











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
I. INTRODUCCIÓN
En los últimos tiempos las redes de datos han tomado gran importancia en el diario vivir de los seres humanos. Dichas redes son usadas en una gran cantidad de campos tales como la industria de las telecomunicaciones, la industria bancaria, la industria turística, la industria del entretenimiento, entre muchas otras. Sin embargo, con el aumento del uso de las redes de datos se han acrecentado también una serie de problemas con los cuales los administradores de redes deben tratar para garantizar el buen funcionamiento de la mismas, entre dichos problemas podemos encontrar aspectos como evitar la congestión de la red, garantizar que todos los recursos de la red se compartan de manera eficiente entre los usuarios y las aplicaciones, además de detectar tráfico inusual que pueda afectar el funcionamiento de la misma.
Con el fin de cumplir tales exigencias, se suele hacer uso de una serie de técnicas que permiten, entre otras cosas, controlar el flujo de la red, realizar la clasificación del tráfico, realizar predicciones de comportamientos futuros y detectar posibles amenazas. Estas técnicas están en constante evolución y en los últimos años han venido siendo objeto de estudios que pretenden mejorar su eficacia y brindar resultados más acordes a la realidad.
Uno de los grandes inconvenientes que presentan las técnicas convencionales es que, dada la inmensidad de datos que se deben tener en cuenta, se hace difícil priorizar la información de manera tal que se puedan atacar los aspectos más críticos que afectan el funcionamiento de la red. Lo anterior hace que se dificulte la toma de decisiones y por ende se presenten demoras en la ejecución de planes de corrección, prevención y optimización, lo que termina por afectar los indicadores de desempeño de la red.
Actualmente, la inteligencia artificial brinda las herramientas necesarias para poder analizar grandes volúmenes de datos de una manera más precisa y eficiente, sin necesidad de la intervención humana, de manera tal que podría ayudar a solucionar problemas relacionados a la administración de redes, entre ellos los problemas de control de tráfico mencionados anteriormente.
De acuerdo con lo anterior, el trabajo propuesto pretende realizar una revisión bibliográfica sobre los aportes realizados por la inteligencia artificial en la gestión o control de tráfico de las redes, con el fin de informar al lector sobre dichos aportes y las implicaciones de su implementación. Para esto, el artículo está organizado de la siguiente forma: en la sección II se presenta el concepto de control de tráfico, en la sección III se exponen los retos asociados al control de tráfico, en la sección IV se muestran algunas de las aplicaciones de la IA en el control de tráfico. Por último, en la sección V se plantean las conclusiones.
II. CONTROL DE TRÁFICO
Ocasionalmente, el control de tráfico de datos en las redes de comunicaciones es percibido como alguna de sus funciones o comprendido sólo parcialmente, es decir, se puede llegar a considerar el control de tráfico como el control del flujo de datos, el control de la congestión de la red o como la capacidad de permitir o denegar el acceso a los recursos de la red a sus usuarios. Pero como veremos a continuación el control de tráfico es un término más general y comprende entre otros los anteriores aspectos mencionados.
A. Control de la congestión
Para Chang y Su [1] el control de la congestión se refiere al mecanismo o conjunto de acciones tomadas por la red para afrontar las situaciones en las cuales el tráfico total ofrecido excede la capacidad misma de la red (congestión). Así mismo, la gestión del tráfico según el IETF [2], se refiere a la implementación de acciones que permita evitar o reducir la condición de congestión de tráfico en la red, a través de la clasificación.
Realizar una oportuna gestión de la congestión del tráfico es fundamental en una red y sus acciones deben tomarse de manera proactiva, ya que una vez congestionada la red, las acciones correctivas pueden ser muy complejas [3].
