











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroducción
En los últimos años en Colombia ha habido un creciente interés en el desarrollo de estudios que informen sobre los efectos que tiene el tiempo destinado a clase en los desempeños de los estudiantes en pruebas estandarizadas (Hincapié, 2014; Ovalle-Ramirez, 2018; Ovalle-Ramirez, Villa-Ochoa, González-Gómez, 2018). En particular, en el país se viene implementando una política pública de jornada única que se basa en el supuesto de que una sola jornada, y por tanto mayor tiempo pedagógico, desarrollarán competencias básicas de los estudiantes y permitirán que se prevengan problemas psicosociales (Ovalle-Ramirez, (2018) Al respecto, Ovalle-Ramírez et al. (2018)., argumentaron que si bien en la literatura internacional existen estudios que reportan un efecto positivo de la jornada escolar en el desempeño académico de los estudiantes, también es cierto que estos efectos son parciales y están mediados por otros factores como, por ejemplo, la "calidad" en las instituciones educativas. Según informa Ovalle-Ramírez (2018) una sola jornada puede implicar un efecto negativo sobre los desempeños de los estudiantes en las Pruebas Saber 11. Para la autora "un mayor tiempo de formación (la jornada Completa equivalente a 7 horas) por sí sola tampoco logra un mayor efecto que la Doble jornada" (p. 13).
Estudios como los descritos anteriormente evidencian que en Colombia las Pruebas Saber 11 son una herramienta estandarizada que además de permitir evaluar las competencias promovidas en diferentes áreas a lo largo de la educación básica y media, también se convierten en insumo para el desarrollo de investigaciones educativas a través de las cuales se informe la política pública. En su marco conceptual, estas pruebas incluyen la evaluación de competencias en diferentes procesos y componentes del pensamiento matemático, entre ellos, el pensamiento aleatorio. Este pensamiento se reconoce porque "ayuda a tomar decisiones en situaciones de incertidumbre (MEN, 2006, p. 64). Los resultados de las pruebas Saber 11 permiten valorar, en parte, los desempeños y el aprendizaje de las matemáticas y de la estadística en particular.
Se espera entonces que las instituciones educativas posibiliten el desarrollo de capacidades en los estudiantes que se reflejen en el desempeño en tales pruebas estandarizadas. Algunos investigadores plantean que para el desarrollo del pensamiento aleatorio se requiere el uso de contextos, de variables y su naturaleza, que permite mejorar el desarrollo de las competencias de solución de problemas en contexto (Batanero y Díaz, 2011; Zapata-Cardona, 2014). Estas competencias no se presentan de manera exclusiva en las preguntas de estadística, sino que están de manera transversal a gran parte de la Prueba Saber 11 en matemáticas.
Con el fin de promover las competencias matemáticas y en estadística, en Medellín-Colombia se han implementado dos modalidades para la distribución horaria en la enseñanza de la estadística. Algunas instituciones dedican un horario fijo semanal para la enseñanza de la estadística, emulando de esta manera, el desarrollo de una asignatura independiente. Por su parte, otras instituciones prefieren que los contenidos sean abordados dentro de la asignatura de matemáticas; por tanto, desarrollan la estadística como una unidad temática en algún momento del año escolar. La decisión sobre la modalidad de la distribución horaria en las instituciones educativas puede estar permeada la formación de los profesores que enseñan estadística y por sus visiones sobre esta disciplina; pues en Colombia, la formación del profesor de estadística, generalmente, se muestra como un apartado más de la formación de profesores de matemáticas, lo cual puede condicionar las imágenes que los profesores construyen sobre la estadística y su enseñanza (Zapata-Cardona, 2014, y González-Gómez, 2017).
