










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkIngeniería y Ciencia
Print version ISSN 1794-9165
ing.cienc. vol.11 no.21 Medellín Jan./June 2015
https://doi.org/10.17230/ingciencia.11.21.2
ARTÍCULO ORIGINAL
doi:10.17230/ingciencia.11.21.2
Regresión lineal con errores no normales: Secante Hiperbólica Generalizada
Linear Regression with Errors not Normal: Generalized Hyperbolic Secant
Álvaro Alexander Burbano Moreno1 y Oscar Orlando Melo Martínez2
1 Universidad Nacional de Colombia, Bogotá, Colombia, aaburbanom@unal.edu.co.
2 Universidad Nacional de Colombia, Bogotá, Colombia, oomelom@unal.edu.co.
Recepción: 09-06-2014 | Aceptación: 23-07-2014 | En línea: 30-01-2015
MSC: 60E05, 62E10
Resumen
En este trabajo se presenta un estudio del modelo de regresión lineal del tipo y=Θx+e, donde el error tiene distribución Secante Hiperbólica Generalizada (SHG). El método para estimar los parámetros se obtienen mediante una configuración de máxima verosimilitud expresando las ecuaciones no lineales en forma lineal (Verosimilitud Modificada). Los estimadores resultantes son expresiones analíticas en términos de valores de la muestra y, por lo tanto, son fácilmente calculables. Mediante la aplicación de varios tipos de datos, se muestra la metodología descripta anterior, y se obtienen modelos plausibles frente a las verdaderas distribuciones subyacentes de los datos.
Palabras clave: distribución secante hiperbólica generalizada; modelo lineal clásico; máxima verosimilitud modificada; mínimos cuadrados
Abstract
This paper presents a study of the model of linear regression of the type y=Θx+e, where the error has generalized hyperbolic secant distribution (GHS). The method to estimate the parameters are obtained by setting maximum likelihood expressing the non-linear equations in linear form (modified likelihood). The resulting estimators are analytical expressions in terms of values of the sample and, therefore, are easily calculables. Through the application of various types of data, the methodology described above is shown, and plausible models against the true underlying distributions of data are.
Key words: generalized secant hyperbolic distribution; classical linear model; modified maximum likelihood; least squares
1 Introducción
En un modelo de regresión lineal del tipo y=θx+e, a menudo se asume que los errores ei, 1 ≤ i ≤ n son idd (independientes e idénticamente distribuidos) con distribución normal N(0,σ2). Sin embargo, hay muchas situaciones de la vida real en las cuales es evidente que la respuesta no es normal. Por ejemplo, existen aplicaciones donde la respuesta es binaria (0 o 1) y, por ello, su naturaleza es de Bernoulli. Otras veces, cuando la respuesta mide los tiempos de vida o los tiempos de reacción, los errores normalmente tienen una distribución sesgada. Por lo tanto, en este trabajo se asume que los ei tienen una distribución Secante Hiperbólica Generalizada (SHG). Vaughan en el 2002 propuso esta familia de distribuciones [1]. Esta se compone de distribuciones simétricas tanto de cola corta y larga con curtosis que van desde 1.8 a 9 e incluye la logística como un caso particular, la uniforme como un caso límite y se aproxima estrechamente a las distribuciones normal y t de Student. Debido al amplio tipo de distribuciones que pueden ser consideradas, la SHG es utilizada eficazmente en la modelización de diferentes tipos de datos.Las ecuaciones de verosimilitud para la SHG son insolubles y resolverlas por iteración puede ser problemático [2],[3],[4]. Si los datos contienen valores atípicos, las iteraciones con las ecuaciones de verosimilitud son a menudo no convergentes [5]. Para mitigar estas dificultades, se puede utilizar el método de Máxima Verosimilitud Modificada (MVM) [6],[7], donde los estimadores obtenidos, tienen formas algebraicas explícitas y son, por lo tanto, fáciles para calcular y se sabe que tienen las siguientes propiedades bajo las condiciones de regularidad habituales para la existencia de los estimadores de Máxima Verosimilitud (MV):
En este sentido, este trabajo tiene como objetivo presentar un estudio del modelo lineal clásico con el supuesto de la distribución SHG de error, y emplear el método de estimación de MVM para diferentes tipos de datos.(a) asintóticamente, los estimadores de MVM son totalmente eficientes, es decir, son insesgados y sus varianzas son iguales [8],[9],[4] a los Límites de Varianza Mínima (LVM);
(b) para muestras pequeñas, los estimadores de MVM son casi totalmente eficientes en cuanto a los LVM [3];
(c) las estimaciones tienen poco o ningún sesgo.