B. Contol de flujo
De manera sencilla el control de flujo es la capacidad de la red de controlar o restringir el flujo de datos que se transportan por ella de la manera más conveniente para la red [4]. Dentro de las funciones de este tipo de control encontramos la medición de esos flujos de datos, la cual nos proporciona información que permite: “comprender el comportamiento de las redes existentes, planificar el desarrollo y la expansión de la red, cuantificar el rendimiento de la red, verificar la calidad del servicio de la red y atribuir el uso de la red a los usuarios” [5].
C. Control de tráfico
En las redes de transmisión de datos, la gestión o control del tráfico de datos implica varias acciones que buscan prevenir y/o reducir la congestión (gestión de la congestión) a partir de, por ejemplo, técnicas como el control de flujo; para cumplir con los objetivos de rendimiento de la red [1]. Entonces, el control del tráfico de la red es el proceso de administrar, controlar o reducir el tráfico de la red. Este proceso se realiza con el fin de utilizar de manera eficiente el ancho de banda de la red, mantener baja la latencia, ofrecer calidad de servicio y compartir de manera justa los recursos entre muchos usuarios y aplicaciones mediante la gestión del flujo de tráfico [6].
D. Técnicas de control de tráfico
Existen algunas técnicas comúnmente empleadas para controlar el flujo de datos que circulan por una red de datos, en este apartado tomamos el enfoque de Noormohammadpour y Raghavendra [6], para mencionar algunas de esas técnicas. Los autores sugieren un grupo de seis técnicas:
Control de transmisión: Esta técnica controla el flujo de datos enviados por la red, cuyo objetivo es reducir la latencia, reducción de la tasa de error/retrasos, maximizar la utilización y la equidad en la repartición de recursos. Por otro lado, los retos que se deben asumir con esta técnica son la ráfaga de tráfico y el reordenamiento de paquetes [6].
Conformación del tráfico o Traffic Shaping: consiste en “reprogramar (retrasar) los paquetes (o tramas) hasta que alcanzan el ancho de banda especificado o los límites de ráfagas. Dado que tales retrasos implican colas que casi siempre son finitas y, una vez que están llenas, el exceso de tráfico casi siempre se descarta, la configuración del tráfico casi siempre implica también la vigilancia del tráfico” [6].
Priorización: en esta técnica se establecen ciertos niveles o clasificaciones a los flujos de datos según su prioridad y de acuerdo con esta, son manejados, permitiendo reducir la latencia y la tasa de error/retrasos [6].
Balanceo de carga: Esta técnica permite aumentar el nivel de uso de la red en general, al distribuir la carga de los flujos de datos de manera equilibrada, evitando que ciertos enlaces de la red no se utilicen y por el contrario otros enlaces se vean saturados o congestionados [6].
Multipathing: permite fraccionar un flujo de datos en varios subflujos, para que estos sean enviados a través de diferentes rutas. En consecuencia, el receptor se debe encargar de tomar cada subflujo y posteriormente ordenarlos, aumentando la utilización [6].
Programación o Scheduling: Su objetivo principal es minimizar el tiempo que tarda un flujo de datos desde que sale del emisor hasta llegar a su destino final. Esto a partir de una formulación de la optimización de tiempo de respuesta de la red, que contempla varias métricas como la utilización, latencia y equidad de recursos, por lo que suele ser costoso a nivel computacional [6].
III. RETOS DEL CONTROL DE TRÁFICO
Uno de los grandes inconvenientes que se presentan al realizar el control de tráfico de una red es la cantidad y heterogeneidad de los datos que se deben tratar para controlar dicho tráfico. Esto se debe a que, como explican Li y Moore [7], el tráfico de una red es el producto de un sistema en el que interviene diferentes factores, entre los cuales podemos encontrar los hosts, las aplicaciones, los protocolos y por supuesto a los usuarios que interactúan entre si haciendo uso de los servicios brindados por la red. De esta manera, en cuanto más complejo sea el sistema sobre el cual funciona la red mayor será el tamaño y diversidad de la información que tendremos que tratar para poder tener control sobre el tráfico de la misma.
