3) que se presenta por el color amarillo del criterio de demanda sobre el total de la zona A. El valor de 3,2 se determina por el hecho de que el color amarillo en esa cuadrícula está tomando una tonalidad amarilla tendiendo a rojo. De esta manera se hace lo mismo para las zonas B y C y para el resto de los seis criterios de priorización.
En la Tabla 5 se observa que la zona C obtuvo una calificación final de 3,9 que corresponde a la calificación más alta, por consiguiente se concluye que dicha zona es la más prioritaria para este escenario. La ubicación de dicha zona en la primera parte del mapa fue debido en gran parte por el criterio de Fletes, el cual permitió que la mayoría de las neuronas ubicadas en dicha región se activaran inmediatamente tratando de representarlas por su mayor acercamiento al dato central.
Validando un poco los resultados acerca de la selección de la zona C como la zona prioritaria, se debe a que dicha zona presentaba los datos más intermedios de las tres zonas, es decir, no era ni tan alto ni tan bajo en la mayoría de los criterios de priorización. Aunque era el escenario en conflicto, esas pequeñas diferencias que tenían las otras dos zonas afectaron para que su prioridad no fuese tan marcada como el de la zona C.
4.2. Resultados escenario 2: variación demanda e inventarios
Los resultados principales para este escenario se pueden apreciar en las Figuras 5 y 6 y en la Tabla 6.
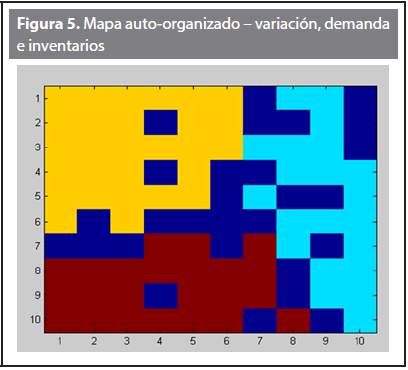
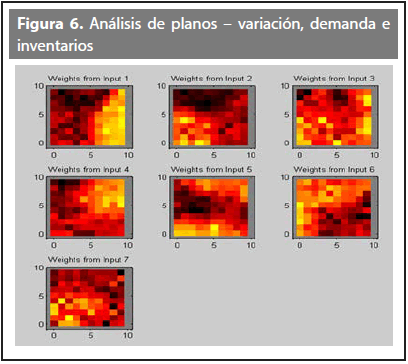
En la Tabla 6 se puede observar que la prioridad recae sobre la zona A con un peso ponderado de 3,5 el cual se debe en gran parte al resultado de 0,75 que le da el criterio de demanda. A diferencia del escenario anterior donde la prioridad recayó sobre la zona C, aquí se ve que los cambios realizados en la demanda e inventarios jugaron un papel importante para que la prioridad se trasladara a la zona A.
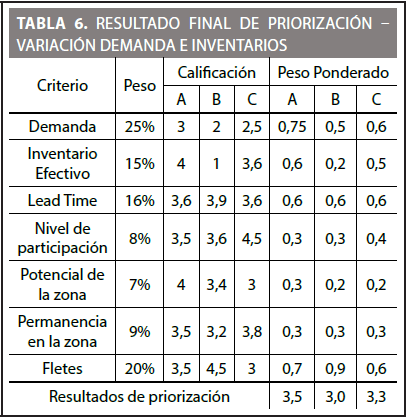
Para este escenario el criterio que más influyó en la ubicación final de las zonas fue nivel de participación, generando una calificación promedio 3,86, mientras que el criterio que menos peso generó para la ubicación de las zonas fue la demanda con una calificación promedio de 2,5.
Parte de la conclusión final del porqué se escogió la zona A como zona la prioritaria, es porque dicha zona fue la que tuvo mayor variación positiva en el criterio de demanda, logrando moverse más del 4% hacia adelante, mientras que las otras dos zonas no tuvieron aumentos positivos en este criterio. Por otro lado, aunque dicha zona no fue la mayor beneficiada con las variaciones en los inventarios, se puede concluir que el peso que tiene el criterio de demanda es mucho más relevante como para hacer inclinar las decisiones de prioridad hacia cierta región y/o zona de mercado.
