










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkAvances en Psicología Latinoamericana
Print version ISSN 1794-4724On-line version ISSN 2145-4515
Av. Psicol. Latinoam. vol.29 no.2 Bogotá June/Dec. 2011
Normas de terminación para la palabra final de oraciones en español para niños mexicanos
Termination norms for final words of Spanish sentences for mexican children
Normas de terminação para a palavra final de orações em espanhol para crianças mexicanas
MARIO RODRÍGUEZ-CAMACHO*, BELÉN PRIETO-CORONA, MARGARITA BRAVO, ERZSÉBET MAROSI, JORGE BERNAL, GUILLERMINA YÁÑEZ
* Neurociencias. FES Iztacala. Universidad Nacional Autónoma de México. Mario A. Rodríguez Camacho es profesor del programa de Maestría y Doctorado en Psicología de la Universidad Nacional Autónoma de México (UNAM). Trabaja en la Facultad de Estudios Superiores de Iztacala en la línea de investigación de psicofisiología de los procesos cognoscitivos. Correspondencia: Neurociencias, Facultad de Estudios Superiores Iztacala, UNAM, Av. de los Barrios No. 1, Los Reyes, Iztacala, Tlalnepantla, Edo. Méx. CP 54090, México. Fax: 53.90.76.04. E-mail: marcizta@gmail.com.
Fecha de recepción: 4 de abril de 2011
Fecha de aceptación: 19 de septiembre de 2011
Resumen
Las normas de terminación de oraciones son un recurso valioso para los investigadores interesados en el estudio de los efectos que tiene un contexto sobre los procesos de reconocimiento de palabras y la comprensión del lenguaje en general. Este estudio presenta las normas de terminación para la palabra final de 278 oraciones en español para niños mexicanos, obtenidas a través del método de cloze, en una muestra de 420 estudiantes (226 niños y 194 niñas) de 9 a 12 años de edad, del 4° al 6° grado de primarias públicas del Estado de México. La tarea de los niños consistió en leer cada una de las oraciones y completarlas con una palabra al cierre. Se calculó la probabilidad de cierre de cada palabra respondida para cada uno de los contextos, de acuerdo con las respuestas de los niños. Aunque el corpus incluyó oraciones con diferentes restricciones contextuales, la respuesta de los sujetos mostró un mayor número de oraciones con alta probabilidad de cierre. Este material puede ser utilizado en la investigación sobre la comprensión del lenguaje tanto auditivo como escrito en niños.
Palabras clave: normas de terminación, oraciones, niños, español.
Abstract
Sentence completion norms are a valuable resource for researchers interested in the study of the effects of context in word recognition processes and language comprehension. This study presents completion norms for 278 sentences-final words in Spanish for Mexican children. These norms were obtained through the cloze method in a sample of 420 students (226 boys and 194 girls) 9 to 12 years old, from fourth to sixth grades of elementary public schools located in Estado de México. Children's task was to read each one of the sentences and completed them with one closing word. According to children's responses, cloze probability of each closing word was calculated for each sentence context. Although the set of sentences included different contextual constraints, subject's responses showed a greater number of sentences with high cloze probability. This corpus can be used in research on language comprehension (both oral and written) in children.
Keywords: termination norms, sentences, children, Spanish.
Resumo
As normas de terminação de orações são um recurso valioso para os pesquisadores interessados no estudo dos efeitos que tem um contexto sobre os processos de reconhecimento de palavras e a compreensão da linguagem em geral. Este estudo apresenta as normas de terminação para a palavra final de 278 orações em espanhol para crianças mexicanas, obtidas através do método de Cloze, em uma amostra de 420 estudantes (226 meninos e 194 meninas) de 9 a 12 anos de idade, do 4° ao 6° grau do ensino primário público do Estado de México. A tarefa das crianças consistiu em ler cada oração e completá-la com uma palavra no fecho. Calculou-se a probabilidade de fecho de cada palavra respondida para cada um dos contextos, conforme as respostas das crianças. Mesmo que o corpus incluiu orações com diferentes restrições contextuais, a resposta dos indivíduos mostrou um maior número de orações com alta probabilidade de fecho. Este material pode ser utilizado na pesquisa sobre a compreensão da linguagem tanto auditiva como escrita em crianças.
