










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkAvances en Psicología Latinoamericana
versão impressa ISSN 1794-4724versão On-line ISSN 2145-4515
Av. Psicol. Latinoam. v.28 n.2 Bogotá jul./dez. 2010
Modelado basado en agentes: una herramienta para complementar el análisis de fenómenos sociales
Agent-based modeling: A tool for complementing the analysis of social phenomena
Ariel Quezada*
Enrique Canessa**
* Doctor. Profesor instructor, Universidad Adolfo Ibáñez, Facultad de Psicología, Viña del Mar, Chile. Correo electrónico: ariel.quezada@uai.cl.
** PhD, Profesor asociado, Universidad Adolfo Ibáñez, Facultad de Ingeniería y Ciencias, Viña del Mar, Chile. Correo electrónico: ecanessa@uai.cl.
Fecha de recepción: 13 de enero de 2009
Fecha de aceptación: 25 de agosto de 2010
Abstract
This paper shows the usefulness of Agent-based Modeling (AbM) for studying social phenomena. This tool saves time and resources, allowing us to analyze many variables and then select the most significant ones for proceeding with the study. This process is illustrated through a model which analyzes the time needed to treat sick people according to whether the treatment might be given in situ or at a hospital, whether health personnel might share or not information regarding patients location and, if the density of geographical distribution of sick people is high or low. The results reveal that exchanging information significantly shortens the time only for hospital treatments and that density does not have an impact. We conclude that AbM has great advantages for the design of social research and helps in the decision making process of practitioners.
Keywords: agent-based modeling, computer simulation, Netlogo, working teams.
Resumen
Este estudio busca mostrar la utilidad del modelado basado en agentes (MbA) para estudiar diferentes fenómenos sociales. Dicha herramienta economiza tiempo y recursos, permitiendo analizar muchas variables para posteriormente seleccionar las más significativas y proseguir así con la investigación. Lo anterior se ilustra con un modelo que analiza el tiempo requerido para encontrar y atender enfermos según sea su tratamiento: domiciliario u hospitalario, si el personal puede compartir o no información sobre localización de enfermos y si estos residen densamente o no. Los resultados revelan que compartir información acorta significativamente el tiempo sólo para tratamientos hospitalarios y que la densidad no tiene impacto. Concluimos que MbA tiene grandes ventajas para el diseño de investigaciones sociales y asiste a la toma de decisiones en contextos profesionales.
Palabras clave: modelado basado en agentes, simulación computacional, Netlogo, equipos de trabajo.
Introducción
Imagine que usted coordina un equipo de salud pública que debe realizar una campaña cuya misión es tratar una enfermedad. Para ello se debe diagnosticar in situ a la población, reportar y atender personas enfermas. El tratamiento de la enfermedad puede ser de dos tipos: requiere que las personas infectadas sean evacuadas de inmediato a un centro de atención o que las personas sean tratadas en el lugar. El objetivo que le han encomendado es crear una estrategia efectiva, que rápidamente permita detectar y tratar a la totalidad de los enfermos. Usted dispone de un personal reducido y sólo sabe que los enfermos están agrupados en ciertas localidades (unas muy densamente pobladas y otras poco densas), pero no sabe exactamente dónde está cada enfermo. Quizá esté frente a dos posibles situaciones: un personal que, por razones de presión de tiempo, carga de trabajo o imposibilidad de comunicación, no pueda compartir información de la localización de enfermos detectados; o bien un personal que tiene los recursos para compartir esta información oportunamente con sus compañeros de trabajo. Como todos esos factores tienen importantes consecuencias para atender oportunamente a la población y optimizar los recursos humanos, a usted le sería interesante contar con una herramienta que le permita analizar el impacto de estos factores sobre la misión definida.
Modelado basado en agentes para las ciencias Sociales
Frente a la problemática anterior, tanto un profesional como un investigador social desearían poder responder preguntas como las siguientes: ¿Cómo saber si compartir información o no será más eficiente en relación al manejo de la situación? Teniendo la misma cantidad de posibles enfermos ¿habrá diferencias en los tiempos de tratamiento si dichos enfermos viven en zonas de distinta densidad? ¿Afectará al resultado final si la enfermedad puede atenderse en el mismo lugar donde se encontró al enfermo o debe ser trasladado?
Sería deseable realizar una investigación empírica en el sistema real para poder tomar las mejores decisiones; sin embargo, la obtención de datos es una tarea lenta, difícil y costosa. Asimismo, probablemente se obtendría una pequeña cantidad de datos muy aislados en el tiempo, lo que no permitiría observar la influencia que diferentes acciones tienen sobre la evolución de la situación.
Sumado a lo anterior, la investigación social longitudinal con frecuencia se ve enfrentada a la mortalidad experimental, es decir, a la disminución de los participantes o de la muestra que originalmente se estaba observando, reduciendo drásticamente los alcances y generalización de los resultados obtenidos (Waizmann y Roussos, 2005). Esto también se agrava al realizar estudios en el sistema real, ya que generalmente existen muchas variables difíciles de controlar, lo que limita aún más la validez de los resultados (Zwijze-Koning y De Jong, 2005). Así mismo, si el coordinador de salud deseara incorporar muchas variables al análisis, resultaría difícil hacerlo, puesto que se necesitarían varios estudios capaces de manipular muchas variables. Esto último sería engorroso, ya que es fácil imaginar las dificultades para establecer, por ejemplo, una cierta cantidad de enfermos en un área. Incluso algunas variables podrían no ser manipulables en la realidad, ya sea por imposibilidad material o ética.
