











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroducción
Conceptos psicométricos básicos
Se inicia el manuscrito con la definición de los conceptos de psicometría, instrumento de medida, medición y escala de medida para encuadrar los conceptos de confiabilidad y validez.
La psicometría es el campo de estudio concerniente a las teorías y técnicas de medición en psicología. En psicometría, el término de instrumento de medida hace referencia a un test o cuestionario formado por unas instrucciones verbales generales y unos ítems, reactivos o preguntas. Los ítems pueden ser verbales, lógicos, numéricos o materiales manipulables y requerir respuestas orales, escritas o ejecuciones de conductas observables (Kline, 2015). A su vez, el formato de respuesta en los ítems puede ser cerrado, y usualmente homogéneo, o puede ser abierto. En este último caso, habría una codificación establecida para categorizar las respuestas, como en las escalas de conducta y las pruebas proyectivas (Piotrowski, 2015). Unos instrumentos de medida requieren reportar conductas, ya sea públicamente observables o internas (sensaciones, deseos, motivos, emociones o pensamientos), las cuales son típicas o características de la persona; como es el caso de los test de personalidad, motivación, estado emocional o actitud. Otros instrumentos requieren resolver problemas, retener información, comprender información o mostrar conocimiento; como es el caso de los test de inteligencia, capacidad o funcionalidad (McClimans, Brown & Canoc, 2017).
Las opciones de respuesta de los ítems del test se transforman en números bajo una regla estipulada. A este proceso de asignar números a las respuestas de los participantes se le denomina medición (Loewenthal & Lewis, 2018).
La escala de medida de un ítem hace referencia a la correspondencia entre las propiedades empíricas de las distintas modalidades de respuesta y las propiedades algebraicas y operaciones aritméticas admisibles de los números asignados. Se distinguen cuatro tipos de escala de medida: nominal, ordinal, de intervalo o de razón (Wu & Leung, 2017).
La escala de medida nominal asigna símbolos numéricos a los distintos atributos o modalidades cualitativas de respuesta. Estos números permiten contar frecuencias y contingencias, pero no admiten operaciones aritméticas ni poseen propiedades algebraicas. Usualmente es de tipo dicotómico, como por ejemplo, 0 = “no” y 1 = “sí” ante la ejecución de una conducta. Otro ejemplo sería: 0 = “conducta impropia del rasgo medido” y 1 = “conducta propia del rasgo”.
Una escala ordinal asigna números ordinales a las distintas categorías ordenables de las modalidades de respuesta. Estos números poseen propiedades de ordenación y conteo, así como posibilidad de aritmética ordinal de suma, multiplicación y exponenciación. Es la más usada en escalas de actitud y emociones e inventarios de personalidad y motivaciones. Un ejemplo sería: 1 = “nunca”, 2 = “a veces”, 3 = “con frecuencia”, 4 = “con mucha frecuencia” y 5 = “siempre” ante la frecuencia de una conducta.
Las escalas de medida también pueden ser de intervalo (por ejemplo, distancia desde el origen de la línea hasta el punto marcado en un continuo que va a 0 “nada” a 10 “insoportable” al evaluar el malestar provocado por un síntoma) o de razón (por ejemplo “tiempo de respuesta medido en milisegundos” o “número de veces que se repite una conducta en un intervalo de tiempo”). Estas dos escalas asignan números naturales, enteros, racionales, irracionales o reales a las distintas cantidades o magnitudes en que se presenta la respuesta. Estos números admiten operaciones aritméticas y poseen propiedades algebraicas, poseyendo los números reales las propiedades y posibilidades aritméticas más amplias o inclusivas. En la escala de intervalo, no se puede fijar un cero absoluto (ausencia del rasgo) y la unidad de medida solo permite medir distancias relativas entre puntos (intervalos), y en la escala de razón, se puede fijar el cero absoluto y las mediciones son absolutas desde este punto de origen.