2 Metodología
2.1 Distribución Secante Hiperbólica
Generalizada.
Sea un modelo de regresión lineal simpleyi=θ0+θ1xi+ei 1 ≤ i ≤ n.
Suponga que ei son idd, y tiene una distribución SHG(0,σ;t)
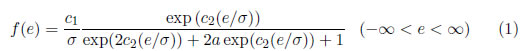
donde para −π < t < 0,
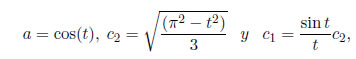
para t=0
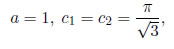
,y para t > 0
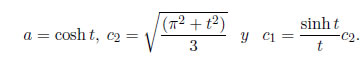
La media y varianza son:
E(e)=0, y Var(e)=1.Sea zi=ei/σ = (yi−θ0−θ1xi)/σ, 1 ≤ i ≤ n, las ecuaciones verosimilitud ∂lnL/∂θ0= 0, ∂lnL/∂θ1=0 y ∂lnL/∂σ = 0 son funciones no lineales. Para derivar las ecuaciones de verosimilitud modificada que tienen soluciones explícitas, y están en condiciones de regularidad asintóticamente equivalentes a las ecuaciones de verosimilitud (Smith [10]), primero se ordena wi=yi−θ1xi (para un determinado θ1)
w(1) ≤ w(2) ≤ … ≤ w(n); w(i)=y[i]−θ1x[i].
Definiendo las variables aleatorias ordenadas como z(i)=(w(i)−θ0)/σ, y denotando por (y[i],x[i]) la pareja ordenada que determina el valor de w(i); (y[i],x[i]) puede ser llamado el concomitante de z(i). El hecho de que las sumas completas son invariantes al orden, implica que las ecuaciones de verosimilitud se puede escribir en términos de z(i)
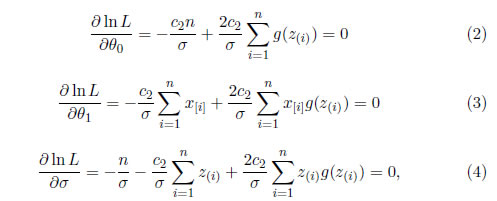
donde
g(z(i))=(exp(2c2z(i))+a exp(c2z(i)))/exp(2c2z(i))+2aexp(c2z(i))+1.
Las ecuaciones , y no admiten soluciones explícitas a causa de los términos relacionados con la función no lineal g(z(i)).
2.2 Verosimilitud Modificada
Sea t(i)=E(z(i)) el valor esperado de la i-ésima estadística de orden z(i), (1 ≤ i ≤ n). Note que las expresiones para encontrar los valores exactos de las esperanzas t(i) están disponible en Vaughan [1], pero son difíciles de implementar. Por lo tanto, se utiliza valores aproximados para los t(i) presentados en Tiku, Aysen y Akkaya [4] y que permiten minimizar las operaciones realizadas en la programación del método: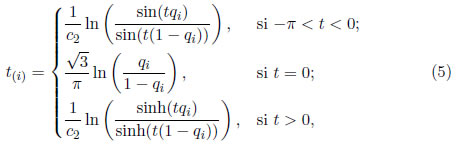
donde qi=i/(n+1), que son las soluciones de
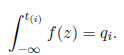
Para obtener las ecuaciones de verosimilitud modificada, se tiene que linealizar g(z(i)), mediante el uso de los dos primeros términos de una expansión de la serie de Taylor alrededor de t(i) (Tiku [7]; Tiku y Suresh [6]).
