











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroducción
A nivel mundial el riesgo crediticio se relaciona con la probabilidad de una perdida percibida por las diferentes instituciones financieras dado el incumplimiento de las obligaciones por parte de un deudor, es así como, dentro de las funciones de estas instituciones está la posibilidad de colocar el dinero a través de diferentes productos presentes en el sistema financiero de cada país. En el caso de Colombia existen dos tipos de entidades financieras, dependiendo si estas se encuentran o no vigiladas por la Superintendencia Financiera de Colombia, en el caso de las primeras, la vigilancia y control establecido por las normas vigentes permite una cierta continuidad de dichas empresas sin que exista el temor de quiebra, lo anterior, respaldado por la constante revisión de sus colocaciones y captaciones.
En el caso de las entidades financieras no vigiladas por la Superintendencia Financiera de Colombia, producto de que su única función es la colación de dinero en el mercado, se hace necesario un estudio más profundo en cuanto a la forma que utilizan para realizar las respectivas aprobaciones de crédito a sus usuarios. Adicionalmente, teniendo en cuenta que una de las principales funciones de estas instituciones es la concesión de créditos, ya sea de manera directa o a través de tarjetas de crédito, tal y como lo plantea Krichene (2017) se hace meritorio, dadas las cualidades o características de sus usuarios, realizar un estudio para identificar cuáles son las variables, tanto financieras como no financieras, que permitan modelar la selección entre un cliente bueno y uno malo.
Los investigadores han tomado como centro de estudio la Federación Nacional de Comerciantes (Fenalco Valle del Cauca), la elección se fundamenta en tres razones: la primera, no se encuentra vigilada por la Superintendencia Financiera de Colombia dado que solo se limita a la colocación, la segunda, su línea de negocio es la prestación de servicios financieros para créditos de consumo, y, la tercera, posee cubrimiento en todo el territorio colombiano. Por lo tanto, esta investigación parte de la información histórica de los créditos otorgados a los clientes de la entidad con la cual se pretende encontrar un modelo scoring que identifique cuáles son las variables de mayor peso para la toma de decisiones en la adjudicación del crédito para este tipo de entidades financieras y, para esto plantea utilizar dos técnicas estadísticas como son la regresión logística y la red neuronal, las cuales han sido las técnicas más utilizadas en los últimos años por los estudios de pronosticación, tal y como lo afirman los trabajos de Tascon y Castaño (2012) y De Andres, Lorca, Sanchez y De Cos (2012).
El resto del documento se encuentra organizado de la siguiente manera: la sección 2 describe los materiales y métodos, seguido, se encuentra la sección 3 que muestra los resultados, la sección 4 la discusión, y, la sección 5 presenta las conclusiones.
Materiales y métodos
La investigación propone utilizar dos técnicas estadísticas como son la regresión logística y la red neuronal, la primera técnica se basa en la probabilidad de ocurrencia de los posibles valores de la variable dependiente y utiliza para ello una regresión logística que acota los resultados en el intervalo 0 y 1, adicionalmente, está respaldada por su capacidad de pronosticación y sus resultados que ofrecen una mejor comprensión frente a otras técnicas estadísticas, tal y como lo muestran los trabajos de Laffarga, Martín y Vázquez (1985) y Pereira, Crespo y Sáez (2007). La segunda técnica son modelos computacionales cuyo objetivo es resolver problemas utilizando el aprendizaje supervisado y para ello utiliza una muestra base del proceso que se ampara en el éxito del autoaprendizaje producto del entrenamiento, es así como estos modelos se convierten en grandes solucionadores de problemas. Lo anterior se refleja en los trabajos de Tsai y Hung (2014) y Kiruthika y Dilsha (2015). Tascon y Castaño (2012) y De Andres, Lorca, Sanchez y De Cos (2012) plantean un punto adicional, y es que el uso de estas dos técnicas estadísticas permiten realizar una comparación entre una técnica tradicional y una contemporánea.
Muestra
Se toma como referencia una entidad financiera que no se encuentra vigilada por la Superintendencia Financiera de Colombia, que en este caso es la Federación Nacional de Comerciantes (Fenalco Valle del Cauca) y se trabaja con una cartera de consumo. La muestra está conformada por 43.086 obligaciones para el período enero del 2014 y julio del 2016, con su respectivo comportamiento entre agosto del 2016 y julio del 2017, es decir, se tiene una visión de doce meses después del origen del compromiso para cada uno de los créditos seleccionados que conforman la base de datos.
