










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkEntramado
Print version ISSN 1900-3803
Entramado vol.9 no.1 Cali Jan./June 2013
Selección de índices financieros mediante técnicas estadísticas del análisis multivariante1
Selection of financial indicators using statistical multivariate analytical techniques
Seleção de índices financeiros usando técnicas de estatística multivariável
Samuel Leonidas Pérez Grau*
*Magíster en Administración Industrial, Universidad del Valle. Especialista en Gestión Tributaria, Aduanera y Cambiaria, Corporación Universitaria de la Costa - CUC. Contador Público, Corporación Universitaria de ka Costa - CUC. Ingeniero Químico, Universidad del Atlántico. Docente investigador Universidad Simón Bolívar, Barranquilla - Colombia.- Integrante del grupo Pensamiento Contable en el eje de Sistemas Contables y del tema Epistemología y Tecnología contables.
sammy975603@gmail.com.
- Clasificación JEL: C69
Fecha de recepción: 20 - 11 - 2012. Fecha de aceptación: 20 - 12 - 2012
Resumen
El objetivo de esta investigación es ofrecer a los Contadores Públicos una metodología de reducción del número de indicadores del estado de redituabilidad o de riesgo contable, con los cuales hacer el análisis de las revelaciones financieras de las empresas. Se trata de un estudio experimental exploratorio cuantitativo, para agrupar las contribuciones del conjunto original de p índices financieros de las empresas en otro conjunto de q variables incorrelacionadas, mediante la aplicación de la técnica estadística denominada Análisis de Componentes Principales. Los resultados obtenidos podrían utilizarlos los contadores para: simplificar los análisis posteriores contando para ello con un menor número de componentes, representar gráficamente los individuos en apenas 2 ó 3 dimensiones y, apreciar de modo más objetivo las relaciones entre las variables. Cada nueva matriz de mediciones, aun de las mismas variables sobre los mismos individuos, requiere un nuevo ACP, por lo tanto, nunca podríamos reproducir determinado estado de reditualidad o de riesgo contable, sino que sus variables deberán ser identificadas en cada ocasión.
Palabras clave: Índices financieros, análisis multivariante, análisis de componentes principales, matriz de correlaciones, matriz de covarianzas.
Abstract
The purpose of this research is to provide certified accountants with a methodology to reduce the number of indicators of the status of profitability or accounting risk in order to conduct an analysis of the financial disclosure of companies. This is an experimental, quantitative, and exploratory study that aims to incorporate the contributions of the original set of p financial indicators of companies into another set of q non-correlated variables by applying a statistical technique called Analysis of Principal Components (APC). The findings of this study could be used by accountants to: i) simplify further analyses using a lesser number of components; ii) graphically represent individuals on only two or three dimensions, and iii) observe inter-variable relations in a much more objective manner. Each new matrix of measurements, even of the same variables about the same individuals, requires a new APC, so a given status of profitability or accounting risk could not be reproduced, but instead its variables must be identified every time.
Keywords: Financial indicators, multivariate analysis, analysis of principal components, correlation matrix, covariance matrix.
Resumo
O objetivo dessa pesquisa é fornecer aos Contadores Públicos uma metodologia para a redução do número de indicadores do estado de rentabilidade ou de risco contábil, necessária para a realização da análise de divulgações financeiras das empresas. Esse é um estudo experimental exploratório quantitativo, para agrupar as contribuições do conjunto original de índices financeiros p das empresas em outro conjunto de variáveis q não correlacionadas, por meio da aplicação da técnica estatística denominada Análise de Componentes Principais. Os resultados obtidos poderiam ser usados pelos contadores para: simplificar as análises posteriores contando para isso com um número menor de componentes, representar graficamente os indivíduos em apenas 2 ou 3 dimensões e, apreciar de modo mais objetivo as relações entre as variáveis. Cada nova matriz de medições, até mesmo das mesmas variáveis sobre os mesmos indivíduos, exige um novo ACP, portanto, nunca poderíamos reproduzir determinado estado de rentabilidade ou de risco contábil, a não ser com suas variáveis sendo identificadas em cada ocasião.
Palavras-chave: Índices financeiros, análise multivariável, análise de componentes principais, matriz de correlações, matriz de covariâncias.
Introducción
Usualmente las estadísticas financieras que las entidades e instituciones comunican a sus usuarios contienen más de una decena de indicadores. En realidad no son todos ellos necesarios. Una selección apropiada de los índicadores financieros por empresas en redituabilidad o rendimiento, puede ayudar a identificar direccionadores posibles de la política a seguir, pero también tal selección puede ayudar a evidenciar parámetros útiles ante procesos concordatorios, para empresas bajo riesgo por no lograr los objetivos del ciclo contable.
Como antecedente de esta investigación puede decirse que desde finales del siglo anterior, se ha venido extendiendo la aplicación de la técnica estadística del ACP hacia casi todos los campos de la producción técnica (Barbosa, 2000); sin embargo, relacionado con el análisis financiero, tan solo ha sido conocido por el autor el intento realizado por los profesores Morozoni, Hein y Olinquevitch (2006) de la Universidad del Centro Oeste, sobre una lista de 99 empresas en procesos concordatorios en los juzgados de Curitiba (Paraná, Brasil), bajo la aplicación del software Mathlab.
Lo que se pretende establecer en este estudio es una respuesta al siguiente problema: ¿Cuáles son los indicadores financieros con mayor pertinencia para analizar de manera incorrelacionada su contribución al estado de redituabilidad o de riesgo contable de las empresas?. Ello con el objetivo de recomendar a los usuarios de la información financiera cuáles deberían ser los índices financieros seleccionables para explicar de modo necesario y suficiente el estado de redituabilidad de las empresas.
1. Desarrollo
Como es sabido, los analistas financieros diagnostican la situación de las empresas mediante la aplicación de unos indicadores (Rosillo, 2002), los cuales, por lo general, son los siguientes:
Indicadores de liquidez:
- Liquidez General (LG) = (Activo Corriente + Activo Realizable) / Pasivo Total
- Liquidez Corriente (LC) = Activo Corriente / Pasivo Corriente
- Liquidez Seca (LS) = (Activo Corriente - Mercancías) / Pasivo Corriente
Indicadores de riesgo:
- Capital de Trabajo a Patrimonio (CTP) = (Act. Cte. - Pas. Cte.) / Patrimonio Neto,
- Particip. Cap. de Terceros (PCT) = Pasivo Total / (Pasivo Total + Patrimonio Neto)
- Rotación del Activo Realizable (RAR) = Activo Realizable / Ventas Netas
Indicadores de apalancamiento:
- Grado de Endeudamiento (GDE) = Pasivo Total / Patrimonio Neto,
- Composición del Endeudamiento (CDE) = Pasivo Corriente / Patrimonio Neto,
- Grado de Inmovilidad del Patrimonio (GIP) = Activo Fijo / Patrimonio Neto
Indicadores de rentabilidad:
- Rentabilidad sobre Ventas (RSV) = Ganancia Neta / Ventas Netas,
- Rentabilidad sobre Activos (RSA) = Ganancia Neta / Activo Total,
- Rentabilidad sobre Patrimonio (RSP) = Ganancia Neta / Patrimonio Neto
1.1. Metodología
El ACP pertenece a un grupo de técnicas estadísticas multivariantes. Los métodos del análisis multivariante tienen una larga tradición en la elaboración de indicadores sintéticos en materia de predicción y de medición del desarrollo.