La puntuación en el test se obtiene por la suma simple o el promedio de las puntuaciones en los ítems (Kline, 2015; Streiner, Norman & Cairney, 2015). Las puntuaciones en el test pueden ser interpretadas en términos absolutos o relativos. En el primer caso, se usan el contenido de las categorías de respuesta. En el segundo caso, se usan como normas interpretativas las estimaciones de los parámetros de la distribución teórica a la que se aproximan las puntuaciones en una población, o se usan las estimaciones de los cuantiles poblacionales en caso de que la función de distribución empírica no siga ninguna función teórica reconocible (Loewenthal & Lewis, 2018). Usualmente, las puntuaciones en los test de actitud, emociones, motivaciones y personalidad están en una escala de medida de intervalo (Wu & Leung, 2017).
Confiabilidad y validez del instrumento de medida
Desde la teoría clásica de test, la confiabilidad de un instrumento de medida hace referencia a su capacidad de obtener mediciones con error mínimo (Jabrayilov, Emons & Sijtsma, 2016). Se puede establecer a través de tres estrategias: confiabilidad temporal o correlaciones al aplicar el mismo instrumento en dos o más momentos distintos; confiabilidad interjuez o correlaciones entre las mediciones obtenidas por distintos evaluadores al aplicar el instrumento a los mismos participantes, y confiabilidad por consistencia interna o correlación entre los distintos ítems o formas paralelas del test (Kline, 2015).
Desde la teoría clásica de test, la validez hace referencia a si un instrumento realmente mide lo que afirma evaluar (Moses, 2017). Tradicionalmente se distinguen tres tipos de validez: de contenido o en qué medida los ítems cubren el dominio de contenido del constructo; de criterio o correlación con otra medida confiable y válida que mide el mismo constructo u otro muy afín, y de constructo o grado en que se confirman las relaciones esperadas bajo la teoría y definiciones que sustentan al constructo. La validez de constructo incluye tanto el contraste del modelo estructural como la aportación acumulativa de evidencias de validez concurrentes, predictivas y retrodictivas (Furr, 2017).
Se considera que, una vez demostrada la validez de contenido, criterial y de constructo, queda establecida la validez de un instrumento de medida (Moses, 2017). Este enfoque tradicional de tres tipos de validez empezó a ser revisado en la década de 1970 (Furr, 2017). Por una parte, Cronbach (1971) enfatizó que las evidencias de validez ofrecen apoyo a las inferencias hechas con un instrumento en un contexto dado, con una muestra dada. Por otra parte, Messick (1975) concibió la validez como un conjunto de evidencias que ayudan a establecer la relación entre las puntuaciones en un instrumento y el constructo medido, esto es, el grado en que la evidencia y la teoría apoyan las interpretaciones de las puntuaciones en el test desde los usos propuestos para el mismo.
Ambos enfoques desplazaron la atención hacia la aplicación del instrumento en contextos concretos frente al planteamiento inicial más general o universalista, en el cual la confiabilidad y validez una vez probadas ya quedan establecidas. De este nuevo enfoque surge la necesidad de validar y baremar el instrumento de medida en los distintos contextos en que se aplica, como distintos contextos culturales (Loewenthal & Lewis, 2018).
Con el desarrollo del análisis factorial confirmatorio (Jöreskog, 1978; Jöreskog, Olsson, & Wallentin, 2016), no solo vino una nueva estrategia para aportar evidencias de validez de constructo (Bollen, 1989), sino también nuevas propuestas para el cálculo de la confiabilidad a través de la consistencia interna sin asumir que exista una covarianza homogénea entre las puntuaciones verdaderas y los errores de medida de los ítems (tau-equivalencia). Por ejemplo, se tienen las propuestas de Jöreskog (1971) y Werts, Rock, Linn y Jöreskog (1978) sobre el coeficiente de confiabilidad compuesta.
La validez convergente del factor
Al usarse análisis factorial confirmatorio cada factor posee unos indicadores, y se considera como requisito necesario demostrar que los indicadores propuestos miden dicho factor (Jöreskog, 1978). De aquí surge el concepto de la validez convergente de un modelo de medida, cuyo antecedente es la validez a través de matrices de correlación multirasgo-multimétodo introducida por Campbell y Fiske a finales de la década de 1950 (Jöreskog et al., 2016).
¿Qué es la validez convergente de un modelo de medida o factor? Dado un factor con n indicadores o ítems, este tipo de validez hace referencia al grado de certeza que se tiene en que los indicadores propuestos miden una misma variable latente o factor. Al preguntar si un modelo de medida posee validez convergente se pretende averiguar si el constructo es adecuadamente medido por los indicadores propuestos (Cheung & Wang, 2017).