Palavras chave: normas de terminação, orações, crianças, espanhol.
Introducción
En psicolingüística se sostiene que la comprensión del lenguaje, tanto en la audición como en la lectura, se efectúa mediante el procesamiento de cada palabra o de cada oración, que apunta a la elaboración de una representación mental integrada en la cual la información literal se interpreta a la luz de los conocimientos previos del oyente o del lector (Fayol, 2003). El estudio de las relaciones entre la comprensión del significado y el procesamiento de palabras individuales ha sido de gran interés en investigaciones psicolingüísticas, concluyéndose que los humanos generan expectativas a partir de la información lingüística que están recibiendo (Condemarín y Milicic, 1990; DeLong, Urbach y Kutas, 2005; Otten, Nieuwland y Van Berkum, 2007; Otten y Van Berkum, 2007; Pickering y Garrod, 2007; Wicha, Bates, Moreno y Kutas, 2003).
Para estudiar los efectos del contexto semántico se ha utilizado la tarea de terminación de oraciones que -tradicionalmente- consiste en pedir a los participantes que lean un conjunto de oraciones a las que les falta la palabra final, y las completen con "la primera palabra que les venga a la mente" (método de cloze de Taylor, 1953, p. ej. "El doctor explora al..."). Las palabras omitidas serán restituidas por el lector a partir de las claves sintácticas y semánticas dadas por el contexto (Bloom y Fischler, 1980; McDonald y Tamariz, 2002; Taylor, 1953). Las respuestas obtenidas de esta manera permiten el cómputo de la "probabilidad de cierre" (cloze probability), que se define en términos del porcentaje de sujetos que usan una palabra determinada como terminación adecuada para un contexto de oración (Bloom y Fischler, 1980; Kutas y Van Petten, 1988; Taylor, 1953). Este proceso refleja los efectos que emergen desde niveles múltiples de restricciones (sintáctico, semántico y pragmático) que guiarán la elección de una palabra para cerrar un contexto específico (Connolly, Phillips y Forbes, 1995; Lahar, Tun y Wingfield, 2004). Así, si el contexto de oración es de fuerte restricción (sólo permite una o muy pocas palabras para su terminación) la "probabilidad de cierre" de esa palabra será mayor que si el contexto es de baja restricción (permitiendo varias terminaciones posibles) (Schwanenflugel y LaCount, 1988).
Este procedimiento ha sido utilizado en diversas investigaciones sobre lectura y lenguaje, que permiten concluir que las palabras sucesivas en un mensaje son percibidas e interpretadas de acuerdo con el contexto semántico-sintáctico que se va estableciendo. La presentación de ciertos estímulos léxicos con anterioridad a una palabra crítica pueden facilitar (o dificultar) su reconocimiento, si tienen una relación semántica, sintáctica, fonológica, etc., con dicha palabra (Belinchón, Igoa y Rivière, 1994).
El contexto de una oración "prepara el camino" para una palabra en particular. Al efecto del contexto (i.e. semántico, sintáctico, etc.) sobre el procesamiento de una palabra se le llama priming. Este fenómeno se ha demostrado conductualmente con menores tiempos de reacción para la identificación de palabras congruentes con el contexto, comparadas con palabras incongruentes o neutras (Stanovich y West, 1983). En los niños se ha encontrado que esta facilitación es mayor que en los adultos, es decir, los niños dependen más de la información contextual para el reconocimiento de las palabras leídas (Schwantes, 1985). Los estudios anteriores se han beneficiado de datos normativos de terminación. Las normas de terminación (o de completación) de oraciones consisten típicamente de contextos oracionales con las palabras más frecuentes que se producen para completarlos. Estos contextos se disponen en listados que se inician con los de fuerte hasta los de baja restricción contextual.
De igual manera, en el campo de la producción del lenguaje se ha estudiado el grado en que un contexto oracional restringe la palabra final de la oración y cómo interactúa esto con la frecuencia de uso de la palabra (Griffin y Bock, 1998). Qué tan predecible es la palabra final de una oración dado un contexto, ha sido una variable de interés. Stanovich y West (1983) reportaron un efecto del contexto en la latencia de nominación de palabras finales no esperadas y Schwanenflugel y LaCount (1988) demostraron una interacción entre el grado de restricción contextual y la predictibilidad de la palabra final, y afirmaron que los contextos de alta restricción permitían la facilitación de un conjunto de palabras finales más restringido lo que las hacía más predecibles comparadas con las que cerraban los contextos de baja restricción.
