










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkIngeniería y Ciencia
Print version ISSN 1794-9165
ing.cienc. vol.9 no.18 Medellín July/Dec. 2013
ARTÍCULO ORIGINAL
Secante hiperbólica generalizada y un método de estimación de sus parámetros: máxima verosimilitud modificada
Generalized Secant Hyperbolic and a Method of Estimate of its Parameters: Maximum Likelihood Modified
Luis Alejandro Másmela Caita1 y Álvaro Alexander Burbano Moreno2
1 Magíster en estadística, lmasmela@udistrital.edu.co, Universidad Distrital Francisco José de Caldas, Bogotá, Colombia.
2 Estudiante de maestría en estadística, Universidad Nacional de Colombia, Bogotá, Colombia, aaburbanom@unal.edu.co, Universidad Distrital Francisco José de Caldas, Bogotá, Colombia.
Recepción: 03-05-2013, Aceptación: 19-07-2013 Disponible en línea: 05-11-2013
MSC: 60E05, 62E10
Resumen
Diversas distribuciones generalizadas se desarrollan en la literatura estadística, entre ellas se encuentra la distribución Secante Hiperbólica Generalizada (SHG). En este documento se presenta un método alternativo para la estimación de los parámetros poblacionales de la SHG, llamado Máxima Verosimilitud Modificada (MVM). Asumiendo algunas expresiones alternas que difieren con el trabajo de Vaughan en el 2002 y basándose en el mismo conjunto de datos de la fuente original. Se implementa computacionalmente el método transformado de MVM, permitiendo observar unas buenas aproximaciones de los valores de los parámetros de localización y escala, presentados por Vaughan en su artículo. Con esto se pretende que en la práctica se cuente con una metodología diferente para estimar.
Palabras clave: distribución secante hiperbólica generalizada; máxima verosimilitud modificada; estimación de parámetros.
Aspectos relevantes
• Se presenta el método de MVM, asumiendo algunas expresiones alternas que difieren con el trabajo de Vaughan en el 2002. • La implementación computacional del método de MVM, se realizó en dos problemas.
Abstract
Different generalized distributions are developed in the statistical literature, among them it is the generalized secant hyperbolic distribution (SHG). This paper presents an alternative method for estimation the population parameters of the SHG, called Modified Maximum Likelihood (MVM). Assuming some alternate expressions that are different from Vaughan´s work in 2002, and based on the same set of data from the original source. It is implemented, the transformed method MVM is implemented computationally, it allows us to observe good approximations of the exact values of the parameters of location and scale, presented by Vaughan in his article. The aim is that in the practice you can use a different methodology to estimate.
Key words: generalized secant hyperbolic distribution; modified maximum likelihood; estimation of parameters.
1 Introducción
La distribución secante hiperbólica (SH), fue estudiada primero por Baten [1] y por Talacko [2], su función de densidad de probabilidad con media cero y varianza uno, está dada por
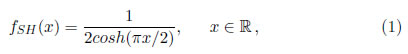
o, de manera equivalente, su función de distribución acumulada está dada por
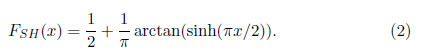
Esta distribución posee propiedades importantes. Tiene una leptocurtosis mayor que la normal y la logística, la función generadora de momentos existe. Desde 1956 se han propuesto dos generalizaciones. La primera, fue la distribución NEF-SHG, propuesta por Morris [3] en el contexto de las familias exponenciales naturales (NEF). La función de densidad de probabilidad de la distribución NEF-SHG está dada por
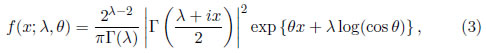
para λ > 0 y 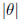 < π=2: Recientemente, Vaughan [4] propuso una familia de distribuciones simétricas, que llamó distribución SHG. Esta se compone de distribuciones con curtosis que van desde 1; 8 hasta el infinito e incluye la logística como un caso especial, la uniforme como un caso límite y se aproxima a las distribuciones normal y la t de Student con curtosis correspondientes. Por otra parte, el método utilizado generalmente para estimar los parámetros de localización y escala de la SHG (Máxima Verosimilitud (MV)), presenta algunas complicaciones que se mencionan en Vaughan [4]. Por consiguiente, se usarán las estimaciones de MVM en este trabajo.