Fornell y Larcker (1981) propusieron la VME calculada desde los pesos de medida estandarizados para evaluar la validez convergente del modelo de medida. Dado un factor o variable latente con k indicadores, la
Ecuación 1. Varianza Media Extraída
Fornell y Larcker (1981) fijaron el criterio de que un factor, con independencia de su número de indicadores, debe explicar más del 50 % de la varianza de los mismos para que se pueda considerar que posee validez convergente (nivel aceptable), e indicaron que, de preferencia, debería explicar más del 70 % (nivel bueno). El argumento es que la varianza atribuible al factor sea mayor que la no atribuible.
Hair, Black, Babin y Anderson (2010), al requisito de una VME mayor que .5, le añadieron pesos de medidas estandarizadas de al menos .5 en todos los indicadores y una confiabilidad compuesta de al menos .7. Tras un estudio de simulación, Cheung y Wang (2017) también recomendaron una VME no significativamente menor que .50 y unos pesos de medidas estandarizados no significativamente menores que .50 en todos los indicadores.
La confiabilidad compuesta o de constructo
Actualmente, como señalan Green y Yang (2015), se recomienda el uso del coeficiente de confiabilidad compuesta (
La varianza verdadera se estima a través del cuadrado de la suma de los pesos de medida estandarizados. Para obtener la varianza del test, a la varianza verdadera se le suma la varianza del error de medida. La varianza del error de medida se calcula por la suma de la varianza de los residuos o suma de cuadrados de los complementos de los pesos de medida estandarizados. El cociente entre la varianza verdadera y la varianza del test proporciona el coeficiente de confiabilidad (Green & Yang, 2015).
Ecuación 2. Confiabilidad compuesta, coeficiente rho o coeficiente omega
Se ha estipulado que valores entre .70 y .79 en el coeficiente omega reflejan niveles de confiabilidad por consistencia interna aceptables al indicar que al menos el 70 % de la varianza de las mediciones o puntuaciones empíricas en el test están sin error. A su vez, unos valores entre .80 y .89 se consideran buenos, y mayores o iguales que .90 se juzgan excelentes (Cho & Kim, 2015; Green & Yang, 2015; Viladrich, Angulo-Brunet & Doval, 2017). No obstante, se señala que valores mayores que .94 pueden indicar la presencia de ítems redundantes (Kline, 2015).
Una variante del coeficiente de confiabilidad compuesta es el coeficiente de confiabilidad congenérica (
Ecuación 3. Del coeficiente de confiabilidad congenérica
Al plantear que los ítems son esencialmente tau-equivalentes se parten de unos supuestos recogidos dentro de la teoría clásica de test o del error de medida (Pakzad & Alaeddini, 2017). Estos supuestos son: 1) la puntuación observada en un ítem es la suma de dos puntuaciones independientes, una puntuación verdadera y un error de medida; 2) la media de los errores de medida del ítem es cero; 3) los errores de medida de dos ítems de la escala son independientes, y 4) las puntuaciones verdaderas de un ítem y el error de medida del otro ítem también son independientes (Jabrayilov et al., 2016).
Bajo estos supuestos, se dice que tres o más ítems son paralelos si sus puntuaciones verdaderas y las varianzas de sus errores de medida son equivalentes; esto implica que las medias, varianzas, covarianzas y correlaciones de las puntuaciones observadas son estadísticamente homogéneas. Tres o más ítems son tau-equivalentes si sus puntuaciones verdaderas son equivalentes, aunque las varianzas de sus errores de medida no lo sean; esto implica que las medias y covarianzas de las puntuaciones observadas son estadísticamente equivalentes, pero las varianzas y correlaciones pueden ser heterogéneas. Tres o más ítems son esencialmente tau-equivalentes si sus puntuaciones verdaderas son combinación lineal unas de otras bajo operaciones de adición o sustracción, aunque las varianzas de sus errores sean heterogéneas; esto implica que las covarianzas entre las puntuaciones observadas son estadísticamente homogéneas, aunque las medias, varianzas y correlaciones de las puntuaciones observadas pueden ser heterogéneas (Jabrayilov et al., 2016; Pakzad & Alaeddini, 2017).