Variable dependiente
Esta variable está determinada por pertenecer a una población que se encuentra segmentada en dos grupos correspondientes a clientes buenos o clientes malos. Los clientes malos se caracterizan por entrar en default o incumplimiento, y corresponde a una mora máxima por producto mayor a 60 días. Teniendo como referencia que la tasa de malos es la relación de créditos marcados como malos sobre el total de créditos, se detectó una tasa global de malos del 28,3 %, evidenciando que el perfil de riesgo de la población en estudio es alto, y a la vez, superando a las manejadas por una entidad bancaria tradicional. Por lo tanto, para efectos de esta investigación los clientes malos se categorizan con 1 y de los deudores que más se relacionan con 0 en caso contrario.
Variables explicativas
Antes de iniciar el proceso de modelación es pertinente establecer las características el default, para el caso, se tiene de un riesgo superior a un riesgo global. De igual forma, se establecen aquellas características que se constituyen en un factor protector por registrar un riesgo inferior al global (Tabla 1).
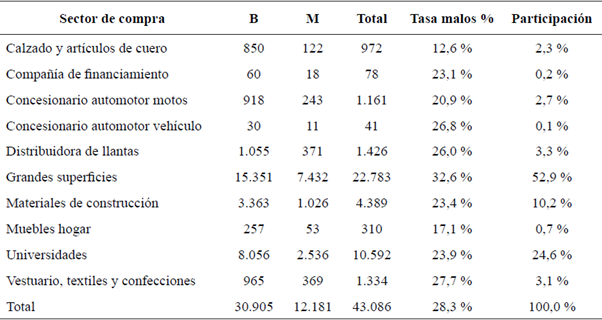
El ser un cliente bueno o malo está relacionado con el sitio donde es utilizado el producto después de ser otorgado el crédito, por lo que se considera que no debe formar parte del modelo de incumplimiento, sin embargo, se emplea para asignar una política diferenciada en las tasas de interés. Así, las compras en establecimientos de calzado y artículos de cuero podrían tener un descuento los fines de semana y las compras en grandes superficies asignarles una tasa de interés más alta para compensar el riesgo evidenciado.
Por otra parte, tomando como referencia la información que la entidad financiera tiene de sus clientes, se procedió a conformar la base de datos con doce variables explicativas que son utilizadas en los respectivos modelos de pronosticación de clientes buenos o malos; la Tabla 2 muestra las variables y la forma como se miden.

Resultados
Se examinaron doce variables con las cuales se postularon los modelos propuestos, adicionalmente, se realizó una partición de la base de 43.086 obligaciones en 70 % de entrenamiento y 30 % de comprobación.
Regresión logística
El modelo resultante bajo esta metodología se obtuvo teniendo en cuenta las variables estado civil, sexo, ocupación, escolaridad, vivienda, producto, estrato, departamento, personas a cargo, cupo asignado, ingreso y plazo. La Tabla 3 muestra los parámetros estimados para cada una de estas variables con su respectivo nivel de significancia.
Tabla 3 Variables en la ecuación del modelo logit
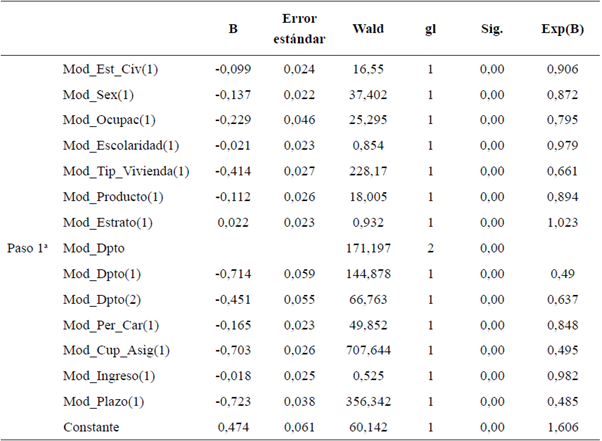
a. Variables especificadas en el paso 1: Mod_Est_Civ, Mod Sex, ModOcupac, ModEscolaridad, Mod_ Tip_Vivienda, Mod_Producto, Mod_Estrato, Mod_Dpto, Mod_Per_Car, Mod_Cup_Asig, Mod_Ingreso, Mod_Plazo
Fuente: elaborado por los autores.
Para evidenciar la efectividad del modelo se realiza la prueba de aciertos en la base de entrenamiento, encontrando que el 71,65 % de los clientes se predijeron con exactitud, mientras que en la base de comprobación la exactitud subió al 72,04 %, lo que implica que la precisión es similar en ambas bases particionadas (ver Tabla 4).

En cuanto a la prueba de bondad de ajuste tradicional para los modelos logit, se aplicó la prueba de Hosmer y Lemeshow, arroj ando una chi-cuadrado de 11.267 con 8 grados de libertad y un nivel de significancia de 0,187, lo que implica que no se rechaza la hipótesis nula de que el modelo tiene buen ajuste con una significancia del 95 %. Finalmente, la distribución de los rangos de score para el modelo logístico propone un punto de corte de 700 puntos, que se relaciona con la banda donde se obtiene el mayor grado de separación de buenos y malos, así, aplicando la prueba de Kolmogórov-Smirnov (KS) se obtuvo un 18,44 %, con lo cual se puede afirmar que las observaciones podrían razonablemente proceder de la misma distribución especificada.