En niños se han mostrado los cambios relativos a la influencia del contexto en el reconocimiento de palabras a medida que desarrollan la fluidez en la lectura. Los lectores de menor edad dependen más del contexto para realizar el reconocimiento de palabras, en tanto que los lectores mayores y los adultos muestran habilidades cada vez más automatizadas en dicho reconocimiento (West y Stanovich, 1978; West, Stanovich, Feeman y Cunningham, 1983).
A lo largo del desarrollo, la estructura de la memoria semántica del niño se transforma, con el aumento del vocabulario, así como con la riqueza y accesibilidad a sus representaciones (p. ej., Gathercole, Willis, Emslie y Baddeley, 1992; Munson, Swenson y Manthei, 2005; Pinheiro, Soares, Comesaña, Niznikiewicz y Gonçalves, 2010; Storkel, 2002; Swingley, 2003). Adicionalmente, se afirma que estos cambios se basan en la interacción dinámica de factores individuales (maduración) y ambientales (educación) (ver Thomas y Karmiloff-Smith, 2003).
Las normas de terminación de oraciones son un valioso recurso en diferentes áreas de investigación que abarcan la psicolingüística, la estructura de la memoria y la neurociencia cognoscitiva (p. ej., Federmeier, McLennan, de Ochoa y Kutas, 2002; Griffin y Bock, 1998; Lahar et al., 2004; Stanovich y West, 1983), cuyo objetivo es el entendimiento de los mecanismos subyacentes a la comprensión y producción del lenguaje.
En el campo de la neurociencia cognoscitiva se han empleado las normas de terminación en el estudio fisiológico de los procesos neuronales de comprensión del lenguaje. Conocer la dinámica temporal de dicho proceso es crucial en la investigación de las diferentes suposiciones hechas por los modelos secuenciales o interactivos del lenguaje (Brown, Hagoort y Kutas, 2000). Para ello, se ha utilizado la técnica de los potenciales relacionados con eventos (PRE), cuyo componente N400 se ha relacionado consistentemente con el procesamiento semántico del lenguaje (Kutas y Federmeier, 2011). En su experimento clásico, Kutas e Hillyard (1980) presentaron para su lectura, oraciones que aparecían palabra por palabra en el centro de una pantalla. La palabra final de cada oración era semánticamente congruente ("Yo tomo café con crema y azúcar") o incongruente ("Yo tomo café con crema y perros") con su contexto. Las palabras semánticamente incongruentes provocaron el N400. Por otra parte, en oraciones completadas de manera congruente por palabras con distinta probabilidad "de cierre" ("cloze probability") presentaron una graduación de la amplitud de N400 en relación con la probabilidad de cierre: las palabras de menor probabilidad mostraron mayor amplitud de N400 y las de mayor probabilidad, una menor amplitud de este componente (Kutas y Hillyard, 1984).
El estudio del componente N400 de los PRE ha permitido el desarrollo de varias investigaciones en el campo de la psicolingüística (para una revisión, ver Kutas, Federmeier, Coulson, King y Münte, 2000; Kutas, Van Petten y Kluender, 2006; Osterhout y Holcomb, 1995). Dentro de éstas podemos mencionar las relacionadas con el reconocimiento de palabras, y los efectos del contexto sobre dicho reconocimiento, los efectos de la repetición, y sobre los mecanismos en varias patologías que afectan la comprensión del lenguaje (Kutas y Federmeier, 2011).
Finalmente, puede mencionarse la aplicación de los datos normativos de terminación en el estudio del procesamiento lingüístico en poblaciones con daño cerebral. A este respecto, se pueden mencionar las investigaciones de Berndt, Mitchum, Haen-diges y Sandson (1997) que mostraron un procesamiento diferencial de los verbos y los sustantivos usados como palabras finales en pacientes afásicos. Nebes y Brady (1991) encontraron variaciones importantes en el tiempo de juicio sobre si una palabra final completaría correctamente un contexto, dependiendo del grado de restricción contextual en pacientes con enfermedad de Alzheimer. También se han empleado en pacientes con esquizofrenia (Kircher et al., 2001), y trastorno por estrés postraumático (Kimble et al., 2002).