< π=2: Recientemente, Vaughan [4] propuso una familia de distribuciones simétricas, que llamó distribución SHG. Esta se compone de distribuciones con curtosis que van desde 1; 8 hasta el infinito e incluye la logística como un caso especial, la uniforme como un caso límite y se aproxima a las distribuciones normal y la t de Student con curtosis correspondientes. Por otra parte, el método utilizado generalmente para estimar los parámetros de localización y escala de la SHG (Máxima Verosimilitud (MV)), presenta algunas complicaciones que se mencionan en Vaughan [4]. Por consiguiente, se usarán las estimaciones de MVM en este trabajo.
2 Metodología
En esta sección se detalla la metodología que se seguirá, en la cual se expone primero aspectos relacionados con la SHG. Luego, se utiliza el método de estimación de MVM, asumiendo algunas modificaciones efectuadas en las expresiones originales presentadas en el trabajo de Vaughan. Esto facilita la obtención de los valores de los parámetros de localización y escala mediante la programación del método en el software Matlab. Finalmente, se ilustra lo anteriormente mencionando utilizando dos conjuntos de datos, el primero sobre las diferencias de alturas de pares de plantas de maíz, cruzadas y autofertilizadas ([5, página 17],[4]), y el segundo, en un conjunto de datos simulados a partir de la SHG.
2.1 Formas funcionales
Se dice que una variable aleatoria X tiene distribución SHG con parámetro t, si su función de densidad está dada por:
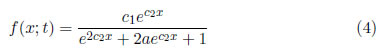
donde para − π < t < 0,
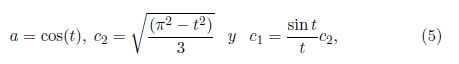
para t = 0
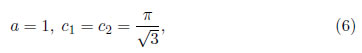
y para t > 0
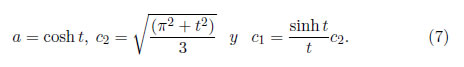
La densidad en (4) se escoge de manera que X ∼ SHG(0 ,1; t), es decir, con media cero y varianza uno. Nótese también que independientemente del valor de t, esta distribución es simétrica alrededor de cero. La función de distribución acumulada (fda)
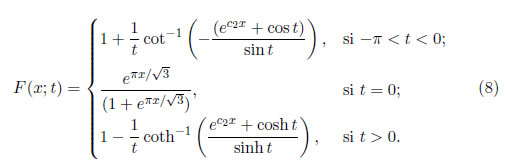
Sea 0 < u < 1 donde u = F(x). Entonces la inversa de fda o funcion de percentil (fp), se puede representar como
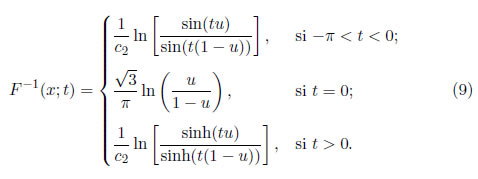
La función generadora de momentos también depende de t y está dada por
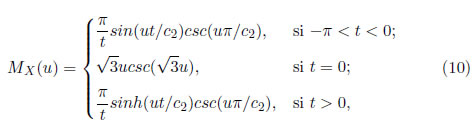
o puede ser escrita en términos de series de Taylor
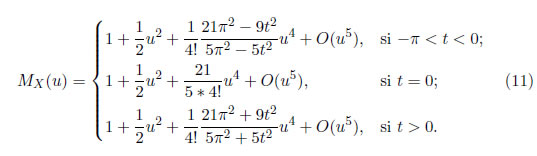
A pesar de sus buenas propiedades, la distribución SHG no ofrece ninguna posibilidad de incluir efectos de asimetría. Para ello, Fischer y Vaughan [6] introducen un parámetro de asimetría mediante dividir el parámetro de escala según Fernández, Osiewalski y Steel [7].