El desarrollo de competencias en matemáticas y estadística es un proceso complejo que involucra no solo periodos largos de tiempo sino la conjunción de factores contextuales, institucionales y de formación de profesores (Niss et al., 2017). Ello puede conllevar a que en ocasiones la estadística ocupe los últimos lugares dentro de la enseñanza. En Colombia son escasos los estudios que documentan los efectos que tiene la enseñanza de la estadística en el desarrollo de las competencias de los estudiantes. Por tanto, se desarrolló un estudio que comparó las dos modalidades adoptadas por las instituciones oficiales con el fin de determinar si alguna de ellas representa un efecto positivo en el desarrollo de las competencias de solución de problemas inmersos en contextos y el pensamiento aleatorio. Para ello, se adoptaron los resultados en pruebas Saber 11 de las instituciones educativas públicas de Medellín.
Materiales y métodos
Muestra
La muestra reunió a 36 instituciones oficiales del municipio de Medellín que agruparon a 2808 estudiantes. Se usaron las bases de datos de Icfes (Instituto Colombiano para la Evaluación de la Educación) para tomar los puntajes de matemáticas que cada una de estas instituciones obtuvo en las Saber 11. Estos puntajes correspondieron a los estudiantes que presentaron la prueba en el segundo semestre de 2015. También se tomó la sociodemográfica que permitiera su identificación. Adicionalmente, se reunió la información relacionada con la intensidad horaria en que impartieron la estadística a través de un cuestionario por correo electrónico y por vía telefónica obteniendo una tasa de respuesta del 17.22%, estos son 36 de 209 colegios oficiales de Medellín. Se preguntó sobre los grados y el tiempo desde que se implementa cada modalidad.
El modelo
El uso de los modelos lineales mixtos facilita el reconocimiento de la estructura jerárquica que se encuentra en datos con medidas repetidas (Liu, Zheng y Shen, 2008); Vonesh, Chinchilli y Pu, 1996). Se prefiere el modelo lineal mixto, porque puede ocurrir que las características de los estudiantes y las prácticas de enseñanza y de gestión sean similares para alumnos del mismo colegio, pero diferentes para alumnos de distintos centros educativos. La utilización de las técnicas estadísticas tradicionales se traduce en distorsiones de los niveles de significancia de los parámetros estimados (Caro y Casas 2013, p. 111).
Para modelar datos con medidas repetidas, Laird y Ware (1982) suponen que se tienen sujetos y que cada sujeto ha sido observado veces, por tanto, se tienen disponibles observaciones en total. Sea el vector de respuestas del j-ésimo sujeto que satisface el siguiente modelo:
Ecuación 1: Y j = X j β+Z j b j +ε j , j =1,2,…,m
Donde : denota el vector con los puntajes de la prueba de matemáticas para el j-ésimo colegio; es el número de instituciones educativas tomadas. : contiene las covariables de efectos fijos. : es el vector de parámetros de efectos fijos. : es la matriz que contiene las variables explicativas de efecto aleatorio. : es el vector de parámetros de efecto aleatorio, con. : es un vector que contiene los términos de error (o desviaciones) de la institución j-ésima, . Para la varianza del error se toma una matriz desestructurada, debido a que las Pruebas Saber 11 se realizan en forma individual y se supone que la realización del examen de un estudiante no está influenciada por la de otro.
Resultados
Se ajustaron varios modelos lineales con efectos mixtos, las estimaciones de los distintos modelos se realizaron utilizando la técnica conocida como máxima verosimilitud restringida, para ello se empleó el Software R.
Para la elección del modelo que mejor se ajustó a los datos se fueron incluyendo covariables, una a una, estas fueron las características de las instituciones o propias de los estudiantes. Se comenzó con el modelo nulo, solo con intersecto aleatorio, que se establece como base de comparación para los otros modelos a medida que se van ingresando covariables. Entre las covariables que se ingresaron al modelo está la modalidad de distribución de la intensidad horaria en que se enseña estadística, también jornada y estrato de la institución y además, género, edad y estrato socioeconómico del estudiante, estas se adicionaron al modelo con el fin de que no se enmascare el efecto de la intensidad horaria en el puntaje de la prueba de matemáticas en las Pruebas Saber 11. Se utilizó un nivel de significancia de 5% para determinar la significancia de las variables en el modelo.
A continuación, en la Tabla 1 se especifican los modelos ajustados.