Tal como es utilizado en otras disciplinas diferentes de la contable, el objetivo más frecuente en la aplicación del ACP (Análisis de Componentes Principales) es el de reducir la dimensionalidad de la matriz de datos, con el fin de evitar redundancias y destacar relaciones entre variables, construir variables no observables (indicadores sintéticos) a partir de variables observables (Castro, 2002). Otros objetivos del ACP pueden ser, descubrir interrelaciones entre los datos, proponer la utilización de los componentes incorrelacionados hallados como datos de entrada para otros análisis estadísticos más apropiados.
Los tres métodos de análisis multivariante más convenientes para salvar la vaguedad de las estadísticas financieras, desde la eliminación de variables hasta la rotación o selección de factores, son el Análisis de Componentes (ACP), el Análisis de la Distancia (ADP2) y la Agregación de los Conjuntos Difusos (ACD).
El Análisis de Componentes Principales (ACP) consiste en encontrar transformaciones ortogonales de las variables originales (índices financieros) para conseguir un nuevo conjunto de variable incorreladas (componentes) (Villardón, 2002).
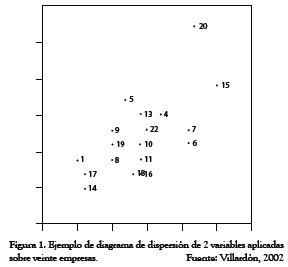
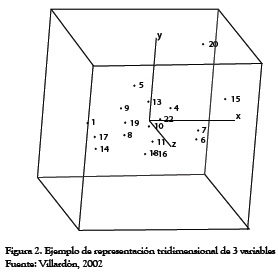
Mediante un programa de ordenador que permita el movimiento de la figura al tiempo que vemos las posiciones relativas de los puntos, observaremos cierta agrupación en la que la nube de puntos estará prácticamente sobre un plano en función de su relación entre sí.
Cuando encontremos este plano de referencia se definen dos vectores perpendiculares (ortogonales), uno de ellos (y) escogido en la dirección en que más varían los datos y el otro (x) recogiendo la mayor variabilidad posible. Sobre este plano ortogonal es factible interpretar las distancias entre los puntos en términos de similitud, buscar conjuntos de individuos similares, etc., con la garantía de que la pérdida de información es mínima y de que hemos recogido las fuentes de variabilidad más importantes en el conjunto de datos. La pérdida de información se entiende como la diferencia en las interdistancias calculadas entre los puntos del espacio original y las calculadas en la proyección sobre el plano de referencia, o sea, la variabilidad del conjunto de puntos.
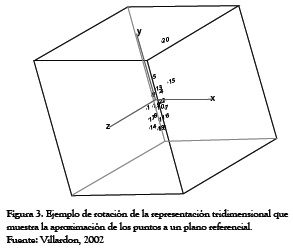
Obviamente, las variables en términos de vectores, quedan proyectadas sobre los ejes ortogonales del sistema de referencia como nuevas variables, cuya longitud o magnitud de valores alcanzados en su agrupamiento sobre los ejes, determinan un peso o carga de cada variable representativo del número mínimo de causas que condicionan un máximo de variabilidad existente. Si originalmente hemos considerado cada variable medida, correlacionada con otras, los nuevos datos ahora situados sobre un eje de variabilidad que también pasa por sus agrupamientos, seguirán describiendo la misma variabilidad total existente, con el mismo número de ejes originales pero ya no más correlacionados entre sí.
Sobre estos agrupamientos, pueden pasar ejes del sistema de referencia denominados factores cuyo valor de carga revela el factor de carga de la variable respecto de las otras. A aquel agrupamiento que tenga el máximo peso de carga encontrado corresponde su ubicación, paralelamente como eje principal del sistema de referencia. El segundo eje de maximización es colocado ortogonalmente y, así sucesivamente se van obteniendo los factores cuyas cargas vienen siendo combinaciones lineales de las variables originales.
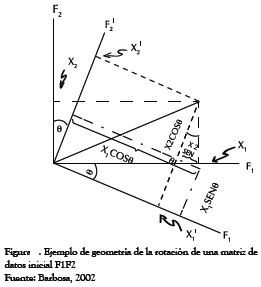
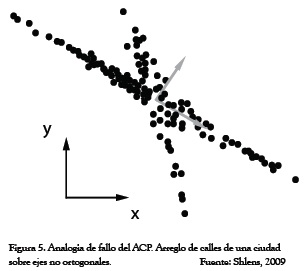
Una apreciación vagamente similar de abordar el procedimiento seguido por el ACP es la manera de explorar una ciudad: conducir por la carretera el trayecto más largo que la atraviesa. Cuando uno encuentre otra gran carretera, gire a la izquierda o la derecha y siga por ese camino, y así sucesivamente. En esta analogía, el ACP precisa que cada nueva carretera a ser explorada deba ser perpendicular a la anterior, pero claramente este requerimiento es demasiado riguroso y los datos, o la ciudad, puede disponerse a lo largo de ejes no ortogonales, como los de la Figura 5.
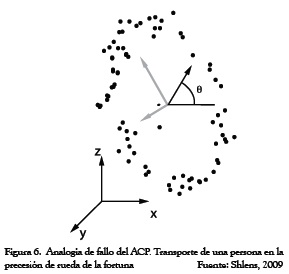
En otra situación que pareciera introducirnos al mismo problema, considere el seguimiento de una persona en una rueda de la fortuna, como se ve en la Figura 6. Los puntos de los datos podrían ser limpiamente descritos por una única variable, el ángulo de precesión de la rueda, sin embargo aquí tampoco el ACP podrá manejar esta variable. En estos dos ejemplos, vemos cómo a veces, el ACP es un método insatisfactorio.
Para dirimir esta paradoja, debemos definir lo que consideramos resultados óptimos. En el contexto de la reducción dimensional, una medida exitosa es el grado al cual una representación reducida puede predecir los datos originales. En términos estadísticos debemos definir una función de error común, en la que el error cuadrado medio, el ACP, provee la representación reducida óptima de los datos. Esto significa que con la selección de las direcciones ortogonales para los componentes principales obtenemos la mejor solución para predecir los datos originales.