Cabe resaltar que la obtención de las formas funcionales anteriores, aparecen desarrolladas en Burbano [8].
2.2 Los estimadores de MVM
Suponiendo que es conocido el parámetro de forma t, en general, se dice que una variable aleatoria X se encuentra distribuida secante hiperbólica generalizada, denotado esto como X ∼ SHG(μ; σ; t), si su densidad está dada por:
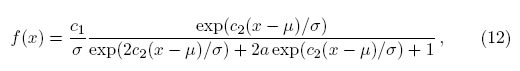
donde −∞ < x < ∞, μ ∈ R y σ > 0. Se define como de costumbre, la función de verosimilitud por L = 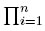 f(xi) y se establece la log-verosimilitudcomo ln L =
f(xi) y se establece la log-verosimilitudcomo ln L = 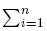 ln f(xi). Los estimadores de MV de μ y σ, son las soluciones de las ecuaciones
ln f(xi). Los estimadores de MV de μ y σ, son las soluciones de las ecuaciones
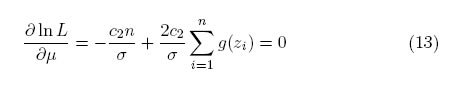
y
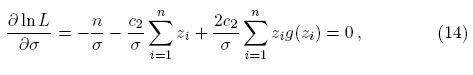
donde g(z) = (a exp(c2z) + exp(2c2z)=(exp(2c2z) + 2a exp(c2z) + 1) y z = (x − μ)/σ. Cabe hacer mención que la función referida anteriormente, es una nueva propuesta que se presenta en el documento y que resulta ser una expresión equivalente a la mostrada por Vaughan [4].
Las ecuaciones (13) y (14) no admiten soluciones explícitas debido a los términos relacionados con la función no lineal g(z), pero pueden ser resueltas por métodos iterativos. Esto puede ser problemático por razones de (i) las raíces múltiples, (ii) la falta de convergencia de las iteraciones (Barnett [9], Tiku y Suresh [10], Puthenpura y Sinha[11]). Lo que se necesita es un método de estimación que capture la belleza de la máxima verosimilitud, pero que alivie sus dificultades en el cálculo. Uno de los métodos y tal vez el más viable, es el método de estimación de máxima verosimilitud modificada que se originó con Tiku [12],[13]. Sea t(i) = E(z(i)) el valor esperado de la i-ésima variable estandarizada ordenada z(i), (1 ≤ i ≤ n). Es posible, encontrar una adecuada aproximación lineal para g(z(i)) a partir de la expansión en series de Taylor alrededor de t(i). De este modo, suponiendo que g(z) es casi lineal en un pequeño intervalo a < z < b (Tiku [12, 13]) y z(i) está situada en una vecindad de t(i) para un n grande, se obtiene una aproximación de los dos primeros términos de una serie de Taylor, es decir
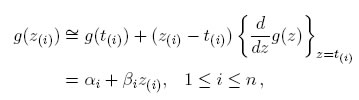
donde 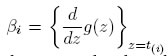 y αi = g(t(i)) − βit(i). Por lo tanto, las ecuaciones de verosimilitud modificada son:
y αi = g(t(i)) − βit(i). Por lo tanto, las ecuaciones de verosimilitud modificada son:
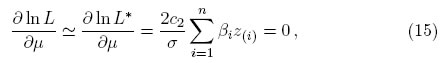
y
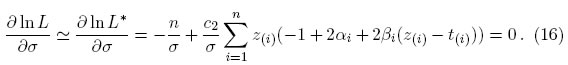