Red neuronal
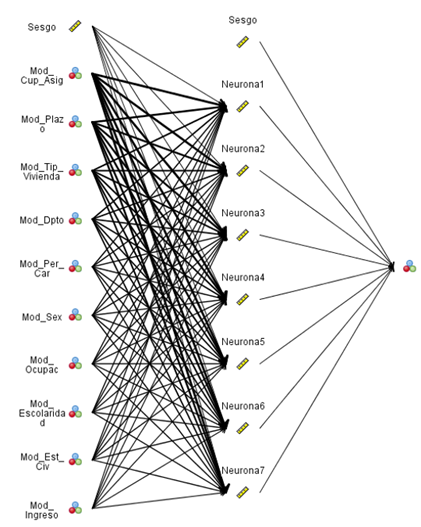
En el proceso de búsqueda del modelo de pronosticación de incumplimiento, la metodología de la red neuronal seleccionó las variables cupo asignado, plazo, departamento, personas a cargo, sexo, ocupación, escolaridad, estado civil e ingreso. Sin embargo, entre todas las variables implícitas en el modelo, el predictor más relevante a la hora de predecir los clientes buenos o malos fue el cupo asignado con un peso cercano al 20 %.
En el caso de la red neuronal se tuvieron en cuenta siete neuronas, tal y como se muestra en la Figura 1, donde se evidencian las conexiones resultantes con los predictores preseleccionados. La intensidad o el grosor de las líneas muestran la fortaleza de la conexión entre las neuronas y las variables, en este caso, la red posee una precisión del 71,7 % con relación a la clasificación global correcta entre clientes buenos y malos.
En cuanto a los resultados de la red neuronal en su etapa de entrenamiento, se observa que los clientes se predijeron bien en un 71,66 %, mientras que en la etapa de comprobación la exactitud subió al 71,89 %, lo anterior implica que la precisión es similar en ambas bases particionadas, como se puede ver en la Tabla 5.

Finalmente, la distribución de los rangos de score para la red neuronal propone un punto de corte de 700 puntos, el cual se relaciona con la banda donde se obtiene la aprobación o negación de las solicitudes futuras, con un KS del 18,47 % que nos afirma que las observaciones podrían razonablemente proceder de la misma distribución especificada.
Comparación de modelos
Desarrollada la investigación se plantea que las técnicas estadísticas aplicadas, regresión logística y red neuronal, permiten desarrollar un modelo scoring para determinar si un cliente es bueno o malo. Sin embargo, los investigadores seleccionan la regresión logística como el mejor modelo para predecir la probabilidad de incumplimiento correspondiente a las futuras colocaciones de crédito, lo anterior se estipula basado en las siguientes razones que se desprenden de los resultados que se muestran en la Tabla 6.
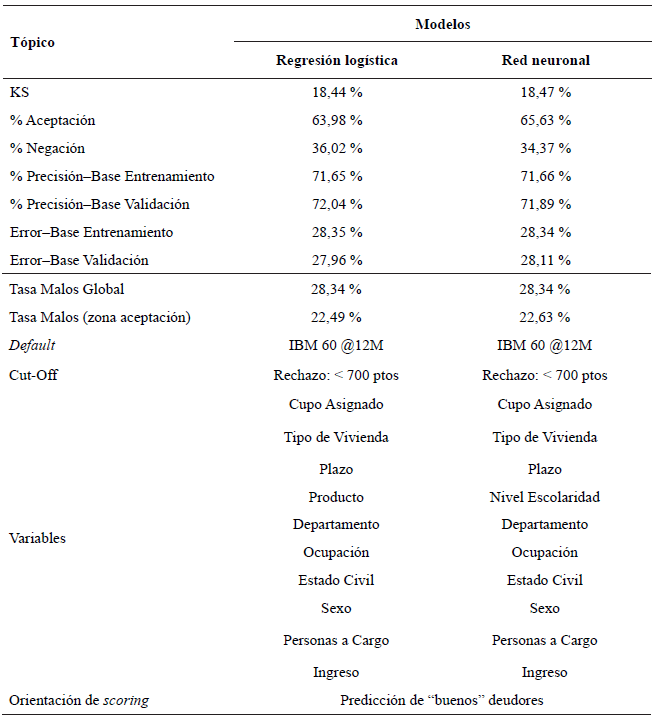
Al analizar la prueba Kolmogórov-Smirnov (KS) que prueba la bondad de ajuste al contrastar si las observaciones proceden de la distribución especificada, vemos que la regresión logística posee un KS de 18,44 menor al 18,47 de la red neuronal.