En los ejemplos dados por las Figuras 5 y 6, nuestra intuición dirá que este resultado es engañoso. La solución a esta paradoja radica en el objetivo que tengamos en mente. El objetivo del ACP es descorrer los datos, es decir, quitar las dependencias de segundo orden que tengan los datos. Estadísticamente hablando, la rotación de los ejes lo que ha hecho es ubicar las proyecciones de cada variable, ya junto al extremo, otra junto al origen, en los nuevos ejes factoriales ortogonales y maximizar con ello la varianza de las cargas.
En las analogías citadas tenemos que existen dependencias de mayor orden entre los datos, por lo tanto la remoción de las dependencias de segundo orden es insuficiente para revelar toda la estructura de relaciones entre los datos. (Shlens, 2009).
1.2. Interludio matemático
La esencia matemática del ACP es el cálculo de los autovalores y los correspondientes autovectores de las matrices cuadradas pxp denominadas de correlaciones o de covarianzas de la matriz original. Las matrices de covarianza se utilizan mayormente cuando los datos son dimensionalmente homogéneos. La aplicación de las matrices de correlaciones se recomienda cuando las variables muestran grandes diferencias de valores medios, o expresan muy diferentes unidades de medida.
Cuando las escalas de las variables no permiten una comparación directa de las mediciones involucradas, se hace necesaria la estandarización preliminar de los datos de modo que las variables así transformadas tienen un valor medio de cero y la unidad como varianza. En tal caso las matrices de covarianzas y de correlaciones se hacen idénticas (Bronson, 1994).
Siguiendo con la etapa matemática del ACP, se extraen los autovalores y los autovectores de una matriz A de varianzas y covarianzas con términos aij, siendo I la matriz identidad, Vi su iésimo vector de términos vij y λi el iésimo vector, por lo que podemos escribir:
( A - λi I) Vi = 0 (1)
Alternativamente, se pueden escribir las siguientes ecuaciones simultáneas (Barbosa, 2000) formadas por la matriz de coeficientes aij multiplicadas por un vector de términos vij desconocidos, que son iguales al vector Vi multiplicado por una constante λ:
AVi = Vi λi = [A][V] = [V] [Î] (2)
Siendo [V] una matriz pxp de todos los autovectores y, [Λ] una matriz pxp con los autovalores λi en la diagonal principal.
Multiplicando ambos términos de la ecuación por la transpuesta de V, tendremos:
[A] = [V][Î][V]t (3)
En una matriz de varianza-covarianza, las varianzas individuales constituyen los elementos de la diagonal principal, por lo tanto, basta sumarlos para hallar el arreglo punteado de la matriz para obtener la variabilidad total e inmediatamente la contribución de cada variable.
Σ λi = Σ aij (4)
siendo por definición: λ1 ≥ λ2 ...≥ λp
Lo cual, en palabras, se dice: "En una matriz de varianzacovarianza, la suma de autovalores es igual al arreglo punteado de la matriz y representa la variabilidad total de la misma y también determina la contribución de cada autovalor en términos de variabilidad". El primero de los autovalores corresponde a la mayor variabilidad posible existente, el segundo a la mayor variabilidad posible restante y, así sucesivamente.
"Ahora, recíprocamente, en términos geométricos, se dice que el primer autovalor representa al eje principal de mayor longitud, el segundo valor a la segunda longitud situada en posición ortogonal respecto del primero, y así sucesivamente" (Barbosa, 2000).
De este modo, al multiplicar la matriz de los datos originales por la matriz de autovectores, se obtiene una matriz de datos transformados que representan la proyección de los puntos, en un espacio multidimensional, sobre las diversas componentes principales.
1.3. Justificación
También en la contabilidad financiera, cabe la utilización de modelos capaces de determinar el comportamiento colectivo de un conjunto de variables interrelacionadas, a través de la determinación de estructuras latentes de forma que sus efectos no pueden interpretarse únicamente por separado. Inicialmente, estas variables son los índices financieros, del más puro saber contable (Warren, Reeve y Duchac, 2011).
Sería deseable, para el análisis financiero, poder trabajar con agrupaciones adecuadas de los índices financieros para representar en ellos todas las propiedades relacionadas con la medición buscada, para lograr que estas nuevas variables agrupadas puedan medir adecuadamente los estados fenomenológicos en el momento del tiempo a que se refiere y que la medición obtenida sea objetiva, no necesitándose más indicadores de percepción experta para el conocimiento del problema (Pérez, 2010).
1.4. Procedimiento
En este trabajo se busca reducir la cantidad de datos de 63 empresas colombianas, emisoras de valores en buenas condiciones de redituabilidad (con índices de rendimiento sobre ventas, activos totales y/o patrimonio neto, positivos) y de otras 43 empresas en riesgo contable (con índices de rendimiento contable negativos o nulos y por ello en riesgo de no lograr los objetivos del ciclo contable), mediante igual procedimiento de la técnica estadística del ACP.
Estos datos son de publicación anual obligatoria por el Sistema de Información del Mercado de Valores SIMEV de la Superintendencia Financiera; sin embargo, en este estudio no interesa resaltar el desempeño de período alguno, ni mucho menos reivindicar alguna empresa, por lo que se ha preferido omitir en qué año se cumplieron los datos y a cuáles empresas estuvieron referidos.
Se parte, entonces, de las Tablas de Índices Financieros (Rosillo, 2002) sacados de las revelaciones contables de las empresas colombianas, publicadas por el SIMEV, para someterlas al tratamiento estadístico del ACP utilizando para ello el software Minitab, una marca registrada de IBM.
Para introducir los datos en el software MINITAB se siguen las siguientes instrucciones:
- (Estadística>Regresión>Regresión: se introducen los datos),
- (Gráficas>Residuos para gráficas>estandarizado),
- (Gráficas de residuos>Gráficas individuales> Histograma de residuos>gráfica normal de residuos>Residuos versus ajustes>
Si se parte de variables con las mismas unidades de medida, se puede realizar el análisis con base en la matriz de covarianzas, pero las variables con varianzas muy elevadas introducirán un sesgo que domina los componentes iniciales, por ello se hace preferible extraer los componentes de la matriz de correlaciones muestrales R (de los Coeficiente de Correlación), lo que equivale a hacerlo a partir de la matriz inicial con los valores estandarizados, concediendo a todas las variables la misma importancia (Castro, 2002).
En la Tabla 2 se muestran los valores y vectores propios de la matriz de covarianza de los componentes principales en condiciones de redituabilidad que arroja la máquina:
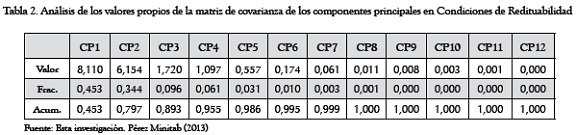
Obsérvese cómo en la Tabla 2 (Condiciones de Redituabilidad), basta acumular solamente hasta el CP8 para explicar la variación total contenida en los componentes, hasta llegar al nivel máximo del 100%.