De igual manera, como indica Amaral et al. [8], se pueden presentar casos en el que dentro de una red que incluya una amplia gama de aplicaciones, las muestras de flujos no se encuentren correctamente etiquetadas, lo que representa un gran inconveniente debido a que se dificulta encontrar relaciones entre los datos que obtenemos del tráfico de la red y, por ende, ejercer un control de tráfico efectivo.
Por último, al realizar el proceso de control de tráfico se puede presentar algunos eventos que dificultan la medición del tráfico de la red [6]:
La aparición de ráfagas en el flujo de datos que dificultan la medición del tráfico ya que los resultados pueden variar dependiendo del lugar de la red en el cual se realice dicha medición.
Cuellos de botella que se generan cuando varios hosts envían el tráfico hacia un mismo destino de manera concurrida.
El uso excesivo de CPU en procesos como el reordenamiento de paquetes.
IV. APLICACIONES DE LA IA EN EL CONTROL DE TRÁFICO
A. Clasificación del tráfico de una red
Para la IETF [9], la clasificación del tráfico es un proceso automatizado que clasifica el tráfico de la red de acuerdo con diferentes parámetros como lo son el puerto, el protocolo, etc. La clasificación de tráfico juega un papel importante en la seguridad y la gestión de la red, debido a que permite detectar anomalías y desmejoras en la calidad del servicio con el fin tomar acciones tales como bloquear los flujos y recursos de la red [10].
Existen cuatro métodos principales de clasificación de tráfico:
Inicialmente, tenemos la clasificación de tráfico basada en puertos, en la cual se hace uso del puerto asignado por la Autoridad de Números Asignados de Internet (IANA) para realizar la identificación de las aplicaciones que hacen uso de la red [8]. Este método fue ampliamente usado en sus inicios, pero pasó a estar deprecado luego de que aparecieran aplicaciones que hacían uso de mecanismos de asignación de puertos dinámicos y de técnicas que permitían ocultar la información relacionada al puerto de la aplicación.
En segundo lugar, tenemos a la clasificación basada en inspección profunda de paquetes (DPI), en la cual se inspecciona la información de los paquetes en busca de patrones que identifiquen la aplicación que generó el tráfico [8]. Este método tiene algunas desventajas entre las que podemos encontrar el alto consumo de recursos que se usa en la inspección de los paquetes y la imposibilidad de operar sobre paquetes generados por aplicaciones que hacen uso de mecanismos de encriptación.
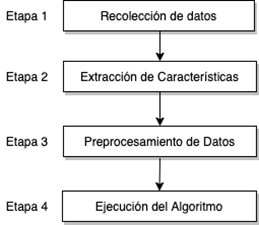
Finalmente, tenemos los métodos basados en estadística y los basados en el comportamiento, en los cuales se suelen usar técnicas de Machine Learning que permiten clasificar el tráfico extrayendo patrones de datos. Normalmente, este proceso de clasificación consta de cuatro etapas: (1) la recolección de datos, en la cual se captura el tráfico de la red haciendo uso de una herramienta construida para este fin; (2) la extracción de características, en la cual se seleccionan las características que se usarán para realizar la clasificación del tráfico; (3) el preprocesamiento de los datos, en el cual la data extraída es transformada a un formato que pueda ser procesado y (4) la ejecución del algoritmo de aprendizaje automático, en la cual se procesa la data formateada en la etapa anterior con el fin de generar los modelos de clasificación deseados [10].