Establecer la proporción de profesionales de salud por cada persona es un ejemplo de una imposibilidad material. Por otra parte, una restricción ética alude a que las intervenciones reales podrían tener consecuencias sociales y/o políticas mayores. Así, el establecimiento de variables que permitan un explosivo aumento del contagio de una enfermedad, para probar escenarios posibles, sería una restricción ética. Sin embargo, hacer estos ejercicios, denominados "experimentos de pensamiento" (thought experiments), ayudaría al coordinador a entender más el fenómeno y eventualmente tomar mejores decisiones, tal como indica Axelrod (1997).
En un escenario como el anterior sería útil contar con una herramienta que permita visualizar preliminarmente consecuencias de intervenciones en el sistema real. También el coordinador podría usar dichos resultados para comunicar más claramente sus ideas a otros actores en la toma de decisiones. Esto permitiría una mejor discusión de iniciativas, revelando quizá aspectos inesperados del fenómeno. Incluso los experimentos de pensamiento podrían ayudar a focalizar futuros estudios empíricos, permitiendo la generación de hipótesis tentativas y seleccionar posibles variables a manipular, vislumbrando sus posibles consecuencias (Canessa y Riolo, 2006).
Implícita en la discusión anterior está la percepción de que incluir la mayor cantidad de variables en el modelado de un sistema podría abrigar la esperanza de predecir completamente el comportamiento de éste. Esta esperanza también se alimenta cuando se encuentra un sistema aparentemente muy simple, con pocas variables muy conocidas. Muchas veces situaciones sociales de aparente simpleza presentan comportamientos no triviales que se alejan de la intuición de una mirada cotidiana (Gell-Mann, 2004). Por ello, tener una herramienta que permita ver preliminarmente si las intuiciones son correctas, podría evitar los sesgos que éstas pueden provocar.
Una de las herramientas que ayuda a contrastar las intuiciones es la simulación. Esta técnica ha sido empleada en ciencias sociales desde hace varias décadas, por ejemplo, por el sociólogo Thomas C. Schelling (1978/1989) en sus estudios sobre dinámicas de segregación racial. A su vez, la teoría del impacto social, creada por el psicólogo Bibb Latané, emplea simulación computacional para reproducir la presencia de actitudes de un grupo (Latané, 1981; Latané, Nowak y Liu, 1994). Más ejemplos y detalles se pueden encontrar en los trabajos de Vallacher y Nowak (Vallacher y Nowak, 1994; Nowak y Vallacher, 1998), en la revista electrónica más relevante en el tema, Journal of Artificial Societies and Social Simulation (JASSS), en libros especializados (Gilbert y Troitzsch, 1999) y en el trabajo de sociedades científicas tales como European Social Simulation Association (ESSA) y North American Association for Computational Social and Organizational Sciences (NAACSOS). Cabe señalar que la simulación computacional ha sido poco explorada entre los investigadores sociales en Latinoamérica, aunque su uso en las ciencias sociales comenzó en la segunda mitad del siglo XX.
La simulación computacional consiste en construir un programa informático que represente a un sistema para luego experimentar con él y caracterizar así su comportamiento. En el modelado de fenómenos sociales usando simulación existen varias técnicas y herramientas. En el caso específico del modelado basado en agentes (MbA), éste se inicia originalmente con autómatas celulares (Gilbert y Troitzsch, 1999). Los autómatas celulares se asemejan a un tablero con cierta cantidad de celdas (autómatas), con un conjunto finito de valores posibles de estados que pueden ser modificados por la vecindad e interacción con otras celdas (autómatas), según las leyes definidas por el programador (Berlekamp, Conway y Guy, 1982; Vallacher y Nowak, 1997). En este caso la interacción entre autómatas genera las respuestas que luego serán analizadas por el investigador. A esta línea de investigación adscriben las experiencias ya mencionadas de Schelling (1978/1989) y de Latané (Latané, 1981; Latané, Nowak y Liu, 1994). Por otro lado, en el MbA, los agentes –a diferencia de los autómatas- pueden tener estados en los que se incluyen variadas características mucho más elaboradas, tales como preferencias, creencias, memoria de eventos recientes y conexiones sociales (Canessa y Riolo, 2006). Cabe aclarar que, en este sentido, un agente sería un sofisticado tipo de autómata celular o un rudimentario y limitado exponente de un agente. Para ver variados ejemplos de aplicación de agentes en el análisis de comportamientos sociales se puede profundizar en Canessa y Riolo (2003), Huberman y Glance (1998), So y Durfee (1998), Scacchi (1998), Stasser (2000), Suo y Chen (2008) y Zickar (2000).
La elección de MbA no es antojadiza ni arbitraria, sino que responde a la necesidad de una herramienta que describa el surgimiento de comportamientos del tipo Bottom Up, es decir, aquellos que emergen del funcionamiento y operación de unidades individuales. Esto llevado a las ciencias sociales significa que un comportamiento social se ve generado por el actuar de sujetos individuales en interacción y perturbación mutua. Es por esta razón que resulta tan natural y útil el uso de MbA en ciencias sociales, puesto que se puede estudiar cómo nace el comportamiento agregado de los agentes del sistema y, además, analizar el comportamiento individual de cada uno (Arrow, McGrath y Berdahl, 2000; McGrath, Arrow y Berdahl, 2000). Así, un MbA permite un fácil cambio en el nivel de análisis: se puede focalizar tanto en el nivel macro como en el micro.