Si βi < 0, entonces se establece βi = 0 [4]. Cabe señalar que αi = n/2 y βit(i) = 0. Aunque la formulación para encontrar los valores exactos de las esperanzas t(i) están disponible en Vaughan [4], es difícil de implementar. Por consiguiente, se propone en este documento utilizar una forma alternativa, esta consiste en valores aproximados para los t(i) presentados en Tiku, Aysen y Akkaya [5] y que permiten minimizar las operaciones realizadas en la programación del método:
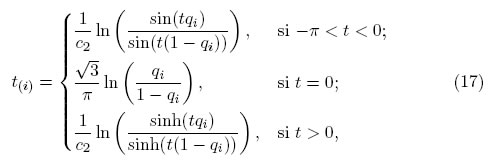
donde qi = i/(n + 1), que son las soluciones de
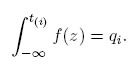
El uso de estos valores aproximados en lugar de los valores exactos no afecta la eficiencia de los estimadores de MVM de manera sustancial. Las soluciones simultáneas de 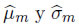 de las de las ecuaciones (15) y (16) son:
de las de las ecuaciones (15) y (16) son:
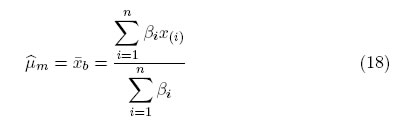
y
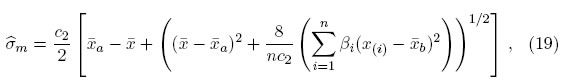
donde 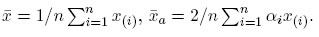
2.3 Determinación del Parámetro de Forma
En este documento, se aborda la distribución SHG con parámetros de localización, escala y forma, donde los dos primeros son obtenidos por el método de MVM, mientras que para el último parámetro, se pueden emplear gráficos Q-Q (cuantil-cuantil), pruebas de bondad de ajuste, o de la siguiente manera.
Se procede a calcular los valores de de las ecuaciones (18) y (19) para un t dado. Entonces, se obtienen los valores de (1/n) lnL utilizando alguna de las siguientes expresiones de acuerdo al t elegido, para −π < t < 0
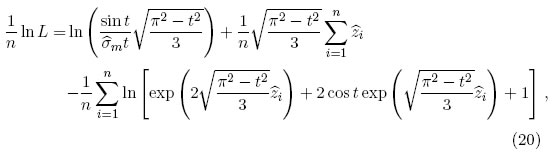
y t > 0
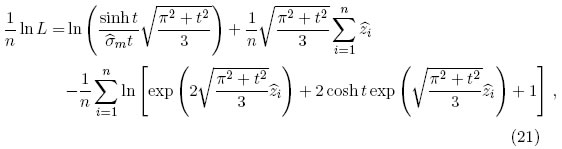
donde 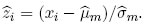 . Se realiza este procedimiento para una serie de valores de t. El valor de t que maximiza ln L es la estimación requerida (Tiku,Wong,Vaughan y Bian[14]).
. Se realiza este procedimiento para una serie de valores de t. El valor de t que maximiza ln L es la estimación requerida (Tiku,Wong,Vaughan y Bian[14]).
3 Resultados
A continuación se presentan los resultados obtenidos al aplicar la metodología en dos ejemplos, donde se incluyen algunos valores comparativos.
Ejemplo 3.1. Considere los siguientes datos obtenidos por Darwin [15], que representan las diferencias de alturas de pares de plantas de maíz, cruzadas y autofertilizadas sembradas en unas mismas macetas (Tabla 1).

Si se asume que las 15 observaciones son normales N(μ; σ2), entonces se obtienen los estimadores habituales de la media y varianza. Los valores son:

Recurriendo al gráfico de caja como se indica en la Figura 1, se observa que el conjunto de datos del ejemplo, presenta valores atípicos. Dado que la presencia de estos valores en los datos afecta a la media muestral como estimador de la media poblacional, Vaughan [4] sugiere de manera alternativa, la distribución SHG como un modelo que ofrece un buen ajuste a los datos.