Para realizar la clasificación de tráfico se puede hacer uso de sistemas de aprendizaje supervisado, sistemas de aprendizaje no supervisado y sistemas híbridos de aprendizaje [8]. Si se quiere clasificar el tráfico a través de un sistema de aprendizaje no supervisado, se debe tener una data correctamente etiquetada, de lo contrario no va a ser posible realizar una caracterización de la misma y, por ende, no se va a poder realizar dicha clasificación. Este problema no se presenta en los sistemas de aprendizaje no supervisado, ya que en dichos sistemas se hace uso de técnicas de representation learning, con las cuales es posible descubrir características no visibles a partir de datos brutos para que posteriormente se pueda realizar el proceso de clasificación [11]. Es necesario tener en cuenta que en los sistemas de aprendizaje no supervisado no se toma en cuenta la data etiquetada, lo cual puede llevar a restarle precisión al modelo de clasificación resultante. Finalmente, los sistemas de aprendizaje semi supervisados permiten suplir aquellos escenarios en los que contamos con una pequeña cantidad de datos etiquetados y una gran cantidad de datos sin etiquetar, de esta manera podemos usar ambos tipos de datos para generar un modelo de clasificación con una mejor de precisión de la que obtendríamos si solo hiciéramos uso de la data no etiquetada (sistema no supervisado).
Existen varios algoritmos de clasificación basados en machine learning, entre los algoritmos más conocidos podemos encontrar las máquinas de vector soporte (SVM) [12],[13],[14],[15],[16] los algoritmos basados en redes neuronales [17],[18],[19],[20] algoritmos basados en árboles de decisión [21],[22],[23] y los algoritmos de agrupamientos tales como K-means y esperanza-maximización (EM) [24], [25].
B. Predicción de tráfico de la red
Para Vinayakumar, Soman y Poornachandran [26], la predicción de tráfico tiene como objetivo determinar el tráfico que tendrá una red en el futuro basándose en los datos de tráfico que se han obtenido hasta un momento determinado. La predicción del tráfico de la red informática puede ser crucial para los proveedores de red y la gestión de la red informática en general. Es de gran interés en varios dominios, como aplicaciones adaptativas, control de congestión, control de admisión y asignación de ancho de banda [27]. Además, al mejorar esta tarea, se pueden crear herramientas efectivas de control de tráfico y detección de anomalías, lo que da como resultado ganancias económicas a partir de una mejor gestión de recursos [28].
Existen varias técnicas de inteligencia artificial que son usadas para predecir el tráfico de una red, entre las cuales podemos encontrar técnicas basadas en redes neuronales tales como el perceptrón multicapa (MLP) [28][29], el codificador automático apilado de aprendizaje profundo (SAE) [30], [31] y las redes neuronales recurrentes (RNN) [32], [33], [34]. Como se evidencia en [27], estas tres técnicas han demostrado ser capaces de ajustar y predecir el tráfico de una red con alta precisión, por lo cual se convierten en una herramienta de gran ayuda en el proceso del control de tráfico.
C. Seguridad de la red
Cuando hablamos de seguridad es imprescindible hablar de una gestión de los riesgos, el caso de la seguridad en las redes de datos no es la excepción y ésta debe contemplar procesos como el monitoreo de la red, seguridad de la protección, prevención de intrusiones, gestión de incidentes, configuración segura y la educación y concientización de usuarios en el uso adecuado de la red; para garantizar confidencialidad, integridad y disponibilidad [35].
Infortunadamente, a la par de la evolución a las técnicas y herramientas que protegen las redes, han evolucionado también, las técnicas y herramientas que los ciberdelincuentes emplean para atacar los sistemas. Por lo anterior, la seguridad no deja de ser una constate preocupación en la gestión del tráfico de red, lo que ha motivado la permanente investigación en el campo, dejando en evidencia el gran interés en las técnicas proporcionadas por la inteligencia artificial (IA) para confrontar los retos que la seguridad informática afronta en la actualidad. La IA brinda flexibilidad y capacidad de aprendizaje al software que ayuda a combatir los delitos cibernéticos, a partir de numerosos métodos inspirados en la naturaleza “como inteligencia computacional, redes neuronales, agentes inteligentes, sistemas inmunes artificiales, aprendizaje automático, minería de datos, reconocimiento de patrones, lógica difusa, heurística, etc., que han jugado un papel cada vez más importante en la detección y prevención de delitos cibernéticos” [36].