Entre las nuevas técnicas para evaluar la confiabilidad por consistencia interna, también se tiene el coeficiente H de Hancock y Müeller (2001) o confiabilidad de la combinación lineal óptima entre ítems (Ecuación 4). Este coeficiente se propone como una estimación del límite superior de la confiabilidad por consistencia interna de un test sin requerir el supuesto de tau-equivalencia (Domínguez-Lara, 2016), como el coeficiente ω que se basa en los pesos de medida estandarizados, además, no requiere que los ítems estén puntuados en el mismo sentido, como sí ocurre con el coeficiente α y el coeficiente ω al estar los pesos de medida elevados al cuadrado (McNeish, 2018). Se requiere un valor de al menos .70 para reflejar confiabilidad (Domínguez-Lara, 2016; Hancock & Müeller, 2001).
Ecuación 4. Coeficiente de confiabilidad H
Diferencia y semejanza entre validez convergente y confiabilidad de constructo
La diferencia entre ambos conceptos radica en que la validez convergente intenta estimar en qué proporción la varianza de los indicadores de un factor es explicada por una fuente atribuible (el factor) y no por fuentes no atribuibles (los errores). La confiabilidad compuesta o de constructo pretende separar la varianza del factor medida sin error (varianza verdadera) y con error (varianza del error de medida). La varianza del test es la suma de la varianza verdadera y la del error de medida. En un principio son dos conceptos próximos o afines, pero claramente distinguibles.
La semejanza fuerte aparece cuando las estimaciones se hacen desde los pesos de medidas estandarizados que el factor tiene sobre los ítems bajo el supuesto de que los errores de medidas son independientes (Figura 1). La varianza verdadera se obtiene al sumar los pesos de medida y elevar esta suma al cuadrado. La varianza del error de medida se obtiene al sumar los complementos de la varianza explicada por el factor en cada ítem. Esta varianza explicada es el peso de medida elevado al cuadrado. El promedio de estos pesos al cuadrado proporciona la varianza atribuible al factor y su complemento, la varianza no atribuible. En este punto, la semejanza los hace muy parecidos y complementarios, como ya lo reconocen investigadores como Green y Yang (2015), Hair et al. (2010) y Rodríguez, Reise y Haviland (2016).
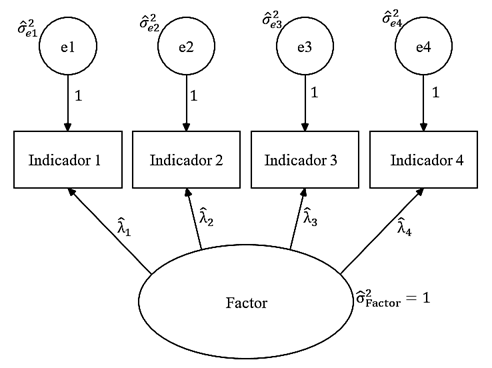
Figura 1 Modelo de un factor con dos grados de libertad o diferencia entre los 10 momentos muestrales (seis covarianzas y cuatro varianzas) y los ocho parámetros a estimar (las cuatro varianzas de residuos de medida y los cuatro pesos de medida tras fijar a un valor unitario la varianza del factor y los pesos de los residuos).
Se podría decir que ambos conceptos pretenden estimar una varianza atribuible a un modelo de medida especificado con k indicadores. Dicho en otras palabras, ambos conceptos plantean responder a la pregunta de si el modelo de medida de un constructo posee una variabilidad compartida o varianza verdadera (sin error) suficiente para ser una buena medición. Desde esta similitud se podría reconsiderar el valor crítico para la VME desde los valores críticos propuestos para el coeficiente de confiabilidad compuesta (coeficiente ω) y de constructo (coeficiente H).
A parir de lo previamente argumentado se plantea un estudio metodológico que tiene como objetivo revisar el punto de corte estipulado para la VME cuando se usa para establecer la validez convergente de un modelo de medida.