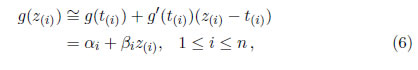
donde αi=g(t(i))−βit(i) y βi=g′(t(i)). Cuando βi < 0, se establece que βi=0 [1]. Por lo tanto, 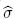 siempre es real y positiva. Además note que,
siempre es real y positiva. Además note que,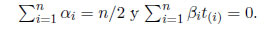 La incorporación de la expresión en -, se obtiene las ecuaciones de verosimilitud modificada ∂lnL*/∂θ0= 0, ∂lnL*/∂θ1=0 y ∂lnL*/∂σ = 0. las soluciones de estas ecuaciones son los estimadores deMVM:
La incorporación de la expresión en -, se obtiene las ecuaciones de verosimilitud modificada ∂lnL*/∂θ0= 0, ∂lnL*/∂θ1=0 y ∂lnL*/∂σ = 0. las soluciones de estas ecuaciones son los estimadores deMVM:

y
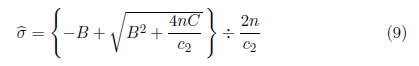
2.3 Determinación del parámetro de forma
Se procede a calcular los valores de 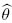 0, 1 y de las ecuaciones , y para un t dado. Ahora, se obtienen los valores de (1/n)ln L utilizando alguna de las siguientes expresiones de acuerdo al t elegido, para −π < t < 0
0, 1 y de las ecuaciones , y para un t dado. Ahora, se obtienen los valores de (1/n)ln L utilizando alguna de las siguientes expresiones de acuerdo al t elegido, para −π < t < 0
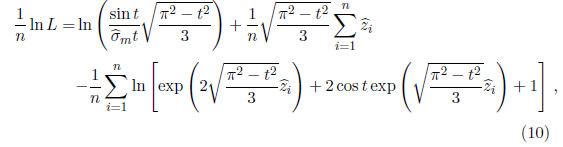
y, cuando t > 0
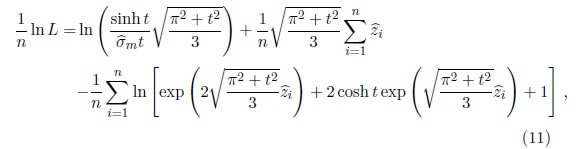
donde 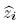 =(yi−01xi)/. Se realiza este procedimiento para una serie de valores de t. El valor de t que maximiza ln L es la estimación requerida [11],[12].
=(yi−01xi)/. Se realiza este procedimiento para una serie de valores de t. El valor de t que maximiza ln L es la estimación requerida [11],[12].
2.4 Mínimos Cuadrados
No hay supuestos de distribución como tal, en la aplicación de la metodología de Mínimos Cuadrados (MC). Bajo el supuesto de que ei (1 ≤ i ≤ n) son iid, los estimadores MC se obtienen mediante la minimización del error Suma de Cuadrados (SC)
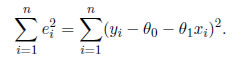
Los estimadores 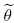 0 y 1 resultante, bajo el supuesto de normalidad N(0,σ2) son exactamente los mismos que los estimadores de MV. Los estimadores de MC de σ2 es definido como:
0 y 1 resultante, bajo el supuesto de normalidad N(0,σ2) son exactamente los mismos que los estimadores de MV. Los estimadores de MC de σ2 es definido como:
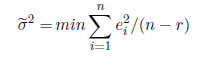
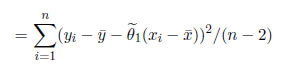
donde r es el número de parámetros estimados, además de σ.
Bajo el supuesto de normalidad, los estimadores de MC poseen todas las propiedades deseables. Sin embargo, tienen bajas eficiencias para distribuciones no normales.
2.5 Mínimos Cuadrados Ponderados.
Supongamos que los errores aleatorios ei (1 ≤ i ≤ n) en el modelo de regresión lineal simple, se distribuyen de forma independiente con una media común E(ei)=aσ y varianza Var(ei)=Viσ2. Sea wi=1/Vi (1 ≤ i ≤ n). Los estimadores de MC ponderados de θ0 y θ1 se obtienen mediante la minimización de
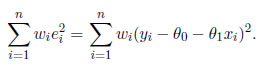
Esto da
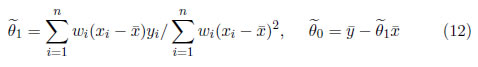
y
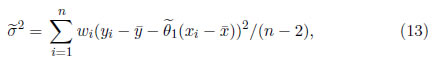
donde 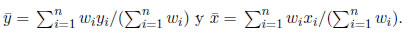
2.6 Mínimos Cuadrados para la Secante Hiperbólica Generalizada
Suponiendo la distribución SHG para los errores, los estimadores de MC son de (12)-(13)
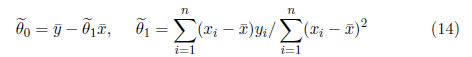
3 Aplicación
Se implementa computacionalmente el parámetro de forma y los estimadores obtenidos por MVM, mediante la programación de las expresiones en el software libre R.