4.3. Resultados escenario 3: variación lead time y fletes
Los resultados principales para este escenario se pueden apreciar en las Figuras 7 y 8 y en la Tabla 7.
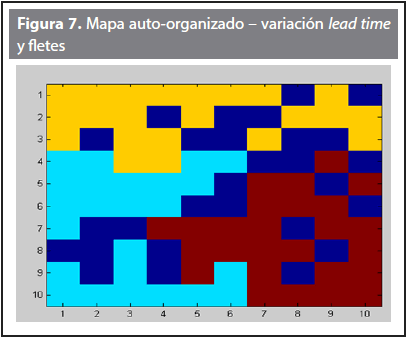
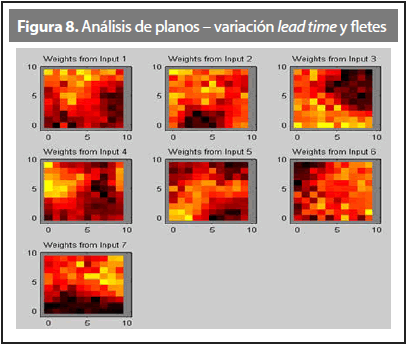
La Tabla 7 indica que en este escenario la prioridad recae sobre la zona A, con un valor de peso ponderado de 3,4. En términos de los criterios más representativos en este caso, puede decirse que son el de demanda y fletes con valores de 0,88 y 0,84, pues son los que mayor beneficio aportan para la zona A. Las zonas B y C obtuvieron valores muy cercanos entre sí (2,9 y 3,1), posiblemente porque las neuronas que logró activar la zona B inmediatamente activaron las neuronas vecinas a la zona C, o viceversa.
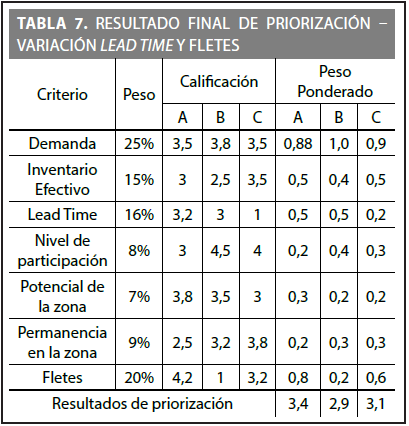
Detallando los criterios que variaron, se observa que el lead time no generó buenos resultados para las tres zonas en general, donde tan solo la zona A alcanzó un máximo de 0,51 en su peso ponderado, superando en un pequeño margen a la zona B que obtuvo un 0,48. La variación previa de criterios decía a priori que la zona C sería la del mayor beneficio para este criterio, ya que su variación indicaba una disminución en el lead time en más de un 33%. Este valor indica que la red neuronal se basa en cómo están distribuidos los datos al inicio de la simulación, por lo que afirmar si un criterio tuvo un incremento, no necesariamente la red lo identifique y lo muestre como un beneficio, sino que esta se basa en la variación porcentual y en qué tan dispersos quedaron los datos entre sí.
Como resultado final de este escenario se puede apreciar que la prioridad recayó sobre la zona A, debido que fue la que tuvo mayor variación positiva con respecto al criterio de lead times, es decir los tiempos de entrega se redujeron considerablemente para atender la demanda de los clientes. Esto era algo que se esperaba, dada la importancia de este criterio para priorizar zonas.
5. CONCLUSIONES
Básicamente se resalta la importancia que tienen las decisiones de índole logístico y de mercadeo para temas como el de priorizar zonas de clientes. Normalmente estos tipos de decisiones son independientes entre sí, pero en esta investigación se resalta lo importante que es combinar estos dos departamentos para la toma de decisiones conjuntas.
Se demuestra la importancia que tienen las herramientas estadísticas y/o matemáticas para la toma de decisiones empresariales. En este orden los mapas auto-organizados o mapas de Kohonen permiten llegar a acercamientos importantes cuando se requiere estudiar cierta cantidad de datos que faciliten el proceso de toma de decisiones.