En cuanto a inclusión de variables en un modelo, con el MbA se puede llegar de manera expedita a definir las variables más centrales que explican el comportamiento del sistema, sin realizar costosos experimentos en la realidad, lo que se traduce en una enorme economía de recursos. Incluso, como ya se dijo, en ocasiones los experimentos en el sistema real no podrían realizarse debido a limitaciones prácticas o éticas. Esto no significa que el MbA reemplaza a la experimentación en el sistema real, sino que la asiste y la complementa. Incluso algunos investigadores han llamado al MbA el tercer pilar de la investigación científica (Arrow, McGrath y Berdahl, 2000; Ilgen y Hulin, 2000), pues con éste se filtran las variables y comportamientos que luego se incluirán en estudios empíricos. Una vez obtenidos esos datos, estos se analizan inductivamente y, en base a las discrepancias encontradas, se refina el MbA. Este ciclo se repite hasta explicar adecuadamente el fenómeno bajo estudio.
A su vez, el MbA facilita la fertilización cruzada entre distintas ramas de la ciencia, ya que permite tender un puente entre las ciencias sociales y las naturales, facilitando la expresión algorítmica de teorías del comportamiento en un lenguaje afín al de las ciencias naturales. Esta interdisciplinariedad es la que alentó Piaget (1979) y que posteriormente ha sido un llamado constante en la investigación en ciencias sociales (Albus et al., 2007).
Por último, con un MbA se puede obtener una gran cantidad de puntos de las variables de salida, logrando un adecuado modelado de la dinámica de un sistema, lo que ayuda a comprender mejor el funcionamiento de éste.
No obstante, como toda herramienta, el MbA también tiene desventajas. El mayor problema con un MbA es su validación. Esto implica que, para poder utilizar el modelo y sacar conclusiones aplicables a un sistema real, los resultados del MbA deben acercarse suficientemente a los que se podrían obtener en el sistema real (Bankes, 2002; Grimm et al., 2005; Grimm y Railsback, 2005). El grado de similitud entre las salidas del MbA y del sistema real que debe alcanzarse dependerá del uso que se le vaya a dar al modelo. Usualmente la similitud que se puede alcanzar mediante MbA no permite hacer una predicción exacta del comportamiento futuro. Por ejemplo, el modelo de Arthur, Holland, LeBaron, Palmer y Tayler (1997), ayuda a entender cómo se comportan los mercados financieros y cómo se originan fenómenos tales como las "burbujas". Sin embargo, el modelo no puede usarse en el pronóstico de los valores exactos de los instrumentos financieros, para así lograr ganancias al transarlos. Si bien el MbA no permite hacer una predicción exacta del comportamiento del sistema, posibilita conocer la dinámica y tomar decisiones en relación a ella a quien lo usa. En el modelo mencionado, al entender la formación de burbujas, se pueden diseñar regulaciones al mercado bursátil que disminuyan la probabilidad de que éstas ocurran.
Asimismo, a medida que el modelo contiene muchas variables y los agentes tienen muchas reglas de comportamiento, se hace más arduo validarlo, puesto que existirá una gran combinatoria de valores que deberán probarse para ver si el modelo produce datos similares a los del sistema real. Lo anterior también dificultará corroborar que el modelo alcance cierta consistencia interna (exige que las reglas de comportamiento no sean contradictorias) y externa (requiere que el comportamiento del modelo coincida globalmente con resultados de modelos similares). Todo eso es importante en los sistemas sociales, ya que efectivamente pueden estar involucradas muchas variables, lo que dificulta su identificación y posterior inclusión en un MbA. Incluso si esto se pudiera hacer, complicaríamos al MbA a tal punto que sería difícil entender los resultados de éste (Axelrod, 1997). Por ello, generalmente los MbA se usan para comprender un sistema en lugar de predecir sus valores exactos (Axelrod, 1997). Para ello la validación consiste en alcanzar equivalencia relacional (Grimm y Railsback, 2005). Esto significa que el MbA debe reproducir cualitativamente el comportamiento de variables de salida del sistema real, bajo las mismas condiciones. La Tabla 1 presenta un resumen de las ventajas y desventajas más importantes del MbA respecto a investigaciones empíricas, tanto en laboratorio como en el sistema real.
Cabe destacar que el MbA requiere una plataforma de simulación con capacidad para crear agentes. La elección de la misma no es un proceso trivial y depende mucho del modelo que se vaya a desarrollar (Railsback, Lytinen y Jackson, 2007; Robertson, 2006). En general existen plataformas muy avanzadas, tales como Swarm y Repast, pero difíciles de usar para investigadores sin profundos conocimientos informáticos y de programación orientada al objeto. Por otro lado, la plataforma Netlogo ofrece una herramienta sencilla de instalar en computadores personales, con una interfaz de usuario muy amigable y con una excelente documentación. Mientras que con Swarm y Repast el tiempo requerido para poder comenzar a modelar es de días a semanas, con Netlogo un investigador sin conocimientos avanzados de programación requiere de solamente algunas horas para desarrollar un modelo (Robertson, 2006). Por otra parte, Railsback, Lytinen y Jackson (2007) y Robertson (2006) advierten que plataformas como Swarm y Repast permiten crear modelos complicados y/o muy sofisticados, mientras que con Netlogo se crean modelos más sencillos.
Tabla 1. Beneficios y limitaciones del MbA e investigación empírica
Si bien no es fácil desarrollar un modelo muy complicado con Netlogo, no implica necesariamente una desventaja, más aún, podría ser incluso un beneficio. Al diseñar conceptualmente el modelo, el investigador debe ponderar muy bien la cantidad de variables e interrelaciones que incluirá, ya que en MbA es bastante fácil incluir muchas variables, pensando que eso describirá mejor al sistema. Por el contrario, esto podría tan sólo complicarlo, sin aportar a una mejor representación del mismo. Aún más, el principio KISS (Keep It Simple Stupid, "mantenlo simple estúpido", o en su versión políticamente correcta Keep It Short and Simple, "mantenlo breve y simple") (Axelrod, 1997, 2008) recomienda que los modelos de agentes deben ser lo más simples posible, para que efectivamente ayuden a entender el fenómeno que modelan. Por ello se trata de usar una gran abstracción, por lo que el investigador siempre debería preguntarse si al incluir alguna variable o mecanismo extra en el modelo realmente ayudará al estudio del sistema real. Sin embargo, en esta descripción simple tampoco se debe llegar al extremo opuesto de reducir la complejidad propia del sistema al amputar variables y factores esenciales para su caracterización.