Ejemplo 1 En Hamilton [13] se tiene un conjunto de datos interesantes sobre las magnitudes y los rendimientos de 19 pruebas de armas soviéticas; Y representa la magnitud estimada de los sismólogos y X el rendimiento reportado en kilotones (Tabla 1).
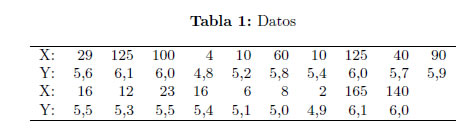
Se procede a calcular el parámetro de forma apropiado para el conjunto de datos, mediante las ecuaciones (10) y (11), se tiene los siguientes valores de (1/n)lnL (Tabla 2).

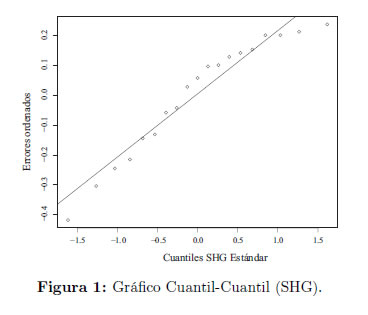
Un gráfico Cuantil-Cuantil de los residuos estimados Figura 1. Indican que una distribución de la familia (1) con t=2,7 puede proporcionar un modelo plausible.
Las estimaciones de MC son:
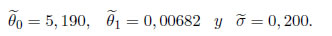
Las estimaciones de máxima verosimilitud modificada de θ0, θ1 y σ bajo la suposición del modelo de la SHG con el valor de t=2.7 son
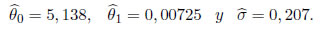
Ejemplo 2 En Hand [14] se muestra una serie de datos interesantes. Se tiene n = 30 observaciones sobre (X,Y): X indica la temperatura exterior media en grados Celsius e Y el consumo de gas (1000 pies cúbicos). Las observaciones fueron tomadas durante un período de 30 semanas después de la aislamiento de la cámara.
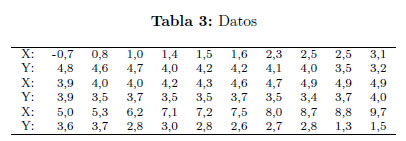
A continuación se presenta una serie de valores de (1/n)ln L para cada t dado.

Unos gráficos Cuantil - Cuantil de los residuos estimados para el modelo de regresión lineal simple presentados la Figura 2, indica que una distribución en la familia (1) con t=2,1 puede proporcionar un modelo plausible.
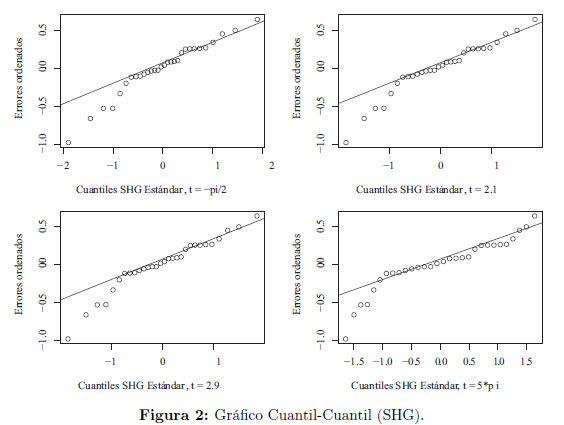
Los estimadores correspondientes MC y MVM
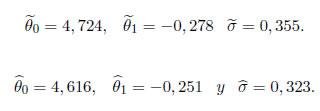
Ejemplo 3.3 Se midió la altura (cm) y peso (kg) de 30 niñas de once años de edad que asisten a la escuela secundaria de Heaton, Bradford [14,pag. 75].