Método
En los análisis y demostraciones se consideró que todos los ítems presentan la misma correlación con el factor, es decir, sus pesos de medida estandarizados son equivalentes (Pakzad, & Alaeddini, 2017). Esta homogeneidad de pesos de medida (
Ecuación 5. Cálculo de Varianza Media Extraída con pesos de medida homogéneos
Se tomó como indicadores de confiabilidad por consistencia interna a los coeficientes ω (Ecuación 2) y H (Ecuación 4). Ambos coeficientes no son invariantes con respecto al número de indicadores (Abdelmoula, Chakroun & Fathi, 2015). Para comprobar este hecho se calculó la correlación entre el número de indicadores y el valor del coeficiente. Este cálculo se hizo a través del coeficiente de correlación producto-momento de Pearson (r). Se interpretó que un valor absoluto de │r│ < .10 muestra una fuerza de asociación trivial, entre .10 y .29 pequeña, entre .30 y .49 media, entre .50 y .69 grande, entre .70 y .89 muy grande y ≥ .90 perfecta o unitaria (Schober, Boer & Schwarte, 2018).
Para analizar la relación entre el número de indicadores, VME y coeficientes ω y H, se calculó qué valor debe tener el peso de medida estandarizado homogéneo en el factor (
Por otra parte, también variando el número de indicadores (k de 3 a 30), se calcularon los valores de los coeficientes ω y H que corresponden a un peso de medida estandarizado homogéneo alto (
Fornell y Larcker (1981), con independencia del número de indicadores y del valor del coeficiente de confiabilidad compuesta, estipularon como puntos de corte para establecer validez convergente
Resultados
Valores del peso de medida estandarizado homogéneo para alcanzar valores mínimos de confiabilidad aceptable, buena o excelente variando el número de indicadores del factor
¿Qué peso medida estandarizado se requeriría para alcanzar valores de .70, .80 y .90 en los coeficientes ω y H? Considerando la correlación entre el ítem y el factor o peso de medida estandarizado constante, se tendría para el coeficiente ω de McDonald (1999):
Ecuación 6. Peso de medida homogéneo ante un valor dado de confiabilidad compuesta
Por ejemplo, para tres indicadores, k = 3 (Tabla 1), aplicando las ecuaciones 6 y 5:
Por ejemplo, para cuatro indicadores, k = 4 (Tabla 1), aplicando las ecuaciones 6 y 5:
Por ejemplo, para cinco indicadores, k = 5 (Tabla 1), aplicando las ecuaciones 6 y 5:
Con el coeficiente H de Hancock y Müeller (2001) resultaría igual:
Ecuación 7. Peso de medida homogéneo ante un valor dado del coeficiente H
Tabla 1 Valores para los pesos de medidas estandarizados ( λ i ) y la varianza media extraída ( VME ), variando el número de indicadores del factor para obtener el valor mínimo de confiabilidad por consistencia interna, considera/do aceptable ( ω = H = .70), bueno ( ω = H = .80) y excelente ( ω = H = .90) ante una situación de pesos de medida estandarizados homogéneos.
| k |
|
|
|
|||
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
| 3 | .661 | .438 | .756 | .571 | .866 | .750 |
| 4 | .607 | .368 | .707 | .500 | .832 | .692 |
| 5 | .564 | .318 | .667 | .444 | .802 | .643 |
| 6 | .529 | .280 | .632 | .400 | .775 | .600 |
| 7 | .500 | .250 | .603 | .364 | .750 | .563 |
| 8 | .475 | .226 | .577 | .333 | .728 | .529 |
| 9 | .454 | .206 | .555 | .308 | .707 | .500 |
| 10 | .435 | .189 | .535 | .286 | .688 | .474 |
| 11 | .418 | .175 | .516 | .267 | .671 | .450 |
| 12 | .403 | .163 | .500 | .250 | .655 | .429 |
| 13 | .390 | .152 | .485 | .235 | .640 | .409 |
| 14 | .378 | .143 | .471 | .222 | .626 | .391 |
| 15 | .367 | .135 | .459 | .211 | .612 | .375 |
| 16 | .357 | .127 | .447 | .200 | .600 | .360 |
| 17 | .347 | .121 | .436 | .190 | .588 | .346 |
| 18 | .339 | .115 | .426 | .182 | .577 | .333 |
| 19 | .331 | .109 | .417 | .174 | .567 | .321 |
| 20 | .323 | .104 | .408 | .167 | .557 | .310 |
| 21 | .316 | .100 | .400 | .160 | .548 | .300 |
| 22 | .310 | .096 | .392 | .154 | .539 | .290 |
| 23 | .303 | .092 | .385 | .148 | .530 | .281 |
| 24 | .298 | .089 | .378 | .143 | .522 | .273 |
| 25 | .292 | .085 | .371 | .138 | .514 | .265 |
| 26 | .287 | .082 | .365 | .133 | .507 | .257 |