Para conocer cómo el MbA es una herramienta poderosa para ayudar a caracterizar la dinámica de colectivos sociales, se verá un ejemplo sencillo de su aplicación a la problemática inicial. Cabe destacar que el modelo que se presentará no pretende sacar conclusiones directamente aplicables a la situación descrita, puesto que no ha sido validado. Más bien, pretende aclarar la presentación anterior de MbA, al entregar una visión más ilustrativa de lo expuesto. Por ello se escogió un modelo sencillo, según recomendación de renombrados investigadores y docentes, que permite efectuar una buena introducción al MbA y presentar las bondades de esta herramienta para analizar comportamientos sociales.
Un ejemplo ilustrativo del uso de MbA
Todo MbA debe ser específico, para lo cual se requiere definir claramente el comportamiento de los agentes, la forma en que van a interactuar y el entorno donde coexistirán. En modelos sofisticados el entorno también puede presentar características especiales asociadas a grafos (Hamill y Gilbert, 2009) y patrones de comportamiento. En el presente modelo se ejemplificará un sistema con un entorno simple, que corresponde a una adaptación del citado por Wooldridge (2002) que, a su vez, es una modificación de un modelo creado por Steels en 1990. En resumen, el modelo representa estilizadamente a tres paramédicos de una organización de salud pública que deben ubicar enfermos y tratarlos. Dependiendo de la enfermedad, los enfermos deben ser atendidos trasladándolos a un hospital o bien pueden tratarse in situ. Los paramédicos pueden o no compartir información de la localización de enfermos. Así se configuran tres condiciones de las que se desglosan los tres factores analizados:
Lugar de tratamiento de la enfermedad: Los paramédicos realizan su trabajo de distinta manera dependiendo de: a) Tratamiento domiciliario: si la enfermedad puede ser tratada en el lugar, el paramédico lo hará y continuará buscando a otros enfermos en forma sucesiva, pudiendo atender hasta a 10 enfermos antes de tener que volver al hospital; y b) Tratamiento hospitalario: si la enfermedad requiere trasladar al enfermo para tratarlo, el paramédico lo ubica y luego lo acompaña al hospital.
Densidad: Los enfermos pueden hallarse distribuidos geográficamente de dos formas: a) Alta densidad: ubicados en zonas urbanas, con conglomerados densamente poblados (específicamente en este caso se estableció que existirían cinco (5) conglomerados de 100 enfermos cada uno, para un total de 500 enfermos en total); y b) Baja densidad: ubicados en zonas en las que viven pocas personas (25 conglomerados de 20 enfermos cada uno). Para nuestro modelo la topografía del área donde están distribuidos los enfermos es un toroide de 80 cuadrados por 80. La Figura 1 muestra una imagen de la pantalla de una corrida de la simulación. Cada cuadrado puede contener a un enfermo y el desplazamiento de los paramédicos se realiza moviéndose de un cuadrado a otro.
Intercambio de información: Respecto a los paramédicos, estos pueden trabajar compartiendo información entre sí o no hacerlo. Así se configuran dos condiciones, a) Intercambio de información: los paramédicos comparten entre sí información acerca de la localización de los enfermos. Para esto cada paramédico inicia una corrida de simulación moviéndose aleatoriamente desde el hospital (situado al centro del toroide) hasta coincidir geográficamente con un enfermo. Una vez que el paramédico ha detectado un enfermo, si lo puede tratar in situ lo hace, hasta completar diez tratamientos, y regresa al hospital. Si no lo puede tratar in situ, lo traslada al hospital. En ambos casos el paramédico deja una huella de regreso al grupo de enfermos, lanzando dos marcas en su camino al hospital. Dicha huella puede ser seguida por cualquiera de los tres paramédicos para ir adonde están los enfermos. Para que los paramédicos no sigan una huella que los conduzca a grupos de enfermos que ya han sido tratados, ésta se va debilitando cada vez que un paramédico la sigue. Para esto, si un paramédico sigue una huella, va tomando una marca de la misma.
La segunda condición es b) no hay intercambio de información: es aquella en la cual los paramédicos no comparten información entre sí, siendo su comportamiento similar al explicado anteriormente excepto que las huellas de cada paramédico pueden ser reconocidas y seguidas solamente por aquel que la dejó (situación que se muestra en la Figura 1, ya que cada huella es de distinto color y sólo el paramédico de ese mismo color puede reconocerla). Es decir, las huellas son de uso exclusivo del paramédico que las trazó. En este caso puede suceder que, al ir dejando una huella, un paramédico pase por encima de la huella de otro funcionario, borrando esa parte de esta segunda huella, tal cual se aprecia en la figura a continuación. Aunque esto se hace sin intención, esta característica representa las interferencias mutuas involuntarias que pueden existir en toda actividad humana en la que participan varias personas.