Se procede de igual manera para el grupo de datos de la Tabla 3.
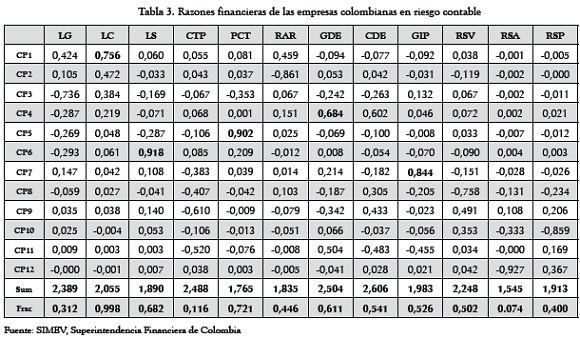
En la Tabla 4 se muestran los valores y vectores propios de la matriz de covarianza de los componentes principales, en condiciones de Riesgo Contable.
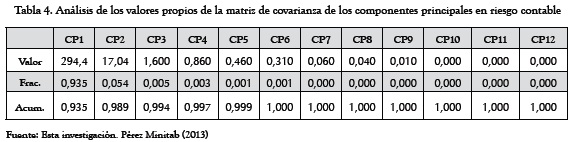
Obsérvese cómo en la la Tabla 4 (Riesgo Contable) se requiere acumular hasta el CP6 para explicar la variación total. En las Tablas 2 y 3 puede verse cómo los componentes obtenidos están jerarquizados con base en la información que incorporan, la cual ha sido medida según el porcentaje de varianza total explicada sobre la matriz de los datos originales. La fila "Acumulada", en la que se registra la integración de los componentes es la que conducirá a la reducción de la dimensión de los datos originales.
2. Resultados
2.1. Método de la covarianza
Pasamos ahora al análisis en el espacio de las variables. La Tabla 5 señala los resultados obtenidos sobre la muestra de empresas en redituabilidad, siguiendo el método de la covarianza.
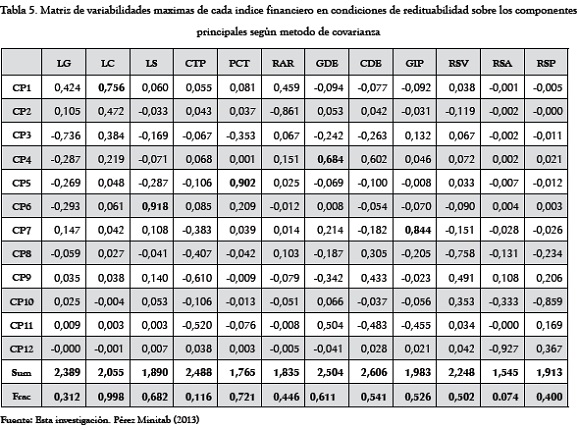
En el espacio de las variables, el análisis tiene sentido si existen variabilidades positivas de las variables, ya que esto es indicativo de su mayor incidencia sobre la variabilidad absoluta total, y por tanto los demás factores tendrán poca incidencia (Villarroel, Álvarez y Maldonado, 2003).
El primer paso del análisis consiste en calcular la suma de los valores absolutos de las correlaciones de cada vector de variables, o sea la variabilidad de las combinaciones lineales de las variables originales. También, se calcula el cociente entre la suma de las variabilidades positivas y su variabilidad total correspondiente, o sea la proporción de variabilidad absorbida por cada variable.
Aquellas variables incorrelacionadas que muestran una variabilidad nula o negativa son candidatas a ser eliminadas del análisis (Morozini, Olinquevitch y Hein, 2006), mientras que aquellas otras que mantienen una correlación positiva propician grados de interpretación por separado, es decir, sin asociación a indicadores sintéticos (Castro, 2002).
De la Tabla 5 resulta que las mayores correlaciones positivas las presentan las parejas:
LC-CP1, PCT-CP5, LS-CP6, GDE-CP4 y GIP-CP7.
La Tabla 6 presenta como sus mayores correlaciones positivas, las parejas:
LC-CP4, GIP-CP6, LS-CP3, GDE-CP5 y RSV-CP1
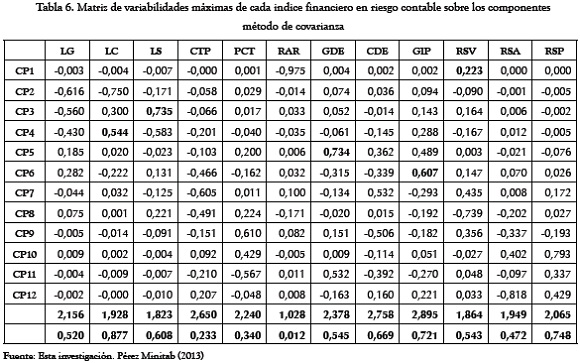
El análisis multivariante clásico se centra en la evaluación de la interdependencia entre pares de variables, pero además de haber tenido en cuenta su magnitud (relación entre variables) y el signo (tipo de relación), nos encontramos que se requiere de experiencia para lograr las selecciones más apropiadas de las variables mejores, representativas de la variabilidad de los datos, que sean capaces de separar variables que sugieren los mismos aspectos de los indicadores sintéticos, aunque en diferente forma y por ello, también pudieran ser utilizables como datos de entrada para otros análisis (Shlens, 2009).
Como en el caso que nos ocupa no se hacen referencias a condicionamientos especiales, el investigador ha quedado en libertad para interpretar su propio querer. El criterio aquí aplicado, tanto para la selección de las variables mejor proporcionadas como para asumir una representación explicativa de la variabilidad de los datos, son aquellos índices comunes a las tablas de las empresas en redituabilidad y en riesgo contable; estos son: LC, GIP y GDE.
A veces, los investigadores disponen de información adicional que amplía la matriz de datos originales con otros atributos de los individuos, o también nuevos individuos para los que se conozcan las variables analizadas (Villardon, 2003). A estos datos adicionales se les llama suplementarios o ilustrativos porque no forman parte de los componentes extraídos por las técnicas estadísticas pero sus relaciones con ellos permiten interpretar más ajustadamente un modelo de la realidad.
También, si la muestra es suficientemente grande, resulta posible dividirla en varias submuestras para analizar la robustez de los resultados obtenidos y otras veces se puede integrar con otras muestras para explicar o discriminar los casos que, a priori, se puedan discriminar. No obstante, en todos los casos, el paso final consiste en la validación de la bondad de los resultados.