Donde, Yjj: es el puntaje en matemáticas del estudiante i del centro educativo j, i = 1, 2,.. .,n j = 1,2,...,36. β o : es el intercepto fijo y en el modelo uno corresponde a una estimación de la media del puntaje de matemáticas en las instituciones. : es el intercepto aleatorio que en el modelo representa el efecto institución. β kj : son los parámetros de efecto fijo de cada una de las variables consideradas en el modelo, k = 1, 2.
La Tabla 2 muestra las estimaciones de los parámetros de efectos fijos para cada uno de los modelos anteriores. Los modelos del 1 al 7 recogen los valores estimados de los efectos fijos considerados en cada modelo. Las estimaciones de los efectos fijos aparecen acompañadas de su error típico, sus grados de libertad, su valor tipificado (que se obtiene dividiendo la estimación entre su error típico) y el nivel crítico o valor p (vp) que se obtiene al contrastar la hipótesis nula donde se afirma que el parámetro respectivo tiene un valor de cero.

En el modelo 1, la constante (o intersección), que es el único parámetro de efecto fijo presente en este modelo, es una estimación de la media poblacional de la variable dependiente o puntaje en matemáticas en las Pruebas Saber 11 de las 36 instituciones. La estimación tiene un valor de puntos que es el promedio observado en la prueba de matemáticas. Los resultados de la tabla permiten afirmar que el valor poblacional de la constante o intersección del modelo es distinto de cero (v p < 0,0005).
El intersecto fijo no tiene interpretación práctica en los modelos 2 a 7, porque no tiene sentido evaluar todas las covariables en sus valores nulos.
Desde el modelo dos hasta el cuatro, se fueron incluyendo, una por una, las variables propias de los estudiantes: edad, género y estrato de la vivienda, las cuales resultaron ser estadísticamente significativas a un nivel de confianza de 95%, vp < 0.05, esto indica que estas variables ayudan a explicar la variabilidad presente en el resultado en matemáticas en las Pruebas Saber 11.
Del modelo 5 al 7, los valores p, las variables inherentes al colegio como son: jornada que utiliza el colegio para el grado 11, estrato socioeconómico del colegio y distribución de la intensidad horaria dedicada a la enseñanza de la estadística, resultaron mayores de 5% y, por tanto, estas covariables no ayudan a explicar la variabilidad presentada en el resultado de la prueba de matemáticas en las Pruebas Saber 11.
La Tabla 3 muestra las estimaciones de los parámetros de covarianza para cada uno de los modelos anteriores, es decir, las estimaciones de los parámetros asociados a los efectos aleatorios del modelo. Además, esta tabla presenta las correlaciones interclase para los siete modelos. Todos los modelos ajustados en este trabajo tienen la misma estructura de varianzas y covarianzas, que se deriva de la inclusión de adicionar a todos los modelos como parámetro de efecto aleatorio, el intercepto. Este intercepto aleatorio hace referencia o recoge el efecto institución.

La Tabla 3 muestra la desviación estándar para el modelo l, esta medida es el factor institución, que indica cuánto varía el puntaje en la prueba de matemática entre las todas las instituciones educativas, y la desviación de los residuos, que indica cuánto varía el puntaje dentro de cada institución. El coeficiente de correlación interclase para este modelo es 10.80%, el cual se calcula por:

El coeficiente de correlación intraclase es una medida de la variabilidad entre las instituciones, es la proporción de la variabilidad total del puntaje en matemáticas que se debe al efecto institución. Entonces, ese 10.80% representa el porcentaje de variabilidad total, en el puntaje de matemáticas existente entre los estudiantes porque pertenecen a distintas instituciones educativas.
De la tabla anterior también se puede notar que la desviación residual (σ e ), una medida de la dispersión de los puntos con respecto al modelo ajustado, disminuye significativamente entre el modelo dos con respecto al uno, del tres con respecto al dos y del cuatro con respecto al tres, debido a que la inclusión de covariables de efectos fijos inherentes al estudiante resultó ser estadísticamente significativas, como se mencionó anteriormente. En tanto que esto no ocurre al comparar los modelos cinco, seis y siete con respecto al cuatro, que en todos los casos es de aproximadamente 9.46, lo cual muestra que las covariables específicas del colegio no aportan para la explicación de la variable dependiente, resultado en la prueba de matemáticas en las Pruebas Saber 11.