En la Figura 1 se puede apreciar la interfaz gráfica del simulador Netlogo versión 4.0.2 (Wilensky, 2007).1 En la parte derecha de la pantalla se ubica la representación bidimensional espacial del modelo, que muestra a los paramédicos y los conglomerados de enfermos, junto con las huellas dejadas por cada uno de los tres paramédicos (rojo, verde y amarillo). En la parte izquierda superior se encuentran dos botones azules que sirven para establecer las condiciones iniciales de la corrida (CONFIGURAR) y otro botón que permite comenzar y terminar una corrida de simulación (SIMULAR). Este botón también permite pausar la corrida a voluntad, sin perder el estado interno de la misma. Más abajo se ubican cuatro controles verdes que permiten establecer las condiciones iniciales de cada corrida. Particularmente para este modelo, cada control (en orden descendiente) permite establecer si los paramédicos pueden compartir información o no, el número de conglomerados de enfermos, el número de enfermos por cada conglomerado (ambos parámetros representan el factor densidad) y el lugar de tratamiento de la enfermedad (hospitalario si se establece que los agentes ubican a un enfermo y regresan al hospital; domiciliario si se establece que los agentes tratan a diez enfermos antes de regresar al hospital).
Situadas debajo de dichos controles se ubican unas ventanas que van mostrando una serie de variables del modelo a medida que avanza la corrida. En este caso las ventanas muestran la cantidad de pasos de simulación transcurridos desde el inicio de la corrida, la cantidad de enfermos que aún no han sido tratados y la cantidad de enfermos ya tratados. Finalmente, el gráfico ubicado en la zona inferior izquierda muestra la cantidad de enfermos tratados respecto al tiempo de simulación transcurrido, medido en pasos. Cabe destacar que la cantidad, funcionalidad, nombre y ubicación de todos los botones de control y ventanas de información y gráficos son totalmente definibles y configurables por el modelador.
Para analizar el modelo se realizaron simulaciones correspondientes a las ocho combinaciones de niveles posibles según los factores descritos: tratamiento domiciliario u hospitalario, alta o baja densidad e intercambio o no de información. Se efectuaron diez réplicas para cada combinación de tratamiento, lo que da un total de 80 corridas. Para efectuar dichas corridas se empleó la herramienta "Behaviorspace" de Netlogo, que simplifica y especifica notablemente esta tarea. La respuesta analizada es el tiempo que demoran los paramédicos en tratar a todos los enfermos, medido en cantidad de pasos de simulación. Nótese que se ocuparon pocas combinaciones de tratamiento y réplicas, lo que equivale a una limitada exploración del espacio de parámetros. Esta decisión favorece a que el modelo se muestre de manera más didáctica. No obstante, si se desean obtener conclusiones más sustantivas, se requiere aumentar tanto el número de combinaciones de tratamiento como el de réplicas.
A continuación se presentan los resultados del análisis de los datos obtenidos, privilegiando los resultados cualitativos sobre los cuantitativos, ya que se estima más apropiado para el propósito de este artículo. La Figura 2 muestra los tiempos promedio para las cuatro combinaciones de los factores "lugar de tratamiento" e "intercambio de información".
Se aprecia que los tiempos de los tratamientos domiciliarios son menores que los hospitalarios. Analizando el modelo, esto se explica ya que para los tratamientos domiciliarios el paramédico puede tratar a muchos enfermos (10) sin tener que volver al hospital. En cambio, para tratamientos hospitalarios, la atención es de un enfermo por vez. En consecuencia, en esta última situación el paramédico debe incurrir en más tiempo de viaje de ida y vuelta al hospital por cada tratamiento realizado.
A su vez se ve que, al poder intercambiar información de localización de enfermos, el tiempo total de tratamiento disminuye. Esto se explica por dos motivos. Primero, si los paramédicos comparten información entre ellos se invierte menos tiempo en localizar nuevos enfermos o, dicho de otra forma, se utiliza más la información de localización de enfermos ya ubicados por los paramédicos. Segundo, los paramédicos que no pueden intercambiar información se interfieren entre sí, pues borran la información (la huella) que permite a otros paramédicos volver al lugar donde podrían estar localizados otros enfermos, tal vez próximos a los enfermos ya encontrados. Aunque esta interferencia es involuntaria, hace que estos paramédicos ocupen menos eficientemente la información de localización de enfermos en comparación con los paramédicos que pueden intercambiar información.
Figura 1. Imagen captada de la pantalla del sistema en una corrida de simulación de paramédicos que no pueden intercambiar información sobre la localización de los enfermos.
Observe también que la Figura 2 revela una característica adicional de las combinaciones de los dos factores mostrados. Existe una diferencia notable del tiempo necesario para tratar a todos los enfermos cuando su tratamiento es hospitalario (diferencia = 21271 – 13323 = 7948 pasos); sin embargo, dicha diferencia es comparativamente muchísimo menor en el caso de tratamientos domiciliarios (diferencia = 6241 – 5639 = 602 pasos). Es decir, los paramédicos que pueden intercambiar información son más eficientes para los tratamientos hospitalarios que los que no pueden hacerlo. No obstante, para tratamientos domiciliarios es prácticamente lo mismo que los paramédicos puedan o no intercambiar información. Esto sucede porque en estos últimos los paramédicos pueden atender a muchos enfermos sin tener que regresar al hospital, y si encuentran enfermos en una zona pueden realizar los tratamientos sin desperdiciar tiempo en regresar cada vez que realizan un tratamiento. Asimismo, compartir la localización de enfermos con otros paramédicos no es muy importante puesto que, cuando se encuentra un enfermo, probablemente halle otros cercanos y pueda realizar varios tratamientos seguidos. En cambio, si se requiere tratamiento hospitalario, el paramédico debe volver al hospital cada vez y regresar luego al área donde se encuentran los demás enfermos. Por ello, si se comparte la información de localización de enfermos entre los paramédicos aumenta la probabilidad de que otros puedan volver al lugar donde están los enfermos restantes.