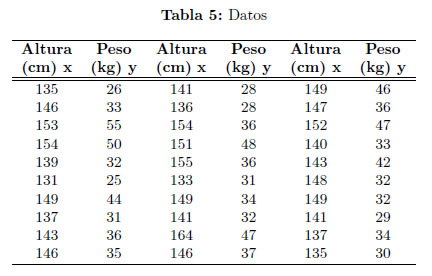
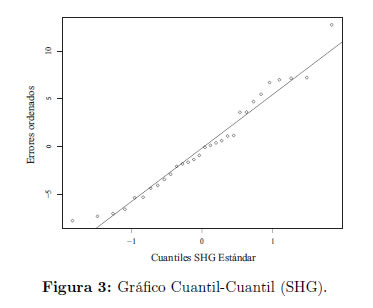
Una gráfica Cuantil - Cuantil de los residuos estimados para el modelo de regresión lineal dada la Figura 3, indica que una distribución de la familia (1) con t=2 puede proporcionar un modelo plausible. Los estimadores correspondientes de MVM y MC se indican a continuación:
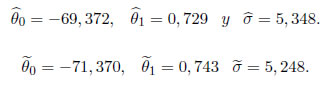
4 Conclusiones
Es ampliamente reconocido que las distribuciones no normales, ocurren con tanta frecuencia en la práctica e incluso que las muestras contienen a menudo valores atípicos. En tales situaciones, la estimación de máxima verosimilitud puede ser problemática [5]. En este trabajo, se ha utilizado el método de verosimilitud modificada para estimar los parámetros de un modelo de regresion lineal con el supuesto de la distribución SHG de error. Los estimadores resultantes, son funciones explícitas de observaciones de la muestra y, por tanto, fácil de calcular. Este enfoque fue implementado computacionalmente utilizando software simple y accesible como R.El análisis efectuado en los tres ejemplos, muestra que la SHG con t adecuado, proporciona un modelo plausible frente a las distribuciones subyacentes de los datos.
Agradecimientos
Los autores agradecen a los pares evaluadores y editores de la revista por sus valiosas contribuciones. Adicionalmente, a la Universidad Nacional de Colombia, sede Bogotá por su aporte significativo a este trabajo.
References [ Links ]
[2] V. D. Barnett, ''Evaluation of the maximum likelihood estimator when the likelihood equation has multiple roots,'' Biometrika, vol. 53, pp. 151-165, 1996a. [ Links ]
[3] D. C. Vaughan, ''On the Tiku-Suresh method of estimation,'' Communications in statistics, vol. 21, pp. 451-469, 1992. [ Links ]
[4] M. L. Tiku, D. Aysen, and Akkaya, Robust Estimation and Hypothesis Testing, 2nd ed. New York: New Age, 2004. [ Links ]
[5] S. Puthenpura and N. K. Sinha, ''Modified maximum likelihood method for the robust estimation of system parametrs from very noisy data,'' Automatica, vol. 22, pp. 231-235, 1986. [ Links ]
[6] M. L. Tiku and R. P. Suresh, ''A new method of estimation for location and scale parameters,'' J. Stat. Plann, vol. 30, pp. 281-292, 1992. [ Links ]
[7] M. L. Tiku, ''Estimating the mean and Standard Deviation from a censored Normal Sample,'' Biometrika, vol. 54, no. 1, pp. 155-165, 1967a. [ Links ]
[8] M. L. Tiku, ''Monte Carlo Study of Some Simple Estimators in Censored Normal Samples,'' Biometrika, vol. 57, pp. 207-211, 1970. [ Links ]
[9] G. K. Bhattacharyya, ''The Asymptotics of Maximum Likelihood and Related Estimators Based on Type II Censored data,'' Journal of the American Statistical Association,, vol. 80, no. 390, pp. 398-404, 1970. [ Links ]
[10] R. L. Smith, ''Maximum likelihood estimation in a class of nonregular cases,'' Biometrika, no. 72, pp. 67-90, 1985. [ Links ]
[11] M. L. Tiku, W. K. Wong, D. C. Vaughan, and G. Bian, ''Time series models in non-normal situations: symmetric innovations,'' J. Time Series Analysis, vol. 21, pp. 571-596, 2000. [ Links ]
[12] M. Alejandro and B. Alexander, ''Secante hiperbolica generalizada y un metodo de estimacion de sus parametros: maxima verosimilitud modificada,'' Ingenieria y Ciencia, vol. 9, no. 18, pp. 93-106, 2013. [ Links ]
[13] L. Hamilton, Regression With Graphics, 1st ed. Brooks/Cole Publishing Company, 1992. [ Links ]
[14] D. Hand, F. Daly, A. Lunn, K. McConway, and E. Ostrowski, Small Data Sets, 1st ed. Springer-Science Business, 1994.