Resumiendo, los estudios de la comprensión del lenguaje tanto conductuales como electrofisiológicos se han beneficiado de la existencia de listas normalizadas de oraciones, que se han publicado para el inglés (Block y Baldwin, 2010; Bloom y Fischler, 1980), el francés (Robichon, Besson y Faïta, 1996) y el portugués europeo (Pinheiro et al., 2010) que utilizaron el método de cloze. El propósito de este trabajo es contar con una base de datos similar para la lengua española que pueda emplearse en niños. A pesar de que existe un estudio para el español en adultos (McDonald y Tamariz, 2002), este utilizó un método diferente al cloze, donde el sujeto responde a través de Internet (el software WebExp 2.1), el cual a pesar de tener indudables ventajas, limita la población de estudio y no permite un contacto directo sujeto-experimentador. Esto adquiere mayor importancia en el caso de la población de niños que son el objeto del presente estudio. En la literatura solo existen dos reportes en niños (para el portugués y el inglés) (Pinheiro et al., 2010; Towse, Hutton y Hitch, 1997). Es importante mencionar que el uso de normas ajustadas a la edad es crítico para el desarrollo de una investigación confiable en el campo de la psicolingüística y el desarrollo del lenguaje.
La obtención de listas normalizadas de oraciones permitirá la comparación de los resultados obtenidos por diversos investigadores bajo diferentes metodologías. Así, el objetivo del presente trabajo fue obtener, a través del método cloze, las normas de terminación de 285 contextos de oraciones en niños mexicanos de 9 a 12 años y del 4° al 6° grados de escuelas primarias públicas.
Método
Participantes
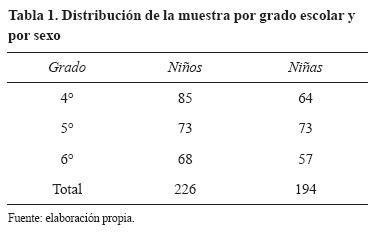
Participaron 420 estudiantes de sexo masculino y femenino (226 niños y 194 niñas), con rango de edad de 9 -12 años, todos hablaban español y cursaban del cuarto al sexto grados de primaria en dos diferentes escuelas primarias públicas del municipio de Tultitlán, Estado de México (zona conurbada a la Ciudad de México). Todos los niños procedían de un nivel socioeconómico medio bajo. De acuerdo con sus maestros, ningún niño presentaba discapacidad intelectual, ni retraso escolar. Su distribución se muestra en la tabla 1. Se informó a las autoridades escolares sobre los objetivos del proyecto, y éstas dieron su consentimiento informado para que los niños participaran.
Material
Se construyó un corpus de 285 oraciones con las siguientes características: a) Todas las oraciones se referían a situaciones concretas y fueron construidas correctamente tanto desde el punto de vista sintáctico como semántico; b) las oraciones tenían de 4 a 8 palabras de longitud, y presentaban diferentes estructuras gramaticales simples (sujeto-verbo-complemento, p. ej.: "La gallina pone un huevo"; sujeto-verbo-preposición-complemento, p. ej.: "Yo huelo con la nariz"; sujeto-pronombre reflexivo-verbo-preposición-complemento, p. ej.: "Los guantes se ponen en las manos"; sujeto-verbo-frase nominal-preposición-complemento, p. ej.: "Rompimos la piñata con un palo"); c) las palabras que terminaban cada oración fueron sustantivos que tenían una alta frecuencia de uso según los siguientes diccionarios: Del español usual en México (Lara, 2001), Diccionario del léxico infantil de México (Ávila, 1989) y Cómo usan los niños las palabras (Alva et al., 2001); d) las oraciones presentaban tres diferentes restricciones contextuales: fuerte (p. ej. que se completan con una única palabra como en "La semana tiene siete ____"), moderada (p. ej. que admite varias palabras restringidas a un campo semántico como en "Lupe se sentó en el ____") o débil (p. ej. que admite un número muy variado de palabras como en "Toño quiere un ____"). Había una mayor proporción de los dos primeros tipos en el corpus; e) se evitaron frases hechas y refranes; f) a cada contexto se le quitó la última palabra, con objeto de que los niños la completaran, dicho contexto podía hacerse aceptable tanto sintáctica como semánticamente, al agregar una sola palabra.