Aunque la regresión logística es inferior a la red neuronal en el porcentaje de precisión en la base de entrenamiento, es superior en la base de validación, lo cual es más importante si se tiene en cuenta que lo que se busca es identificar correctamente a los nuevos clientes a la hora de otorgar un crédito.
La tasa global de malo es del 28,34 % en ambos modelos, sin embargo, la tasa de malos en la zona de aceptación es menor en la regresión logística, el cual es del 22,49 % frente a un 22,63 % de la red neuronal.
De forma adicional, la regresión logística es de más fácil entendimiento e implementación frente a la red neuronal, dado que el desarrollo dentro de sus capas neuronales juega el papel de una caja negra, mientras que la regresión logística está explicada por una distribución logística muy bien estipulada dentro de los conceptos de los modelos logísticos, para este caso, un modelo logístico binario.
Discusión
Una de las primeras técnicas estadísticas utilizada en el estudio del riesgo crediticio tiene que ver con el análisis discriminante, una técnica multivariante que permite diferenciar a dos grupos sobre los cuales se tienen varias observaciones, la cual busca explicar el sentido y la proporción de la asignación sistemática de un nuevo grupo observado. Entre los estudios más representativos están los de Myers y Forgy (1963), Lane (1972), Apilado, Warner y Dauten (1974), Grablowsky y Talley (1981), Desai, Crook y Overstreet (1996) y Orsenigo y Vercellis (2013).
Otra técnica es el análisis de regresión, proceso que permite estimar una posible relación entre una variable dependiente y las variables independientes, este tipo de técnica se utilizó en los estudios de Orgler (1970), Fitzpatrick (1976) e Im, Apley, Qi y Shan (2012). Sin embargo, estas técnicas fueron reemplazadas por la regresión logística que es una regresión enmarcada en el grupo de los modelos lineales generalizados, las cuales utilizan una función logit y son útiles para modelar probabilidades referentes a un evento en función de otras variables, como es el caso tratado en esta investigación. Los estudios que utilizan esta técnica para trabajar el riesgo crediticio son el de Wiginton (1980), Srinivasan y Kim (1987), Leonard (1993), Wang y Ma (2011), Nie, Wei, Zhang, Tian y Shi (2011), Louzada, Ferreira y Diniz (2012), Sohn, Kim y Yoon (2016) y Zhu, Xie, Sun, Wang y Yan (2016); todos ellos arrojaron niveles de acierto de pronosticación por encima de los arrojados por el análisis discriminante y el análisis de regresión, lo que justifica el uso de la regresión logística en la investigación.
Por otra parte, dentro del campo de la inteligencia artificial tenemos las redes neuronales, un modelo computacional que tiene como base un conjunto de unidades simples o neuronas artificiales, en este caso, cada sistema se trabaja de manera independiente y con la capacidad de aprender dado el comportamiento observado del evento. El sistema de redes neuronales está compuesto por varias capas que poseen dirección hacia adelante y hacia atrás. Después del proceso de aprendizaje y de entrenamiento la red se puede convertir en un solucionador excepcional, sin embargo, se hace necesario tener un número alto de iteraciones. Entre los trabajos concernientes al riesgo de crédito que han utilizado la técnica de las redes neuronales, tenemos a Davis, Edelman y Gammerman (1992), Tsai y Hung (2014), Setiono, Azcarraga y Hayashi (2015), Soydaner y Kocadagli (2015), Zhao et al. (2015) y Kiruthika (2015).
En este punto, los autores se basan en los trabajos de Tascon y Castaño (2012), De Andres, Lorca, Sanchez y De Cos (2012) y Alaka et al. (2018) para justificar la comparación de los modelos obtenidos a través de regresiones logísticas y redes neuronales, logrando con esto obtener el modelo scoring más adecuado para la institución financiera de estudio, y, en especial para carteras de consumo.
Conclusiones
La conclusión global que se extrae es que las dos técnicas utilizadas son adecuadas para el estudio y modelación de incumplimiento para un cliente perteneciente a una cartera de consumo, lo anterior, respaldado por el alto índice de eficacia predictiva. Adicionalmente, se considera que el modelo de regresión logística ofrece las mejores características para su predicción, dado que arroja el mejor KS frente a los resultados de la red neuronal.
Por otra parte, cabe mencionar que los dos modelos basan su poder de pronosticación en diez variables de las cuales nueve de ellas son similares, sin embargo, la regresión logística tiene en cuenta la variable producto, mientras que la red neuronal toma en cuenta el nivel de escolaridad.
Finalmente, al analizar las variables incluidas en el modelo de regresión logística, se afirma que tienen un efecto positivo en la variable dependiente, debido al signo de los Beta (coeficientes) asociados a cada una, por lo que un cambio en la unidad de cada variable incide en el aumento en el puntaje para llegar al punto de corte, que para este caso se hizo en 700 puntos.