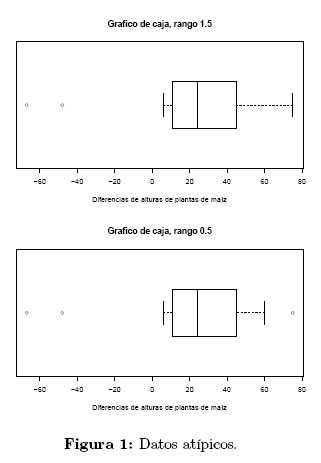
Para estimar los parámetros de localización y de escala mediante el método de MVM, se procede primero a calcular el parámetro de forma adecuado para el conjunto de datos. Mediante las ecuaciones (20) y (21), se tiene los siguientes valores de (1/n) ln L (Tabla 2).

Se elige t = −π/2, que es claramente un valor plausible del parámetro de forma. Cualquier valor de t cerca de t = −π/2 proporciona un modelo plausible, debido a la robustez intrínseca de las estimaciones de MVM, es decir, que esencialmente dan las mismas estimaciones y errores estándar. Con base en el modelo de la SHG y t = −π/2, las estimaciones de máxima verosimilitud modificada de μ y σ son:
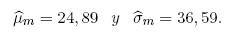
Cabe destacar que el parámetro de forma t y las estimaciones obtenidas por MVM, se calculan mediante la programación de códigos en Matlab 7.12.0 (R2011a). Además, estas estimaciones son aproximaciones de los valores exactos mostrados en Vaughan [4]
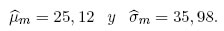
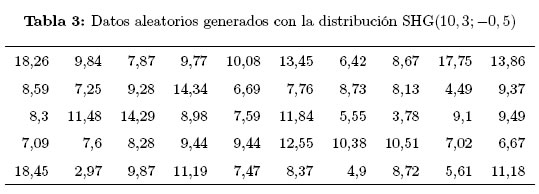
Ejemplo 3.2. Se generan 50 datos aleatorios procedentes de una distribución SHG con parámetros μ = 10, σ = 3 y t = −0; 5, cuyos valores son presentados en la Tabla 3:
Se escoge t = −0; 5, como un valor plausible del parámetro de forma. De hecho, se podría elegir t = −2; 5,/μ=2 o t = −μ/7, debido a las propiedades que poseen los estimadores de MVM. Por consiguiente, los valores de los parámetros de una SHG(μ, σ;−0; 5) son:
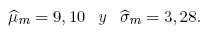
4 Conclusiones
En este trabajo se presentó la distribución SHG, como un modelo simétrico, cuyas propiedades la hacen una buena opción al momento de emplear conjuntos de datos que no se distribuyen normalmente. Sus formas funcionales dependen de los parámetros de localización, escala y de forma. Dentro de los varios métodos de estimación que existen para estimar los dos primeros parámetros de la SHG, se encuentran: Máxima Verosimilitud, los Mejores Estimadores Insesgados Lineales (BLUEs) y particularmente el método que se estudió y se presenta en este documento, denominado Máxima Verosimilitud Modificada.
En cuanto a las modificaciones que se hacen al planteamiento original hecho por Vaughan [4], se obtuvo una expresión equivalente para la función g(z) = (a exp(c2z) + exp(2c2z)/(exp(2c2z) + 2a exp(c2z) + 1).
Se emplearon unas expresiones alternas para t(i) ilustradas en Tiku [5, página 31-34], las cuales junto con la función equivalente g(z), es uno de los aportes principales de este trabajo.
Las variaciones realizadas a la fuente original, exhibieron un comportamiento similar en las estimaciones, pero permitieron una mayor facilidad en la programación del método en el software Matlab.