La correlación intraclase va disminuyendo del modelo uno al cuatro, debido a que la inclusión de variables, que ayuda a explicar el resultado en la prueba, va reduciendo la dispersión de los puntos alrededor del modelo ajustado (σ e disminuye). Por otro lado, en los modelos cinco, seis y siete no es recomendable analizar la correlación intraclase porque la inclusión de las variables intensidad horaria, jornada del colegio y estrato socioeconómico del colegio no ayuda a explicar a la variable dependiente, por tanto, son modelos sobreajustados y se pueden generar problemas de inflación de varianzas u otros tipos de distorsiones en las varianzas.
Es de anotar que en este análisis se han tomado como unidades de medición a los colegios y ninguna de sus covariables ha resultado significativa en el modelo, entonces el estrato del colegio, la jornada que utilizan para el grado once y la distribución de la intensidad horaria que se dedica a la enseñanza de la estadística, son variables que no están relacionadas con el puntaje obtenido en matemática en las Pruebas Saber 11, por tanto, no tiene sentido utilizar alguna de estas variables como efecto aleatorio en el modelo y, en consecuencia, no es necesario considerar otras estructuras de covarianza.
Teniendo en cuenta todos los análisis realizados, el modelo 4, entre los modelos ajustados, es el que mejor explica la variable dependiente (puntaje de matemáticas). En este modelo se observa que el efecto edad toma un valor de -1.08696, el cual es negativo, por tanto, se espera que los estudiantes con mayor edad en el momento de presentar la prueba obtengan resultados inferiores con respecto a los de menor edad. Es decir, por un año de aumento en la edad, se espera que el resultado en la prueba de matemáticas disminuya 1.08696 si se mantienen constantes las demás variables. En este modelo se tomó la variable género de la siguiente manera,
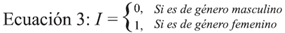
Por tanto, como el coeficiente para el género fue de -3.97626, que es un valor negativo, se espera que los hombres obtengan un resultado más alto que las mujeres, Esto quiere decir que si se toman dos estudiantes del mismo colegio, con la misma edad y el mismo estrato socioeconómico, pero uno de género masculino y, el otro de género femenino, se espera que el resultado en la prueba de matemáticas entre ellos presente una diferencia de aproximadamente cuatro puntos.
En el caso del estrato socioeconómico, el coeficiente en el modelo ajustado fue 1.00943, por tanto se espera que los estudiantes del mismo colegio, mismo género y misma edad vayan incrementando el resultado en la prueba de matemáticas en 1.00943 por cada incremento de un nivel en el estrato socioeconómico.
Se menciona que los efectos fijos sólo se deben analizar en el modelo 4, porque es evidente que los modelos uno, dos y tres están subajustados y, por consiguiente, pueden presentar problemas de sesgo en la estimación de los parámetros.
En cuanto el efecto institución, la correlación intraclase del modelo cuatro fue de 8.19, este valor indica que después de controlar los efectos de las covariables intrínsecas de los estudiantes, como son su edad, su género y su estrato socioeconómico, el 8.19% de la varianza total (la varianza de la variable dependiente) se atribuye o corresponde a diferencias entre las medias del puntaje en la prueba de matemáticas de los centros educativos. Este coeficiente informa que existen diferencias entre los puntajes medios obtenidos por los colegios tras controlar los efectos de las covariables de los estudiantes.
Finalmente, el modelo que mejor se ajusta a la información dada es el modelo cuatro, cuya estimación está dada por,

El modelo anterior, cumplió con todos los supuestos. El supuesto de normalidad se verificó a través de prueba de bondad de ajuste Kolmogorov - Smirnov, y con los gráficos histograma de frecuencias y cuantil - cuantil de los residuales. El supuesto de homocedasticidad se comprobó por medio del gráfico de residuales estandarizados contra valores ajustados. El supuesto de independencia se comprobó por medio de la no significancia de los valores de autocorrelación que se observó en el gráfico de la función de autocorrelación con bandas de significancia (ACF), efectivamente los residuales son un ruido blanco. También se menciona que los supuestos de media cero y de no correlación cruzada se satisfacen inmediatamente gracias a la técnica de estimación que se empleó en este trabajo, la cual se conoce como máxima verosimilitud restringida.