Procedimiento
El corpus original se dividió en dos cuadernillos, asignando las oraciones al azar, si bien en cada uno se presentaba un número semejante de los tres tipos diferentes de restricciones contextuales, de modo que el primer cuadernillo contenía 143 oraciones y el segundo 142. Las oraciones fueron impresas con letra Courier de 12 puntos, en mayúsculas; la línea para colocar la palabra faltante medía de 3 a 3.5 cm. Doscientos diez sujetos contestaron las oraciones del cuadernillo 1 y otros 210 niños contestaron las del cuadernillo 2.
El corpus se aplicó en el salón de clases a los grupos de niños de cada grado escolar. La distribución de los dos tipos de cuadernillos por grado escolar fue la siguiente: Cuadernillo 1: 4° grado: 75, 5° grado: 73, 6° grado: 62. Cuadernillo 2: 4° grado: 74, 5° grado: 73, 6° grado: 63. A cada niño se le repartió un cuadernillo que contenía las oraciones escritas y a todos se les indicó que llenaran sus datos generales (nombre completo, grado escolar y fecha de nacimiento). Las instrucciones dadas a los niños fueron: "En estas hojas tienen ustedes muchas oraciones a las que les falta la última palabra. Su tarea es leer las oraciones con cuidado y completarlas con la primera palabra que les venga a la mente. Trabajen lo más rápido que puedan, tomando en cuenta lo siguiente: solamente usen una palabra, eviten utilizar nombres propios o palabras compuestas, no utilicen palabras largas ni groserías, traten de no repetir palabras. Una vez completada la frase no regresen a las frases anteriores, continúen con las demás oraciones. No copien a sus compañeros". Las instrucciones, escritas en un cartel, fueron fijadas en el pizarrón del salón de clases para que estuvieran visibles durante la aplicación. Alguno de los investigadores permanecía en el salón de clases durante toda la aplicación, supervisando la ejecución de los niños.
Previo al cómputo de resultados, se regularizaron las faltas de ortografía, se analizaron las respuestas con dos palabras, reteniéndose solamente el sustantivo (p. ej. eliminando artículos y/o adjetivos), y se eliminaron las respuestas sintáctica o semánticamente incongruentes con el contexto de la oración.
Resultados
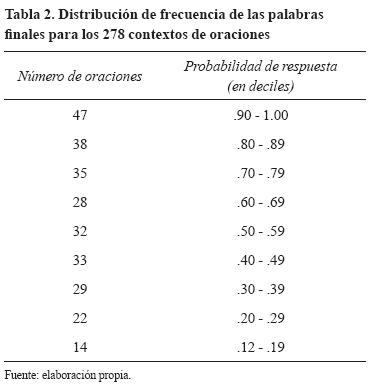
Se calculó la probabilidad de cada palabra respondida para cada uno de los contextos. En el Apéndice A aparecen los contextos listados en orden de probabilidad decreciente de la palabra final. Se incluyen las respuestas con una probabilidad mayor a .01 (que equivale a cinco sujetos). Se consideraron como "No respuestas" (NR) tanto la falta de respuesta para un contexto como las respuestas sintáctica o semánticamente incorrectas para dicho contexto (Robichon et al., 1996). Siete oraciones contenían una gran cantidad -mayor a 15%- de "No respuestas", por lo que se decidió eliminarlas del corpus, que quedó constituido así por 278 contextos (ver Apéndice A).