2.2. Método de la correlación
La Tabla 7 (Condiciones de Redituabilidad) señala los resultados obtenidos sobre la muestra de empresas en redituabilidad, siguiendo el método de correlación. En esta Tabla se observa que se requiere acumular hasta el CP11 para explicar la variación total contenida en los componentes.
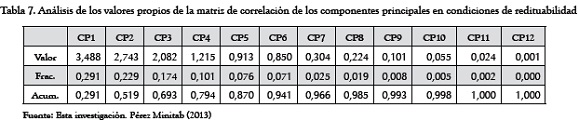
También se observa cómo en la Tabla 8 (Riesgo Contable), basta acumular solamente hasta el CP10 para explicar la variación total contenida en los componentes, hasta llegar al nivel máximo del 100%.
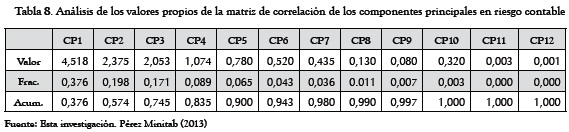
En este caso vemos que la Tabla 9 muestra como sus mayores correlaciones positivas a las parejas:
GDE-CP2, RSP-CP9, LS-CP6, LG-CP8, RAR-CP3 y GIP-CP1
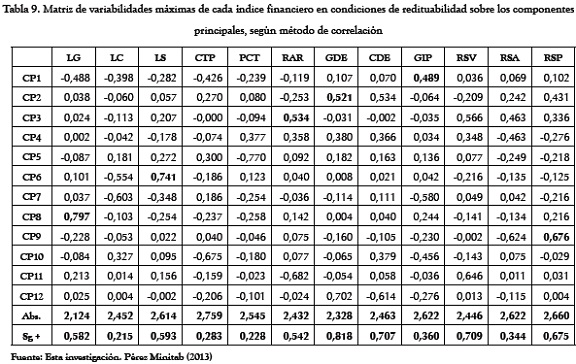
En tanto la Tabla 10 presenta como mayores correlaciones positivas:
LC-CP9, RSP-CP7, GIP-CP2, LG-CP1, RAR-CP3 y GDE-CP6
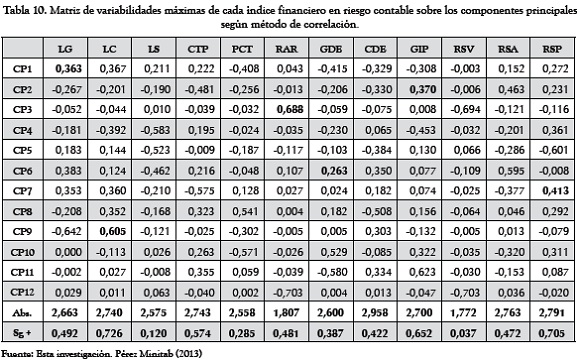
El criterio aquí aplicado para la selección de las variables mejor proporcionadas como para asumir una representación explicativa de la variabilidad de los datos, ha sido el de incluir la mayor diversidad posible de los tipos de indicadores (liquidez, riesgo y redituabilidad); estos son: LG, RAR y RSP.
3. Validación
Como quiera que las licencias temporales de software presentan limitaciones en su disponibilidad, se ha preferido ilustrar la validación de resultados utilizando una técnica manual, usualmente considerada parte del llamado análisis discriminante.
3.1. Para el método de la covarianza
Las escalas sumatorias de las puntuaciones que tienen los componentes principales (Terradez M., 2002) se pueden calcular mediante la expresión:
CPij = ai1. Z1j + ...+aik. Zkj = Σ ais . Zsk, (5)
en la que "a" son los coeficientes y los "Z" los valores estandarizados que tienen las variables en cada uno de los sujetos de la muestra. Frecuentemente, la puntuación de las dos primeras componentes es suficiente como indicador sintético (varianza explicada a un nivel mínimo de 70-90%), mientras que en otras se requiere de la acumulación de varios componentes (Grané, 2002).
El Cuadro 1, muestra la acumulación del porcentaje de varianza explicada, dados por la Tabla 5 (Por ejemplo, el primer término es dado según: LG: 0,424+0.105-0,7360,287-0,269-0,293+0,147-0,059 = -0,968).

Utilizando estos datos como coeficientes en la ecuación 5, la escala sumatoria de la puntuación de los componentes principales aplicables a cada una de las empresas de la muestra en condiciones de redituabilidad, por el método de covarianza, estará dado según:
Z = (-0,968)LG + (2,009)LC + (0,485)LS + (-0,712)CTP + (0,874)PCT + (-0,054)RAR + (0,367)GDE + (0,273)CDE + (0,616) GIP + (-0,918) RSV + (-0,165)RSA + (-0,264) RSP
La aplicación de esta ecuación a las 63 empresas en redituabilidad de los datos originales nos proporciona un criterio de clasificación de tales empresas. Según nuestra conveniencia, aplicamos el artificio estadístico del análisis discriminante señalando los primeros 31 Zetas más altos como empresas "fuertes" en redituabilidad, las cuales requieren sustituir esta asignación "no numérica" por el número 2, mientras que a las restantes 32 Zetas señalables como empresas en redituabilidad "aceptables" les es asignado el número 1. Luego, se toma una muestra que incluye 25 empresas fuertes y 25 empresas aceptables para que mediante una operación de regresión en Excel® otorgue continuidad a las variables LC, GDE y GIP anteriormente señaladas como capaces de asumir una representación explicativa de la variabilidad de los datos. Así, obtenemos, de la ecuación 5, la siguiente expresión:
Y = -0,5604 + (0,4142)LC + (0,5068)GDE + (1,0239) GIP
Finalmente se prueba esta expresión en las 13 empresas restantes (6 fuertes y 7 aceptables), es decir, para determinar si estas empresas se clasifican correctamente como fuertes o aceptables. (0 errores en empresas restantes de 16 totales en datos originales). Se concluye que el modelo es apto (75%) para predecir si una empresa es fuerte o aceptable con base en los indicadores seleccionados del análisis de variables del ACP y del análisis discriminante. El Cuadro 2 recoge los cálculos obtenidos.