Finalmente, cabe destacar que, contrario a lo que se podría pensar en un principio, la densidad no afecta mucho el tiempo total de tratamiento. Intuitivamente pareciera que a mayor densidad de enfermos sería más fácil para los paramédicos alcanzar a la totalidad de ellos. Pero una vez que se encuentra un conglomerado de enfermos, los paramédicos se pueden dedicar a tratar a los que se encuentran cercanos. Además, esto se facilita si los paramédicos comparten la información de localización entre ellos. Sin embargo, un análisis más profundo del modelo indica que existen otras particularidades asociadas a lo anterior.
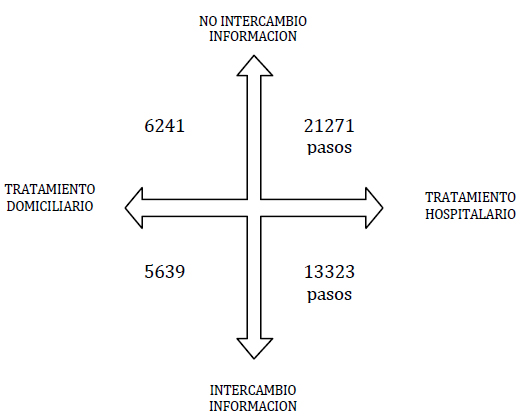
Figura 2. Promedio del tiempo total de tratamiento de los enfermos correspondiente a las combinaciones de los factores "intercambio de información" y "lugar de tratamiento"
Primero, si los enfermos están localizados densamente, el hallazgo inicial de éstos toma más tiempo que si los enfermos están geográficamente más dispersos. Esto se da ya que los paramédicos parten buscando en toda el área en forma aleatoria. Dicha situación tiende a anular los beneficios que trae una alta densidad de enfermos, posterior al hallazgo de los conglomerados. Es decir, antes de explotar la densidad de los conglomerados es necesario ubicarlos, lo que tiende a diluir el efecto beneficioso de una alta densidad. Segundo, y como se explicó al describir el modelo, cada vez que un paramédico hace uso de una huella para volver a un conglomerado de enfermos, la va debilitando. Esto evita que se sobreexploten dichos conglomerados, o sea, que un paramédico siga una huella hacia un conglomerado y encuentre que todos los enfermos que viven allí ya han sido tratados, lo que constituiría un desperdicio de tiempo. Eso resta relevancia a que los enfermos estén localizados densamente o no, ya que el debilitamiento de la información de ubicación de enfermos diluye el efecto beneficioso de la alta densidad.
Todo lo anterior se ve reflejado en que la diferencia del tiempo promedio de tratamiento cuando existe una alta densidad a cuando hay una baja sea relativamente pequeña (diferencia = 311 pasos) respecto a las anteriores (7948 y 602 pasos).
Aquí cabe preguntarse si la intuición inicial es incorrecta o sería el modelo. Esto es parte del ciclo de refinamiento del sistema, ya que si los resultados concuerdan con la intuición esto podría significar que el modelo representa adecuadamente al sistema real. De no concordar el sistema con la intuición habría dos alternativas: a) cambiar el modelo forzándolo a seguir la intuición del modelador, o b) aceptar que la intuición original estaba incorrecta.
Discusión y conclusiones
A lo largo de este artículo se han presentado las ventajas que aporta el modelado basado en agentes al análisis de fenómenos sociales. Dentro de las virtudes del MbA, en cuanto a la economía que le reporta al investigador social, se destaca el hecho que se necesita muy poco tiempo para desarrollar, diseñar y ejecutar la experimentación de un modelo dado. En este caso, el tiempo de desarrollo del modelo, incluida la instalación de Netlogo y su aprendizaje, fue de aproximadamente 60 horas de trabajo (unos 7.5 días laborales), de los cuales su programación tardó unas 40 horas.
Por otra parte, se puede apreciar que el MbA resulta un excelente medio para auxiliar el diseño de experimentos que se ejecutarán más tarde en el sistema real: diseñar y escoger las variables con más peso en el sistema, proponer hipótesis de qué va a pasar, focalizar en aquellos aspectos que se medirán en el procedimiento real. En el presente modelo se pudo determinar qué factores tenían mayor incidencia en los resultados finales. En particular se estableció que el lugar de tratamiento de la enfermedad y el intercambio de información entre paramédicos tienen una gran influencia sobre el tiempo para tratar a la totalidad de la población enferma, por sobre la poca significación que tuvo la densidad de la población.
Se apreció también la interacción entre variables. En el modelo presentado se vio que el impacto del intercambio de información sobre el tiempo es relevante sólo para los tratamientos hospitalarios. Es decir, el efecto de una variable sobre la respuesta se ve afectado por el valor de otra variable y viceversa. Esto también pone en evidencia que incluso con la gran simpleza de este modelo se puede llegar a resultados no necesariamente intuitivos: no se esperaba encontrar el efecto de interacción recién mencionado ni tampoco que el factor densidad no fuera significativo. Esto fue apreciado analizando el modelo a nivel macro y luego, con una mirada a nivel micro, se entendieron las razones por las que esto sucede. Aquí radica el valor de los experimentos de pensamiento, ya que con el modelo ahora se entiende mejor la situación planteada, lo que ayudará a realizar estudios futuros en el sistema real. En este caso tal vez no interese incluir el factor densidad, pero sin mucho esfuerzo podrían agregarse otros, como por ejemplo simular el contagio de la enfermedad, lo que constituye un proceso de filtrado de variables.