La tabla 2 muestra la frecuencia de distribución para la probabilidad de las palabras finales de todos los contextos. Esta distribución muestra cierta asimetría con una mayor proporción de repuestas muy probables, en los deciles de .90 a 1.00 y de .80 a .89 y un número menor de respuestas en el decil .12 a .19, sin respuestas con probabilidad por debajo de .12. Esto se debió, por una parte, a que el presente corpus contenía una mayor proporción de contextos con restricción fuerte y moderada respecto a la débil. Dado lo anterior, era de esperarse una distribución de este tipo. Sin embargo, no debe considerarse que la distribución del corpus está sesgada hacia la obtención de respuestas de alta probabilidad de cierre, como se hizo ex profeso en una parte del experimento de los contextos en inglés (ver la obtención del conjunto de contextos de baja incertidumbre en Bloom y Fishler, 1980) y en los contextos del grupo II y III del corpus en francés que contenían refranes y locuciones idiomáticas francesas (Robichon et al., 1996). En los estudios anteriores, los autores diseñaron el experimento con el fin de obtener una mayor proporción de respuestas de alta probabilidad, la cual fue más alta que la obtenida por nosotros.
En su mayor parte, las respuestas obtenidas evidenciaron una comprensión adecuada de los contextos oracionales y fueron congruentes con los significados de dichos contextos.
Discusión
Este trabajo logró el objetivo de obtener un corpus de oraciones en una población hispanohablante mexicana, que es representativa de niños de escuelas primarias públicas de una zona conurbada de la Ciudad de México. Asimismo, se presentan las normas de terminación de oraciones correspondientes a este tipo de población.
Es importante contar con un corpus de oraciones diseñado para niños, dado que no siempre pueden utilizarse los obtenidos para adultos (ver también Lahar et al., 2004). En el caso específico del idioma español, el corpus de McDonald y Tamariz (2002) obtenido en adultos, contiene estructuras sintácticas relativamente complejas, oraciones de dos o tres cláusulas y algunas expresiones idiomáticas usadas en España que podrían dificultar la comprensión de la oración para un niño, o para un hispanohablante no español (Arcuri, Rabe-Hesketh, Morris, y McGuire, 2001). En contraparte, nuestro corpus se compone de oraciones con estructuras gramaticales simples y expresiones idiomáticas que resultaron de fácil comprensión para la muestra utilizada. Por otra parte, el corpus presentado en este trabajo tiene la ventaja de haber sido producido por un gran número de sujetos, lo que avala su representatividad.
Aunque el corpus incluyó oraciones con diferentes restricciones contextuales de cierre, la respuesta de los sujetos mostró un mayor número de oraciones que correspondieron a las de alta probabilidad de cierre. Ello se debió, en parte, al diseño del corpus en el que incluimos más oraciones de este tipo, que son muy útiles como estímulos en los estudios electrofisiológicos del lenguaje y, por otra, quizá al léxico limitado de los niños muestreados.
Desde el punto de vista teórico, se comprobó que una característica distintiva de los estudios con contextos oracionales, comparados con los que utilizan pares de palabras asociadas, es que en los primeros se obtienen niveles muy altos de probabilidad de cierre (Bloom y Fishler, 1980).
Finalmente, el presente corpus de normas de terminación da una base de materiales estandarizados para la investigación del efecto de un contexto en el procesamiento de una palabra subsecuente en niños en edad escolar. Este material pudiera ser utilizado en el ámbito conductual de la psicolingüística de la lectura, y como se ha mencionado en la introducción, puede aplicarse también a la investigación de los procesos de reconocimiento de palabras, o la producción del lenguaje, así como a la caracterización de poblaciones especiales, particularmente los niños con trastornos del desarrollo, como pueden ser los que presentan trastornos de la lectura. También puede ser particularmente útil en estudios electrofisiológicos de la lectura o de la comprensión auditiva del lenguaje, en los que se pretenda obtener el componente N400 de los PRE.
Es importante señalar que las normas obtenidas en este estudio describen hallazgos sobre comprensión semántica de una población de niños de primarias públicas de 9 a 12 años. Por lo que sería probable que las normas para poblaciones de niños de otros estratos socioeconómicos, o de diferente edad, pudieran ser distintas de las presentes. Por lo anterior, la utilización de estas normas en una población diferente debe hacerse con reserva.