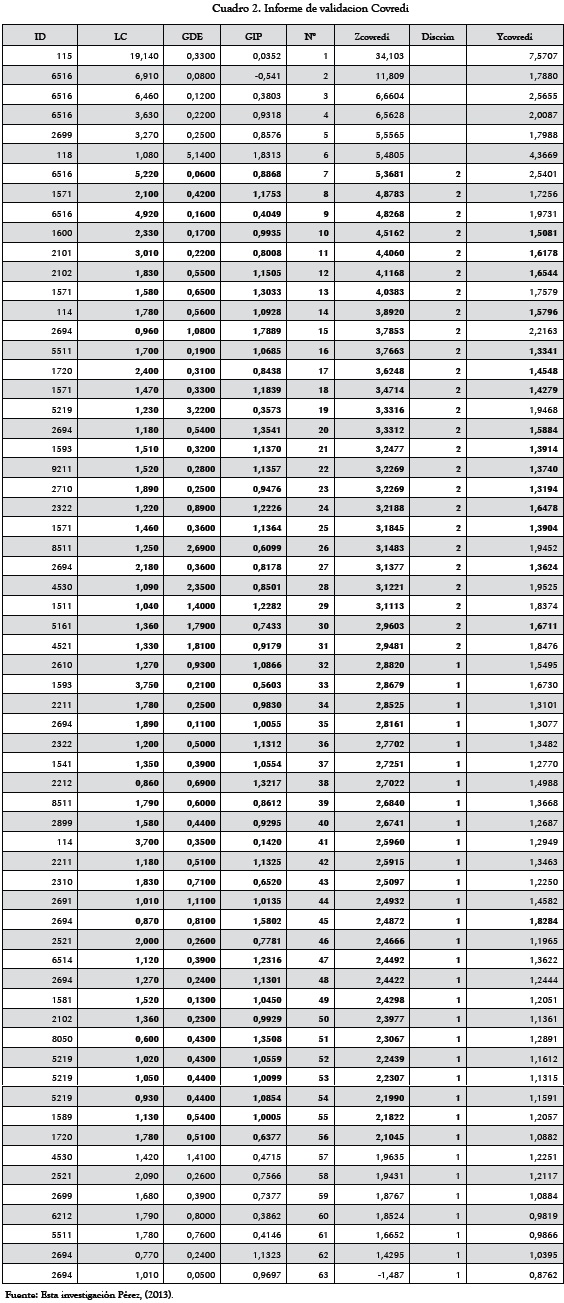
3.2. Para el método de correlación
El Cuadro 3 muestra la acumulación del porcentaje de varianza explicada dado por la Tabla 10 (Por ejemplo, el primer término es dado según:
LG: 0,363-0,267-0,052-0,181+0,183+0,383+0,353-0,208-0,642+0 = -0,068)
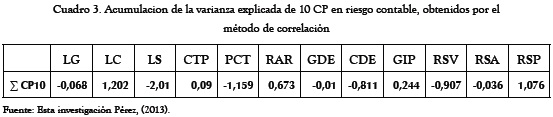
Utilizando estos datos como coeficientes en la ecuación 5, la escala sumatoria de la puntuación de los componentes principales aplicables a cada una de las empresas de la muestra en riesgo contable, por el método de correlación, estará dado según:
Z = (-0,068)LG + (1,202)LC + (-2,01)LS + (0,09)CTP + (-1,159)PCT + (0,673)RAR + (-0,01)GDE + (-0,811)CDE + (0,244) GIP + (-0,907) RSV + (-0,036)RSA + (1,076) RSP
La aplicación de esta ecuación a las 43 empresas colombianas en riesgo contable de los datos originales nos proporciona un criterio de clasificación de tales empresas. Según nuestra conveniencia, aplicamos el artificio estadístico del análisis discriminante señalando los primeros 22 Zetas más altos como empresas "recuperables" en redituabilidad, las cuales requieren sustituir esta asignación "no numérica" por el numero 1, mientras que a las restantes 21 Zetas señalables como empresas en redituabilidad "débiles" les es asignado el numero 2. Luego, se toma una muestra que incluye 15 empresas recuperables y 16 empresas débiles para que mediante una operación de regresión en Excel, otorgue continuidad a las variables LG, RAR y RSP anteriormente señaladas como capaces de asumir una representación explicativa de la variabilidad de los datos. Así, de la ecuación 5 se obtendrá la siguiente expresión:
Y = 0,6263 + (0,0016)LC + (0,4231)GDE + (0,4580) GIP
Finalmente se prueba esta expresión en las 12 empresas restantes (6 fuertes y 6 aceptables), es decir, para determinar si estas empresas se clasifican correctamente como fuertes o aceptables. (2 errores en empresas restantes de 7 totales en datos originales). Se concluye que el modelo es apto (84%) para predecir si una empresa es fuerte o aceptable con los indicadores seleccionados del análisis de variables del ACP y del análisis discriminante. El Cuadro 4 recoge los cálculos obtenidos.
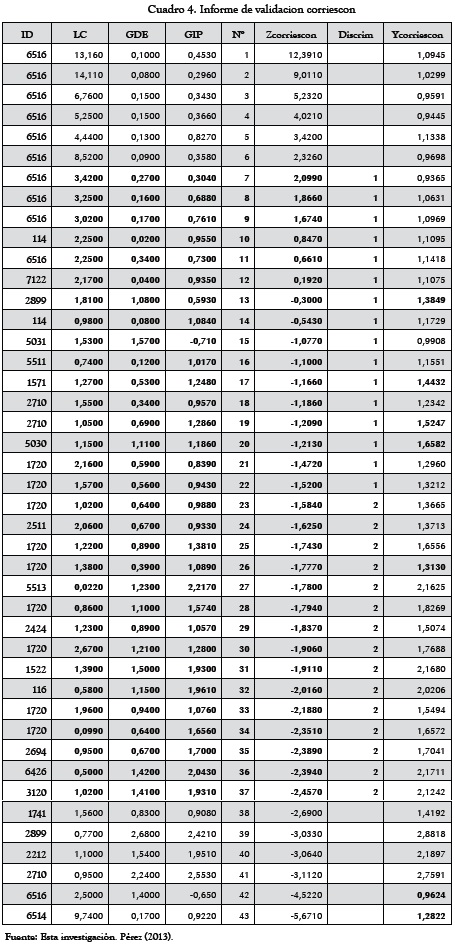
4. Discusión
Para caracterizar el arreglo de las cargas de los componentes retenidos en términos de las variables originales, nos valemos del diagrama de variables y del círculo de correlación, construidos con las matrices factoriales dadas por las Tablas 5 y 6, además de las Tablas 9 y 10.
Usualmente, los resultados se grafican en dos dimensiones de CP1 y CP2 para observar la variabilidad de los datos, según sus representaciones ya dispersas o ya concentradas, pero aquellos puntos destacados por sus ubicaciones distintas (especialmente los negativos) son los que cabría estudiar más a fondo. (Ver Figura 7 y 8).
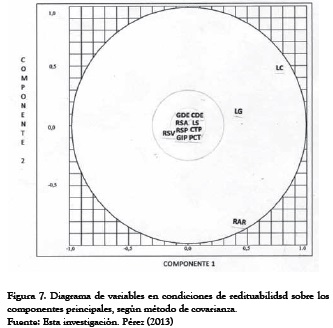

En estos gráficos en dos dimensiones CP1 y CP2, bajo el método de covarianza, puede observarse cierta concentración de las variables alrededor del origen de ambos componentes, aunque se destacan por sus valores distintos las variables que miden aspectos de liquidez y el indicador de riesgo rotación del activo realizable, con valores positivos en condiciones de redituabilidad, y negativos en condiciones de riesgo contable. Entonces, podemos decir, que las primeras muestran una fuerte correlación con el eje uno, mientras el segundo lo hace con el eje 2.