Además de simular contagio, el lector podría pensar incluir una serie de otros factores que estima incidirían en la respuesta del sistema, lo que cuestionaría la simpleza del modelo. No obstante, complicar el sistema incluyendo una gran cantidad de variables no necesariamente aporta al proceso ni al análisis de éste. Esto significa que el modelo presentado puede mejorarse, pero debería hacerse resguardando siempre la simpleza, aplicando el clásico y simpático principio KISS (Axelrod, 1997), el cual invita a definir un modelo de la manera más simple posible, favoreciendo el mejor entendimiento del fenómeno que se estudia. Por otra parte, debemos recordar que para extraer conclusiones sustantivas, el modelo debe alcanzar consistencia interna y externa, conjuntamente con ser validado, lo que se torna difícil si se incluye demasiadas variables y comportamientos en este. De todas formas, en el ciclo de refinamiento del modelo debe analizarse si los resultados concuerdan con la intuición; de lo contario se debería resolver si se cuestiona al modelo (y éste se debe modificar) o bien la intuición era incorrecta. En relación a la plataforma de simulación empleada, se destaca que Netlogo se erige como una herramienta tremendamente poderosa y, al mismo tiempo, fácil de usar y dominar, que funciona con fuente abierta (es decir, costo cero) bajo las plataformas informáticas más difundidas en la investigación social: PC y Macintosh.
La utilidad del MbA no se agota en absoluto en la investigación social sino que, tal como se insinúa al comienzo de este artículo, también es de gran ayuda para un planificador social, quien con muy poco esfuerzo y recursos puede tener un vistazo preliminar de sus intuiciones relacionadas con el fenómeno de su interés. Es así como varias conclusiones extraídas del modelo pueden servir de antecedentes preliminares para que el planificador tome decisiones. Por ejemplo, si la enfermedad requiriera tratamiento hospitalario sería bueno disponer de medios para que los paramédicos puedan intercambiar información de localización de enfermos, no pareciendo tan crítico en el caso de tratamientos domiciliarios. También el planificador no tendría que invertir demasiados recursos para medir y considerar en sus decisiones la densidad geográfica de los enfermos. Las anteriores consideraciones serían aún más significativas, si el modelo se somete a equivalencia relacional.
Finalmente, y sin que el MbA se constituya como un instrumento que reemplace a la experimentación en contextos reales o que permita pronósticos acabados y exactos del comportamiento de sistemas sociales, el argumento central de este artículo es precisamente presentar una herramienta que favorezca la comprensión de diversos fenómenos sociales tanto desde una perspectiva de investigación como también ligada a la práctica profesional.
Agradecimientos
Agradecemos a Rick L. Riolo, del Centro para el Estudio de Sistemas Complejos (CSCS, por sus siglas en inglés), y a Robert Axelrod, del Departmento de Ciencia Política del mismo Centro y a Gerald R. Ford, de la Escuela de Política Pública, todos de la Universidad de Michigan, por el intercambio de ideas respecto a este artículo.
NOTA
1. Aquellos lectores interesados en experimentar con el modelo son bienvenidos a contactar a cualquiera de los dos autores, quienes gustosamente enviarán por correo electrónico el modelo computacional.
Referencias
1. Albus, J. A.; Bekey, G. A.; Holland, J. H.; Kanwisher, N. G.; Krichmar, J. L.; Mushkin, M.; Modha, D. S.; Raichle, M. E.; Shepherd, G. M. y Tononi, G. "A Proposal for a Decade of the Mind Initiative". Science, 317, (2007), 1321-1322. [ Links ]
2. Arthur, W.B.; Holland, J.; LeBaron, B.; Palmer, R.; y Tayler, P. "Asset Pricing Under Endogenous Expectations in an Artificial Stock Market", en: B. Arthur, S. N. Durlauf y D. Lane (Eds.). The Economy as an Evolving Complex System II, SFI Studies in the Science of Complexity, Vol. XXVII, Reading, MA: Addison-Wesley, (1997). [ Links ]
3. Arrow, H.; McGrath, J. E., y Berdahl, J. L. Small Groups as Complex Systems: Formation, Coordination, Development and Adaptation. London: SAGE, (2000). [ Links ]
4. Axelrod, R. Advancing the Art of Simulation in the Social Sciences. en: R. Conte, R. Hegselmann y P. Terna (eds.). Simulating Social Phenomena. Berlin: Springer-Verlag, (1997). [ Links ]
5. Axelrod, R. "Advancing the Art of Simulation in the Social Sciences", en prensa en: Handbook of Research on Nature Inspired Computing for Economy and Management, Jean Philippe Rennard (Ed.), Hershey, PA: Idea Group, (2008). Disponible en: www-personal.umich.edu/~axe/research/AdvancingArtSim2005.pdf [ Links ]
6. Bankes, S. C. "Agent-Based Modeling: A Revolution?". Proceedings of the National Academy of Sciences of the USA, 99 (3), (2002), 7199–7200. [ Links ]
7. Berlekamp, E.; Conway, J. y Guy, R. Winning ways for your mathematical plays, Games in Particular, 2, London: Academic Press, (1982). [ Links ]
8. Canessa, E. y Riolo, R. "The effect of Organizational Communication Media on Organizational Culture and Performance: An agent-based Simulation Model". Computational and Mathematical Organization Theory, 9 (2), (2003), 147-176. [ Links ]