Referencias
Alva, C., Pérez, G., Monzón, P., Álvarez, M., Mejía, S., Hernández, P. y Carrión-Valderas, R. (2001). Cómo usan los niños las palabras. México: UNAM. [ Links ]
Arcuri, S., Rabe-Hesketh, S., Morris, R. & McGuire, P. (2001). Regional variation of cloze probabilities for sentence contexts. Behavior Research Methods, Instruments, and Computers, 33, 80-90. [ Links ]
Ávila, R. (1989). Diccionario del léxico infantil de México. Revista Científico Metodológica, 21. El Colegio de México. [ Links ]
Belinchón, M., Igoa, J. y Rivière, A. (1994). Reconocimiento y comprensión de palabras. En Psicología del Lenguaje: Investigación y Teoría. Madrid: Trotta. [ Links ]
Berndt, R., Mitchum, C., Haendiges, A. & Sandson, J. (1997). Verb retrieval in aphasia: Characterizing single word impairments. Brain and Language, 56, 68-106. [ Links ]
Block, C. & Baldwin, C. (2010). Cloze probability and completion norms for 498 sentences: Behavioral and neural validation using Event-related potentials. Behavior Research Methods, 42 (3), 665-670. [ Links ]
Bloom, P. & Fischler I. (1980). Completion norms for 329 sentence contexts. Memory and Cognition, 8, 631-642. [ Links ]
Brown, C., Hagoort, P. & Kutas, M. (2000). Poslexical Integration Processes in Language Comprehension. Evidence from Brain-imaging Research. En M. Gazzaniga (Ed.), The Cognitive Neurosciences. Cambdridge, MA: The MIT Press. [ Links ]
Condemarin, M. y Milicic, N. (1990). Test del Cloze. Madrid: Visor. [ Links ]
Connolly, J., Phillips, N. & Forbes, K. (1995). The effects of phonological and semantic features of sentence-ending words on visual event-related brain potentials. Electroencephalography & Clinical Neurophysiology, 94, 276-287. [ Links ]
DeLong, K., Urbach, T. & Kutas, M. (2005). Probabilistic word preactivation during language comprehension inferred from electrical brain activity. Nature Neuroscience, 8, 1117-1121. [ Links ]
Fayol, M. (2003). Procesamiento del Texto. En Haydé, O., Kayser, D., Koenig, O., Proust, J., Raiser, F. (Eds.). Diccionario de Ciencias Cognitivas. Buenos Aires: Amorrortu. [ Links ]
Federmeier, K., McLennan, D., de Ochoa, E. & Kutas, M. (2002). The impact of semantic memory organization and sentence context information on spoken language processing by younger and older adults: An ERP study. Psychophysiology, 39, 133-146. [ Links ]
Gathercole, S., Willis, C., Emslie, H. & Baddeley, A. (1992). Phonological memory and vocabulary development during the early school years: A longitudinal study. Developmental Psychology, 28, 887-898. [ Links ]
Griffin, Z. & Bock, K. (1998). Constraint, word frequency and the relationship between lexical processing levels in spoken word production. Journal of Memory and Language, 38, 313-338. [ Links ]
Kimble, M., Kaufman, M., Leonard, L., Nestor, P., Riggs, D., Kaloupek, D. & Bachrach, P. (2002). Sentence completion test in combat veterans with and without PTSD: Preliminary findings. Psychiatry Research, 113, 303-307. [ Links ]
Kircher, T., Bulimore, E., Brammer, M., Williams, S., Broome, M., Murray, R. & McGuire, P. (2001). Differential activation of temporal cortex during sentence completion in schizophrenic patients with and without formal thought disorder. Schizophrenia Research, 50, 27-40. [ Links ]
Kutas, M. & Hillyard, S. (1980). Reading senseless sentences: Brain potentials reflect semantic incongruity. Science, 207, 203-205. [ Links ]
Kutas, M. & Hillyard, S. (1984). Brain potentials during reading reflect word expectancy and semanticassociation. Nature, 307, 161-163. [ Links ]
Kutas, M. & Federmeier, K. (2011). Thirty years and counting: Finding meaning in the N400 component of the Event-related brain potential (ERP). Annual Review of Psychology, 62, 621-647. [ Links ]
Kutas, M., Federmeier, K., Coulson, S., King, J. & Munte, T. (2000). Language. En Cacioppo, J., Tassinary, L. & Berntson, G. (Eds.), Handbook of Psychophysiology. Cambridge, MA: Cambridge: University Press. [ Links ]