En un trabajo posterior se puede incluir el tema de la cópula, donde las marginales están distribuidas como una distribución SHG y junto con esto, emplear el método apropiado para estimar la distribución de vectores aleatorios mediante la estimación de las marginales.
5 Agradecimientos
Este trabajo se realizó en el marco del proyecto de investigación ''Un Estudio Sobre Dos Familias de Distribuciones de Probabilidad: Las Distribuciones Lambda Generalizada y Secante Hiperbólica Generalizada'', apoyado por el Centro de Investigaciones y Desarrollo Científico (CIDC) de la Universidad Distrital Francisco José de Caldas, desde el año 2011 al 2013.
Referencias
[1] W. D. Baten, ''Probability law for the sum of n independent variables, each subject to the law (1=2h)Sech(Πx=2h),'' Bulletin of the American Mathematical Society, vol. 40, no. 1, pp. 284-290, 1934. [ Links ] 94
[2] J. Talacko, ''Perks' Distributions and Their Role in the Theory of Wiener's Stochastic Variables,'' Trabajos de Estadística, vol. 7, pp. 159-174, 1956. [ Links ] 94
[3] C. N. Morris, ''Natural exponential families with quadratic variance functions,'' The Annals of Statistics, vol. 10, pp. 65-80, 1982. [ Links ] 95
[4] D. C. Vaughan, ''The Generalized Secant Hyperbolic Distribution And Its Properties,'' Communications in statistics, vol. 31, no. 2, pp. 219-238, 2002. [ Links ] 95, 98, 99, 101, 103, 104
[5] M. L. Tiku, D. Aysen, and Akkaya, Robust Estimation and Hypothesis Testing, 2nd ed. New York: New Age, 2004. [ Links ] 95, 99, 104
[6] M. Fischer and D. Vaughan, ''Classes of skewed generalized secant hyperbolic distributions,'' Universität Erlangen-Nürnberg: Lehrstuhl für Statistik und Ökonometrie, Tech. Rep, no. 45, [ Links ] 2002. 97
[7] C. Fernandez, J. Osiewalski, and M. F. J. Steel, ''Modelling and inference with v-spherical distributions,'' Journal of American Statistical Association, vol. 90, pp. 1331-1340, 1995. [ Links ] 97
[8] M. Burbano, Tesis de pregrado, Universidad Distrital Francisco Jose de Caldas, Facultad de Ciencias y Educación. Departamento de Matemáticas, Bogotá, Colombia, 2012. [ Links ] 97
[9] V. D. Barnett, ''Evaluation of the maximum likelihood estimator when the likelihood equation has multiple roots,'' Biometrika, vol. 53, pp. 151-165, 1996a. [ Links ] 98
[10] M. L. Tiku and R. P. Suresh, ''A new method of estimation for location and scale parameters,'' J. Stat. Plann, vol. 30, pp. 281-292, 1992. [ Links ] 98
[11] S. Puthenpura and N. K. Sinha, ''Modified maximum likelihood method for the robust estimation of system parametrs from very noisy data,'' Automatica, vol. 22, pp. 231-235, 1986. [ Links ] 98
[12] M. L. Tiku, ''Estimating the mean and Standard Deviation from a censored Normal Sample,'' Biometrika, vol. 54, no. 1, pp. 155-165, 1967a. [ Links ] 98
[13] M. Tiku, ''A note on estimating the location and scale parameters of the exponential distribution from a censored sample,'' Austral. J. Statist, vol. 9, no. 1, pp. 49-54, 1967b. [ Links ] 98
[14] M. L. Tiku, W. K. Wong, D. C. Vaughan, and G. Bian, ''Time series models in non-normal situations: symmetric innovations,'' J. Time Series Analysis, vol. 21, pp. 571-596, 2000. [ Links ] 100
[15] R. A. Fisher, The Design of Experimets, 9th ed. Hafner Publishing company, 1971. [ Links ] 101