En cuanto a los gráficos bajo el método de correlación, (ver Figuras 9 y 10) puede observarse cierta dispersión de las variables, entre las que se destacan por su separación de las otras variables, los indicadores de apalancamiento GDE, CDE y GIP. En condiciones de redituabilidad mantienen correlación positiva respecto al primer componente, mientras que sucede todo lo contrario en condiciones de riesgo contable, cuando GIP presenta gran correlación respecto del segundo componente.
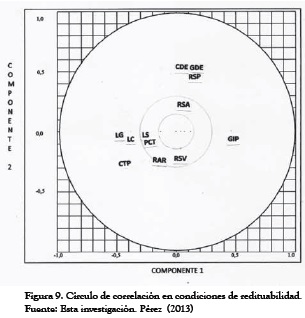

Por su lado, los indicadores de liquidez muestran mayor correlación respecto al primer componente en todas las condiciones. Después de examinar inicialmente los resultados de los dos primeros ACP, se pueden ensayar otras parejas de componentes principales en la más diversa gama de planos factoriales que se desee construir, unas veces en escalas absolutas y otras en escalas relativas, para estudiar el grado de correlación entre variables. En ambos tipos de gráficos mencionados, consideramos al primer componente principal como eje de las abscisas y al segundo componente como eje de las ordenadas.
De este modo, en el diagrama de variables, los puntos quedan inscritos dentro de un círculo de radio unidad. Estos puntos elementales son simplemente coeficientes de ecuaciones lineales que transforman los datos originales en cuentas (puntajes) indicativos de la carga respectiva sobre los ejes correspondientes.
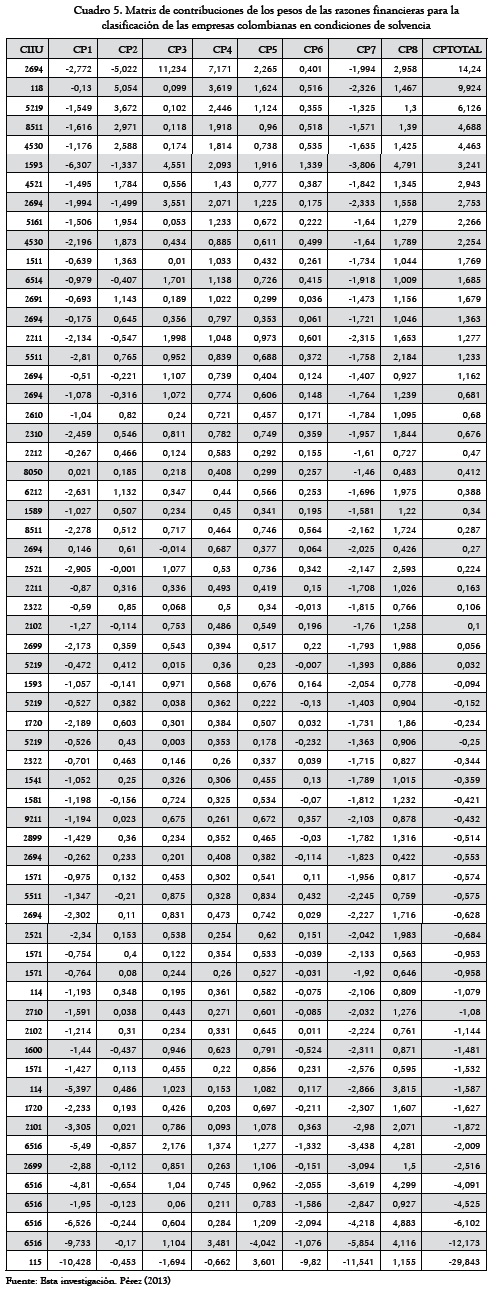
Después de agotado el estudio de la matriz factorial rotada (por ejemplo, la Tabla 5) si la misma fuese multiplicada por la matriz inicial de los datos (en este ejemplo, la Tabla 1) se obtendría una matriz de puntajes que viene a representar una estimación de las contribuciones de los factores de carga de las variables a cada empresa, lo cual permitiría una clasificación de la muestra de empresas (según el CPTOTAL). Se observa esta aplicación en el Cuadro 5.
Basados en el Cuadro 5, podremos construir el correspondiente plano factorial, así como el de la Figura 11:
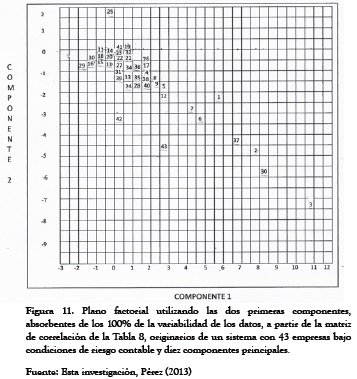
En la Figura 11 podemos observar que las empresas 3, 30 2, 37, 43, 6, 1, 7, 42 y 12 obtienen los mayores valores de la primera componente principal, mientras que las empresas 29, 16 y 10 obtienen los más bajos. Por otro lado las empresas 25, 41, y 19 obtienen los más altos valores de la segunda componente, mientras que las empresas 29, 16, 15 y 13 alcanzan los menores valores.
Para interpretar la nube de puntos individuales en un plano factorial, conviene tener en cuenta los siguientes aspectos:
- Los puntos individuales no quedan encerrados en un círculo de radio unitario.
- Un punto individual situado en el extremo de uno de los ejes significa que ese punto individual está muy relacionado con el respectivo componente.
- Cuando existen puntos individuales cercanos al origen significa que estos individuos tienen poca o ninguna relación con los dos componentes.
- Las proximidades entre puntos individuales se interpretan como similitud de comportamiento entre estos respecto de las variables. Por ejemplo, dos puntos individuales muy cercanos en el plano significa que ambos individuos tienen valores próximos en cada una de las respectivas variables.
- Un punto individual extremadamente alejado de la nube puede significar una de las dos situaciones:
- Existe un error en la introducción del dato o en la medición.
- Se trata de un individuo excepcional, el cual conviene sacar del análisis principal y usarlo como individuo suplementario, o bien, en el caso de que sean varios, analizarlos por separado.
- Ambos casos requieren la elaboración de un nuevo ACP.