Los criterios logísticos y de mercado identificados en la investigación dan una visión inicial de los comportamientos de cada zona de mercado. Estos permiten ver los estados en conflicto que presenta cada zona en particular; adicional, se reconoce la importancia que tiene cada uno de ellos en materia de priorización, dado que al variar sus valores de cierta manera hacen que las prioridades de las zonas cambien de una a otra.
Se puede decir que las variaciones de los parámetros de entrada modifican la ubicación de las zonas de mercado dentro del mapa auto-organizado y, por consiguiente, el cambio en la prioridad de la zona. El análisis de escenarios demostró que cualquier patrón de entrada que se modifique puede ocasionar la variación en la prioridad de la zona, y por ende la redistribución de ellas dentro del mapa.
Se comprueba la gran utilidad que tienen las redes neuronales artificiales para asimilar el comportamiento de un número determinado de datos que presentan situaciones en conflicto, a diferencia de otras herramientas que no podrían realizarlo de manera muy clara. Para efectos de estos casos las redes neuronales trabajan con el aprendizaje no supervisado, en el cual dicho patrón o supervisor no existe; por ende, los pesos iniciales de la red se activan aleatoriamente y tratan de encontrar el dato inicial más cercano a las neuronas próximas a activarse.
REFERENCIAS
Bigné, E.; Aldas-Manzano, J.; Küster, I.; Vila, N. (2010). Mature market segmentation: a comparison of artificial neural networks and traditional methods. Neural comput & applic, 19, pp. 1-11. [ Links ]
Bravo, J.; Orejuela, J.; Osorio, J. (2007). Administración de recursos de distribución: indicadores para la priorización en transporte. Estudios gerenciales, 23(102), enero, pp. 101-118. [ Links ]
Caicedo, E.; López, J. (2009). Una aproximación práctica a las redes neuronales artificiales. Cali: Programa editorial Universidad del Valle, 217 p. [ Links ]
Sang Chul Lee; Yung Ho Suh; Jae Kyeong Kim; Kyoung Jun Lee (2004). A cross-national market segmentation online game industry using SOM. Experts Systems with Applications, 27(1), pp. 559-570. [ Links ]
Curry, B.; Davies, F.; Evans, M.; Moutinho, L. (2001). The Kohonen self-organizing map: an application to the study of strategic groups in UK hotel industry. Expert Systems, 18(1), pp. 19-31. [ Links ]
Curry, B.; Davies, F.; Evans, M.; Moutinho, L.; Phillips, P. (2001). The Kohonen self-organising map as an alternative to cluster analysis: an application to direct marketing. International Journal of Market Research, 45(2), pp. 191-211. [ Links ]
Kiang, M.; Kumar, A. (2001). An evaluation of self-organizing map networks as a robust alternative to factor analysis in data mining applications. Information system research, 12(2), junio, pp. 177-194. [ Links ]
Kiang, M.; Kumar, A. (2004). A comparative analysis of an extended SOM network and K-means analysis. International journal of knowledge-based and intelligent engineering system, 8, pp. 9-15. [ Links ]
Kuo, R.J.; An, Y.L.; Wang, H.S.; Chung, W.J. (2006). Integration of self-organizing feature maps neural network and genetic k-means algorithm for market segmentation. Expert systems with applications, 30(2), febrero, pp. 313-324. [ Links ]
Meschino, G.; Comas, D.; Ballarin, V.; Scandurra, A.; Passoni, L. (2015). Automatic design of interpretable fuzzy predicate systems for clustering using selforganizing maps. Neurocomputing, 147, pp. 47-59. [ Links ]
Montoya Suárez, O. (2007). Aplicación del análisis factorial a la investigación de mercados. Caso de estudio. Scientia et Technica, 13(35), pp. 281-286. [ Links ]
Seret, A.; Verbraken, T.; Baesens, B. (2014). A new knowledge- based constrained clustering approach: Theory and application in direct marketing. Applied Soft Computing, 24, pp. 316-327. [ Links ]
Soldic-Aleksic, J. (2012). Combined approach of Kohonen SOM and CHAID decision tree model to clustering problem: a market segmentation example. Journal of economics and engineering, 3(1), abril, pp. 20-27. [ Links ]