9. Canessa, E. y Riolo, R. "An Agent-based Model of the Impact of Computer-mediated Communication on Organizational Culture and Performance: an Example of the Application of Complex Systems Analysis Tools to the Study of CIS. Journal of Information Technology, 21, (2006), 272-283. [ Links ]
10. Gell-Mann, M. "Simplicidad y complejidad", en: A. Fischer (Ed.). Nuevos paradigmas a comienzos del tercer milenio. Santiago de Chile: Aguilar Chilena de Ediciones, S. A., (2004). [ Links ]
11. Gilbert, N. y Troitzsch, K. Simulation for the Social Scientist. Buckingham, England: Open University Press, (1999). [ Links ]
12. Grimm, V.; Revilla, E.; Berger, U.; Jeltsch, F.; Mooij, W. M.; Railsback, S. F.; Thulke, H. H.; Weiner, J.; Wiegand, T. Y Deangelis, D. L. "Pattern-Oriented Modeling of Agent-Based Complex Systems: Lessons from ecology". Science, 310 (5750), (2005), 987–991. [ Links ]
13. Grimm, V. y Railsback, S. F. Individual-Based Modeling and Ecology. Princeton, NJ: Princeton University Press, (2005). [ Links ]
14. Hamill, L. y Gilbert, N. "Social Circles: A Simple Structure for Agent-Based Social Network Models". Journal of Artificial Societies and Social Simulation, 12, (2009), 2-3, en: http://jasss.soc.surrey.ac.uk/12/2/3.html [ Links ]
15. Huberman, B. y Glance, N. "Fluctuating efforts and sustainable cooperation", en: M.J. Prietula, K.M. Carley y L. Gasser (eds.). Simulating Organizations. Cambridge MA: The MIT Press, (1998). [ Links ]
16. Ilgen, D. R. y Hulin, Ch. L. Computational Modeling of Behavior in Organizations. Washington D.C.: American Psychological Association, (2000). [ Links ]
17. Latané, B. "The Psychology of Social Impact". American Psychologist, 36, (1981), 343-365. [ Links ]
18. Latané, B.; A. Nowak y J. H. Liu. "Measuring Emergent Social Phenomena -Dynamism, Polarization and Clustering as Order Parameters of Social Systems". Behavioural Science, 39, (1994), 1-24. [ Links ]
19. McGrath, J. E.; Arrow, H. y Berdahl, J. L, "The Study of Groups: Past, Present, and Future". Personality & Social Psychology Review, 4 (1), (2000), 95-105. [ Links ]
20. Nowak, A. y Vallacher, R. R. Dynamical Social Psychology. New York: The Guilford Press, (1998). [ Links ]
21. Piaget, J. "Relations between Psychology and Other Sciences". Annual Review of Psychology, 30 (1), (1979), 1-8. [ Links ]
22. Railsback, S.; Lytinen, S. y Jackson, S. "Agent-based Simulation Platforms: Review and Development Recommendations", en prensa en Simulation, (2007). Disponible en www.humboldt.edu/~ecomodel/documents/ABMPlatformReview.pdf [ Links ]
23. Robertson, D. "Agent-Based Modeling Toolkits NetLogo, RePast, and Swarm". Academy of Management Learning & Education, 4 (4), (2006), 525-527. [ Links ]
24. Scacchi, W. "Modeling, Simulating, and Enacting Complex Organizational Processes: A Life Cycle Approach", en: M.J. Prietula, K.M. Carley y L. Gasser (eds.) Simulating Organizations. Cambridge MA: The MIT Press, (1998). [ Links ]
25. Schelling, T. Micromotivos y macroconducta. México, D. F.: Fondo de Cultura Económica, S. A. de C. V. (Orig. 1978), (1989). [ Links ]
26. So, Y. y Durfee, E. H. "Designing organizations for computational agents", en: M.J. Prietula, K.M. Carley y L. Gasser (eds.) Simulating Organizations. Cambridge MA: The MIT Press, (1998). [ Links ]
27. Suo, S. y Chen, Y. "The Dynamics of Public Opinion in Complex Networks". Journal of Artificial Societies and Social Simulation, 11, (2008), 4-2, en: http://jasss.soc.surrey.ac.uk/11/4/2.html [ Links ]
28. Stasser, G. "Information Distribution, Participation, and Group Decision: Exploration with the DISCUSS and SPEAK models", en: D. R. Ilgen y C. L. Hulin (Eds.). Computational Modeling of Behavior in Organizations. Washington D.C.: American Psychological Association, (2000). [ Links ]
29. Steels, L. "Cooperation between distributed agents though self organization", en: Y. Demazeau y J. P- Muller (eds.). Decentralized AI Proceedings of the 1st European Workshop on Modelling Autonomous Agents in a Multiagent World (MAAMAW-89), Elsevier, Amsterdam, (1990), pp.175-196. [ Links ]
30. Vallacher, R. R. y Nowak, A. Dynamical Systems in Social Psychology. San Diego: California: Academic Press, Inc, (1994). [ Links ]
31. Vallacher, R. R. y Nowak, A. "The Emergence of Dynamical Social Psychology". Psychological Inquiry, 8 (2), (1997), 73-99. [ Links ]
32. Vallacher, R. R. y Nowak, A. Dynamical Social Psychology. New York: The Guilford Press, (1998). [ Links ]
33. Waizmann, V. y Roussos, A. J. "Preparación de artículos científicos en psicología clínica", Documento de Trabajo N ° 135, Universidad de Belgrano, (2005). Disponible en: http://www.ub.edu.ar/investigaciones/dt_nuevos/135_waizmann.pdf [ Links ]
34. Wilensky, U. Netlogo. Disponible en: http://ccl.northwestern.edu/netlogo/. Center for Connected Learning and Computer-Based Modeling. Evanston, IL: Northwestern University, (2007). [ Links ]
35. Wooldridge, M. An Introduction to Multiagent Systems. Chichester, England: J. Wiley, (2002). [ Links ]
36. Zickar, M. "Modeling Faking on Personality Tests", en: D. R. Ilgen y Ch. L. Hulin (eds.). Computational Modeling of Behavior in Organizations. Washington D.C.: American Psychological Association, (2000). [ Links ]
37. Zwijze-Koning, K. H. y De Jong, M. D.T. "Auditing Information Structures in Organizations: A Review of Data Collection Techniques for Network Analysis". Organizational Research Methods, 8 (4), (2005), 429–453. [ Links ]