- Cuando se presentan varias nubes de puntos muy diferenciadas, significa que puede haber varias subpoblaciones de individuos. Si el propósito del estudio es detectar grupos diferentes, el ACP ha logrado su objetivo. Pero si el objetivo es estudiar la interrelación entre las variables, la aparición de varias subpoblaciones de individuos interfiere en este análisis, entonces conviene hacer un ACP en cada una de estas subpoblaciones (González et al., 2002)
6. Conclusiones
Alguien podría pensar que teóricamente el ACP pareciera una aplicación dispendiosa o una elaboración complicada para el discernimiento por parte de los Contadores Públicos, pero ello no es así, pues de la mayor labor se ocupan los ordenadores y, es un hecho, el desempeño del nuevo contador estará cada vez mas involucrado entre herramientas informatizadas.
El mayor reproche que se le pudiera hacer al ACP es su falta de reconocimiento a la no linealidad de los datos pues ignora dependencias de orden mayor que puedan existir entre las variables. Sin embargo, este problema queda desestimado al seleccionar únicamente resultados óptimos sobre direcciones ortogonales.
Otra aceptación clave es que cada nueva matriz de mediciones, aún de las mismas variables sobre los mismos individuos, requiere un nuevo ACP. No resulta recomendable, por tanto, dejar sentada conclusión alguna acerca de cuáles son las variables capaces de evidenciar la reproducción de un estado de redituabilidad, o de riesgo contable, sino que ellas deberán ser identificadas en cada ocasión.
La primera recomendación para la eficaz utilización de esta técnica estadística por parte de los Contadores Públicos es la de entender por qué habría de ser importante la reducción del tamaño de cualquier problema estadístico, ya sea que esté relacionado con la diversidad de índices financieros, la clasificación de los resultados por áreas de operaciones o del servicio, la selección de clientes, la evaluación del desempeño por transacciones o productos, etc.
Además, es muy importante mencionar lo que tiene que ver con la adopción del software más apropiado para la ejecución del ACP. En este caso particular la utilización del Minitab tiene la ventaja de dejar toda la complejidad del cálculo estadístico a sus rutinas automatizadas, pero en general, e independientemente al software utilizado, la técnica del ACP solo podría ser explotada por aquellos Contadores Públicos con un conocimiento básico de Estadística descriptiva, una conceptualización de la Correlación y regresión lineal y múltiple y una base mínima del Álgebra de Matrices, tal como es el perfil del nuevo contador al servicio del control de gestión y la revelación de los sistemas de valoración.
Pero lo más relevante de este trabajo es que pone al servicio del profesional de la contaduría una herramienta más eficiente y más versátil para seleccionar índices financieros más objetivos.
Simplemente por estos motivos, este trabajo representa un avance en la eficacia de la intervención del profesional de la contaduría en procura de interpretar resultados contables financieros.
Vale la pena resaltar que los resultados obtenidos son propios de esta investigación, si bien en diversos procederes han servido de guía las descripciones temáticas propuestas por los autores referenciados al final del trabajo. El autor no ha podido conocer otro trabajo nacional sobre el tema, por lo cual da fe de su autenticidad y veracidad. Como quiera que las licencias temporales de software presentan limitaciones, se ha preferido ilustrar la aplicación con graficaciones de otros autores, igualmente, para finalizar, se ha preferido hacer la siguiente validación de resultados utilizando una técnica manual.
Notas
1 Articulo producto del proyecto de investigación "Métodos cuantitativos de la contabilidad" del grupo ¨Pensamiento Contable" del Programa de Contaduría Pública de la Universidad Simón Bolívar en la línea de de Gestión de Organizaciones, de la que el C.P Genner Maestre, Director del Programa, es el investigador principal.
Referencias bibliográficas
1. BARBOSA LANDIM, Paulo. Analise estatistica de dados geológicos multivariados. [en línea]. UNESP. [Rioclaro]: Departamento de geología aplicada, 2000. [citado 10 de enero de 2013]. Disponible en Internet: <http://www.rc.unesp.br/igce/aplicada/DIDATICOS/LANDIM/multivariados.pdf> p. 120. [ Links ]
2. BRONSON, Richard. Matrix methods: An introduction. 2ª Ed. San Diego: Academic Press. 1994. p. 503. [ Links ]
3. CASTRO BONAÑO, J. Marcos. Indicadores de Desarrollo Sostenible. Una aplicación para Andalucía [en línea]. Universidad de Málaga. [Málaga, España]: Facultad de Ciencias Económicas y Empresariales, febrero 2002 [citada 10 de enero de 2013]. Capítulo IV. Métodos de análisis aplicados. Disponible en Internet: <http://www.eumed.net/tesis-doctorales/jmc/cap04.pdf> p. 547. [ Links ]
4. GONZÁLEZ MARTIN, Pilar; DÍAZ DE PASCUAL, Amelia; TORRES LEZAMA, Enrique y GARNICA OLMOS, Elsy. Una aplicación del ACP en el área educativa. En: Revista Economía. Mérida. N° 9. (Sep. 2002); p. 18. [ Links ]
5. GRANÉ, Aurea. Análisis de Componentes Principales. Madrid: Universidad Carlos III, Departamento de Estadística. 2002. p. 30. [ Links ]
6. MOROZONI, Joao Francisco; OLINQUEVITCH, José Leonidas; HEIN, Nelson. Seleccion de Indices na Analise de Balancos. En: Contabilidade Financiera, Rev. de la Universidad de Sao Paulo: N° 41. (May. 2006); p. 13. [ Links ]
7. PÉREZ GRAU, Samuel. Currículo y modelo pedagógico en la educación a distancia. En: Revista colombiana de currículo. Vol 1 n° 1. (Oct. 2007); p. 11. ISSN: 1909-5198. [ Links ]
8. PÉREZ GRAU, Samuel. Modelo científico del sistema de funciones patrimoniales. En: Económicas CUC. Vol. 31 n° 31. (Dic. 2010); p. 10. ISSN: 0120-3932. [ Links ]
9. ROSILLO, Jorge. Fundamentos de finanzas para la toma de decisiones. Bogotá: UNAD. 2003. p. 429. [ Links ]
10. SCHLENS, Jonathon. A Tutorial on Principal Components Analysis. NY: Center for Neuronal Science, NYU. 2009. p. 12. [ Links ]
11. TERRADEZ GURREA, Manuel. Análisis de Componentes Principales. Cataluña: Universidad de Oberta. 2002. p. 11. [ Links ]
12. VILLARDON, José Luis Vicente. Análisis de Componentes Principales. Cataluña: UOC, Departamento de Estadística, 2002. p. 32. [ Links ]
13. VILLARROEL, L.; ÁLVAREZ, J. y MALDONADO D. Aplicación del ACP en el desarrollo de productos. En: Acta Nova. Rev. de la Universidad Mayor Simón Bolívar, Cochabamba. Vol. 3 n°3. (Dic. 2003); p. 9. [ Links ]
14. WARREN, Carl; REEVE, James; DUCHAC, Jonathan. Contabilidad Financiera, 11a Ed. México: Cengage Learning Inc. 2011. p. 816. [ Links ]