Kutas, M., Van Petten, C. & Kluender, R. (2006). Psycholinguistics electrified II: 1994-2005. En Traxler, M. & Gernsbacher, M. (Eds.), Handbook of psycholinguistics. New York: Elsevier. [ Links ]
Lahar, C., Tun, P. & Wingfield, A. (2004). Sentence-final word completion norms for young, middle-aged and older adults. Journal of Gerontology, 59B, P7-P10. [ Links ]
Lara, L. (2001). Diccionario del español usual en México. México: El Colegio de México. [ Links ]
McDonald, S. & Tamariz, M. (2002). Completion norms for 112 Spanish sentences. Behavior Research Methods: Instruments and Computers, 34(1), 128-137. [ Links ]
Munson, B., Swenson, C. & Manthei, S. (2005). Lexical and phonological organization in children: Evidence from repetition tasks. Journal of Speech, Language and Hearing Research, 48, 108-124. [ Links ]
Nebes, R. & Brady, C. (1991). The effect of contextual constraint on semantic judgments by Alzheimer patients. Cortex, 27, 237-246. [ Links ]
Osterhout, L. & Holcomb, P. (1995). Event-related potentials and language comprehension. En Rugg, M. & Coles, M. (Eds.), Electrophysiology of mind. Oxford: Oxford University Press. [ Links ]
Otten, M., Nieuwland, M. & Van Berkum, J. (2007). Great expectations: Specific lexical anticipation influences the processing of spoken language. BMC Neuroscience, 8, 89. [ Links ]
Otten, M. & Van Berkum, J. (2007). What makes a discourse constraining? A comparison between the effects of discourse message and priming on the N400. Brain Research, 1153, 166-177. [ Links ]
Pickering, M. & Garrod, S. (2007). Do people use language production to make predictions during comprehension? Trends in Cognitive Sciences, 11, 105-110. [ Links ]
Pinheiro, A., Soares, A., Comesaña, M., Niznikiewicz, M. y Gonçalves, Ó. (2010). Sentence-final word completion norms for European Portuguese children and adolescents. Behavior Research Methods, 42(4), 1022-1029. [ Links ]
Robichon, F., Besson, M. et Fãita, F. (1996). Normes du completion pour 744 contextes linguistiques Francais du differentes formats. Revue Canadienne du Psychologie Experimentale, 50(2), 225-233. [ Links ]
Schwanenflugel, P. & LaCount, K. (1988). Semantic relatedness and the scope of facilitation for upcoming words in sentences. Journal of Experimental Psychology: Learning, Memory and Cognition, 14, 344-354. [ Links ]
Schwantes, F. (1985). Expectancy, integration and interactional processes: Age differences in the nature of words affected by sentence context. Journal of Experimental Child Psychology, 39, 212-229. [ Links ]
Stanovich, K. & West, R. (1983). On priming by a sentence context. Journal of Experimental Psychology: General, 112, 1-36. [ Links ]
Storkel, H. (2002). Restructuring of similarity neighborhoods in the developing mental lexicon. Journal of Child Language, 29, 251-274. [ Links ]
Swingley, D. (2003). Phonetic detail in the developing lexicon. Language & Speech, 46, 265-294. [ Links ]
Taylor, W. (1953). "Cloze Procedure": A new tool for measuring readability. Journalism Quarterly, 30, 415-433. [ Links ]
Thomas, M. & Karmiloff-Smith, A. (2003). Connectionist models of development, developmental disorders and individual differences. En Sternberg, R., Lautrey, J. y Lubart, T. (Eds.), Models of intelligence: International perspectives. Washington, DC: American Psychological Association. [ Links ]
Towse, J., Hutton, U. & Hitch, G. (1997). Humpty Dumpty had a great...banana? Children's sentence completions in a working memory reading task (Tech. Rep. CDRG1). London: Royal Holloway, University of London. [ Links ]
West, R. & Stanovich, K. (1978). Automatic contextual facilitation in readers of three ages. Child Development, 49, 717-727. [ Links ]
West, R., Stanovich, K., Feeman, D. & Cunningham, A. (1983). The effect of sentence context on word recognition in second and sixth-grade children. Reading Research Quarterly, 19, 6-15. [ Links ]
Wicha, N., Bates, E., Moreno, E. & Kutas, M. (2003). Potato not Pope: Human brain potentials to gender expectation and agreement in Spanish spoken sentences. Neuroscience Letters, 346, 165-168. [ Links ]