Discusión
Las instituciones educativas que tenían la estadística con una intensidad horaria fija semanal no lograron diferenciarse en el resultado en matemáticas en las Pruebas Saber 11, en comparación de aquellas que no lo hacían. Al igual que Ovalle-Ramírez et al. (2018), este estudio sugiere trascender la idea de que mayor tiempo de instrucción genera mejor desempeño de los estudiantes; más allá de ello, sugiere que los esfuerzo se centren en el uso del tiempo para el desarrollo de estrategias para el trabajo en grupo y el desarrollo de simulaciones (Zacharopoulou, 2006), la solución de problemas, el desarrollo de proyectos que permitan aprender a través del "hacer estadística'" (Smith, 1998), y demás estrategias que permitan desarrollar un razonamiento estadístico diferenciado del razonamiento matemático.
Por otro lado, las variables sociodemográficas asociadas al estudiante, tomadas en este estudio sí resultaron ser significativas; esto indica que un buen desempeño de los estudiantes depende, principalmente, de las condiciones personales de cada individuo; esto se evidencia en que estudiantes del mismo colegio, que reciben los mismos estímulos académicos (clases iguales, tareas académicas iguales, cuerpo docente igual, material didáctico igual, ocupan espacios iguales), pueden obtener resultados diferentes en matemáticas en las Pruebas Saber ll, si su situación personal es diferente. Esto sugiere aunar esfuerzos en las instituciones educativas para promover la participación de los estudiantes en espacios que aporten al desarrollo de una cultura académica institucional, es decir, espacios en los que puedan formular preguntas, generar indagaciones y utilicen sus conocimientos (entre ellos los estadísticos) para darles solución.
Este estudio también sugiere que, más allá de las características sociodemográficas de las instituciones educativas, se debe prestar atención a las características sociodemográficas de los estudiantes. Los resultados muestran que estas características de los estudiantes son relevantes en su desempeño académico en las Pruebas. Por su parte, la variable predictora estrato socioeconómico del colegio, no es significativa y no ayuda a explicar la variabilidad en el resultado en matemáticas de las pruebas Saber 11, debido a que parece razonable suponer que las condiciones socioeconómicas en la que vive cada estudiante no son muy diferentes de una institución a otra. De estos resultados se infiere la necesidad de comprometer a otras instituciones y entidades en la generación y desarrollo de políticas para mejorar las condiciones de la población en relación con tales características.
El factor institución resultó ser significativo para explicar la variabilidad de los resultados en matemáticas en las Pruebas Saber 11, de esto se infiere que hay diferencia significativa entre los puntajes medios de los colegios oficiales de Medellín. Lo anterior da cuenta de que, en general, los colegios reciben a los estudiantes de su entorno con poblaciones relativamente homogéneas. Esto quiere decir que los colegios tienen tendencia a recibir estudiantes similares en cuanto a sus condiciones sociodemográficas, pero si se comparan dos colegios diferentes se pueden encontrar grandes diferencias entre las características medias de sus poblaciones de estudiantes.
Conclusiones
Los resultados de este estudio mostraron que las modalidades de distribución del tiempo para la enseñanza de la estadística no están relacionadas, o son independientes estadísticamente, del resultado de los estudiantes en el componente de matemáticas de las Pruebas Saber 11. Además de ello, del estudio también se deriva que después de controlar el efecto institución, algunas variables específicas de los estudiantes tales como su edad, género y estrato socioeconómico, sí inciden en los resultados obtenidos en matemáticas en las Pruebas Saber 11, en tanto que (también después de controlar el efecto institución) las variables inherentes a los centros educativos como son el estrato socioeconómico del colegio y la distribución de la intensidad horaria en que se enseña la estadística y la jornada de la institución, no ayudan a explicar la variabilidad en los resultados en matemática en las Pruebas Saber 11.