| 27 | .282 | .080 | .359 | .129 | .500 | .250 |
| 28 | .277 | .077 | .354 | .125 | .493 | .243 |
| 29 | .273 | .074 | .348 | .121 | .487 | .237 |
| 30 | .269 | .072 | .343 | .118 | .480 | .231 |
Nota. k = número de indicadores del factor. Estadísticos obtenidos en una muestra de n participantes:
Relación entre el número de indicadores del factor y la validez convergente
Desde los datos de la Tabla 1 se obtiene una correlación negativa entre el número de indicadores del factor (k) y el valor del indicador de validez convergente (
Valores del coeficiente ω y H ante pesos de medida estandarizados homogéneos de .50, .71 y .84 variando el número de indicadores del factor
Al mantener constantes las correlaciones homogéneas entre los ítems y el factor se puede observar que los coeficientes
El número mínimo de indicadores para un factor considerado como admisible es tres en el caso de un modelo de dos o más factores (Jöreskog et al., 2016). Ante un modelo de un factor se requieren cuatro indicadores para que el modelo esté sobreidentificado y permita no solo estimar los parámetros, sino también contrastar el ajuste a los datos (Figura 1). Con tres indicadores con pesos de medida de .66, se logra que los coeficientes
Entre cuatro y cinco se considera un número medio de indicadores y seis o más, alto (Perry, Nicholls, Clough & Crust, 2015). Con cuatro indicadores con pesos de medida de .61 se logra que los coeficientes ω y H tomen un valor de .70, lo que implica una
Más de 20 ítems se suelen considerar un número excesivo de indicadores para un factor (Van der Eijk & Rose, 2015). Con 21 indicadores o más con cargas menores que .60 y valores de
Tabla 2 Valores de los coeficientes omega y H variando el número de indicadores por factor ante la situación de pesos de medida estandarizados homogéneos.
| k | Valor de |
||
|---|---|---|---|
|
|
|
|
|
| 3 | .500 | .750 | .875 |
| 4 | .571 | .800 | .903 |
| 5 | .625 | .833 | .921 |
| 6 | .667 | .857 | .933 |
| 7 | .700 | .875 | .942 |
| 8 | .727 | .889 | .949 |
| 9 | .750 | .900 | .955 |
| 10 | .769 | .909 | .959 |
| 11 | .786 | .917 | .963 |
| 12 | .800 | .923 | .966 |
| 13 | .813 | .929 | .968 |
| 14 | .824 | .933 | .970 |
| 15 | .833 | .938 | .972 |
| 16 | .842 | .941 | .974 |
| 17 | .850 | .944 | .975 |
| 18 | .857 | .947 | .977 |
| 19 | .864 | .950 | .978 |
| 20 | .870 | .952 | .979 |
| 21 | .875 | .955 | .980 |
| 22 | .880 | .957 | .981 |
| 23 | .885 | .958 | .982 |
| 24 | .889 | .960 | .982 |
| 25 | .893 | .962 | .983 |
| 26 | .897 | .963 | .984 |
| 27 | .900 | .964 | .984 |
| 28 | .903 | .966 | .985 |
| 29 | .906 | .967 | .985 |
| 30 | .909 | .968 | .986 |
Nota. k = número de indicadores del factor. Estadísticos obtenidos en una muestra de n participantes:
Relación entre el número de indicadores del factor y la confiabilidad
Desde los datos de la Tabla 2 se obtiene una correlación positiva entre el número de indicadores y el valor del coeficiente de confiabilidad. La fuerza de asociación de estas correlaciones varía de muy grande a perfecta. Cuando
Discusión y conclusiones
El número de ítems del factor tiene un efecto muy fuerte sobre la
Al establecerse la validez convergente, el promedio de varianza que el factor comparte con los ítems es insuficiente porque no estima adecuadamente el error (Jöreskog, 1971). De ahí que es necesario incluir la división entre varianza verdadera y error de medida sin requerir que los ítems sean esencialmente tau-equivalentes o paralelos (Hair et al., 2010). Precisamente, esta separación es proporcionada de una forma más exacta por los coeficientes
Tomando como criterio que los pesos de medida sean mayores o iguales que .50, el coeficiente
La situación de ítems paralelos (correlaciones homogéneas entre los ítems) en el presente estudio se tomó a efectos de simplicidad demostrativa y de cálculo. Por tanto, los señalamientos hechos aplican perfectamente a la confiabilidad por consistencia interna calculada por el coeficiente alfa de Cronbach. No obstante, ni el coeficiente omega ni el coeficiente H requieren este supuesto. En consecuencia, se podría retomar como un peso de medida promedio.
Limitaciones
En el presente estudio no se manipuló el tamaño muestral. Se asumió un tamaño adecuado. ¿Cuál es un tamaño muestral adecuado? No existe una única regla sobre el tamaño muestral en análisis factorial confirmatorio, aunque hay autores, como Kline (2015) y Byrne (2016), que sugieren que sería entre 200 y 400 participantes.
Wolf, Harrington, Clark y Miller (2013) realizaron un estudio con una metodología de simulación. A través del procedimiento de Monte Carlo se generaron 10 000 simulaciones aleatorias de modelos factoriales con datos continuos normalmente distribuidos. En estos modelos se varió el tamaño muestral (n de 20 a 500 con incrementos de 10), la carga factorial homogénea entre los indicadores (
En el modelo de un factor, estos investigadores hallaron que con un tamaño muestral de 200 participantes con cuatro indicadores con pesos de .50 se alcanzaba una potencia ≥ .99, no existían problemas de convergencia o soluciones inadmisibles y los sesgos o diferencias entre el parámetro estimado y el valor muestral eran menores que .05 en todos los casos. Estas condiciones de potencia ≥ .99, soluciones convergentes y admisibles y sesgos < .05 se lograron con una muestra de 120 con seis indicadores y de 100 con ocho indicadores. Al ser
En un modelo de dos factores correlacionados con tres indicadores con cargas de .50 y correlación entre ambos factores de .30, se requiere una n = 400 para una potencia ≥ .85, soluciones convergentes y admisibles, así como estimaciones con un sesgo < .05 en las 10000 simulaciones aleatorias. El tamaño muestral bajaría a 200 con seis indicadores y 130 con ocho indicadores para lograr estos mismos resultados de potencia, convergencia/admisibilidad y sesgo.
Consecuentemente, cuanto menor es el número de factores, mayor el número de indicadores por factor, mayor el tamaño del efecto del factor sobre sus indicadores y mayor la correlación entre los factores, el tamaño de muestra requerido disminuye, pudiendo ser menor que 100 (Kyriazos, 2018). Se podría sugerir que con por lo menos seis indicadores con cargas de al menos .70, n ≥ 100; entre 3 y 5 indicadores con cargas de al menos .70, n ≥ 150. Con al menos seis indicadores con cargas entre .50 y 70 el tamaño muestral debería ser al menos de 200, y entre tres y cinco indicadores con cargas entre .50 y 70 debería ser al menos de 400 (Kyriazos, 2018; Wolf et al., 2013).
Sugerencias para futuras investigaciones
En futuros estudios basados en técnicas de simulación de datos se podría retomar la relación entre el número de ítems y la confiabilidad de constructo desde los promedios de pesos de medida heterogéneos. Cabe señalar que la mayoría de los estudios de simulación se han hecho con el método de máxima verosimilitud y variables continuas normalmente distribuidas, cuando esta no es una situación común en psicometría. En el caso de ítems tipo Likert (que tienen una escala de medida ordinal), la matriz de correlación más adecuada sería la de correlación policórica, y los métodos para optimizar la función de discrepancia serían mínimos cuadrados ponderados robustos, mínimos cuadrados diagonalmente ponderados, mínimos cuadrados no ponderados y mínimos cuadrados simples (Byrne, 2016; Jöreskog et al., 2016; Morata & Holgado, 2013). Un estudio de simulación con este tipo de datos y estos métodos sería más adecuado para la práctica psicométrica.
El requisito de un