Adicional a la evolución de las técnicas y herramientas de los ciberdelincuentes, la evolución de las redes en sí mismas, con la aparición de nuevas tecnologías como la quinta generación de redes móviles (5G), implica nuevos retos en la protección de redes, ya que los sistemas de protección actuales pueden convertirse en insuficientes e incluso obsoletos. Por esto, las redes 5G requerirán la inclusión de nuevas tecnologías basadas en el aprendizaje automático y aprendizaje profundo [37], [38], [39]. No obstante, para esto aun hace falta mucha investigación, pues implementar sistemas de aprendizaje automático en las redes de 5G puede incluso traer problemas de seguridad como permitir una mayor facilidad para el seguimiento de usuarios y de ataques de violación de la privacidad [40].
Dado que la clasificación del tráfico es uno de los pasos fundamentales para la detección de anomalías en la red o el sistema de detección de intrusos (IDS) y desempeña un papel importante en el dominio de la seguridad de la red [41], [42]; el aprendizaje automático se ajusta a esta necesidad permitiendo la predicción de comportamientos, basándose en propiedades o características previamente conocidas, aprendidas a partir de unos datos de entrenamiento. Por otro lado, en los escenarios en los que dichas propiedades son desconocidas en los datos se puede dar uso de los métodos del aprendizaje profundo, ya que estos se centran en el descubrimiento de nuevas propiedades [42], [43]. Pero como se menciona, ML y DL se basan en datos independientemente de que deban o no ser previamente etiquetados, por esto una adecuada elección y uso de los datos son requisitos previos para lograr realizar una investigación de seguridad relevante [44]. Algunos de los conjuntos de datos de entrenamiento con fines de seguridad se pueden consultar en [43], [44], [45].
1) Monitoreo de la red
Como indican Vinayakumar et al. [44], el monitoreo de la comunicación de red incluye sensores que recopilan metadatos de la red, herramientas que brindan una sesión de red detallada y un monitoreo profundo de paquetes o análisis basado en firmas. Durante el monitoreo, los eventos de registro discretos se usan comúnmente para proporcionar indicadores de ataque, donde los eventos de sistema de archivos y de nivel de proceso se usan a menudo para identificar ciertos tipos de técnicas diversas.
Dentro de los inconvenientes encontrados en el monitoreo de la red, encontramos que estos actúan o responden con frecuencia de manera reactiva incluso en muchos sistemas que usan métodos de ML. En respuesta a esto, se puede extender la capacidad de los IDS monitoreando los flujos de tráfico de red con técnicas de DL, ya que el aprendizaje profundo puede contribuir a la previsión proactiva, como lo propone [35].
2) Detección de intrusión
El IDS es el sistema que se encarga de monitorear o supervisar los elementos que comprenden la red, para entre otros verificar su estado y descubrir, determinar e identificar anomalías en el uso de la misma [35], [43] y [44]. Sin embargo, como se indica en [46] estos sistemas aún presentan algunos retos como mejorar la precisión de la detección, reducir las falsas alarmas y la detección de ataques desconocidos; por esto gran número de investigaciones en este campo se han centrado en desarrollar sistemas de detección que aprovechen los métodos de ML.
Con la aplicación de la inteligencia artificial, se puede lograr una clasificación, procesamiento y análisis efectivos de la información de datos de la red. A través de este proceso, algunos datos sospechosos que existen en la red podrían ser filtrados de manera efectiva y los usuarios también pueden obtener informes de inspección detallados [47].
La aplicación de la IA ofrece variadas ventajas dependiendo del método empleado en los sistemas de detección y prevención de intrusiones (IDPS) como el procesamiento de información de forma paralela en las redes neuronales artificiales, adaptación al entorno y las preferencias de usuario en los agentes inteligentes, auto adaptabilidad y auto organización en los sistemas inmunes artificiales, optimización con algoritmos genéticos y la interoperabilidad en la lógica difusa [36].
3) Métodos y algoritmos de IA para seguridad
Dentro de la literatura académica existe variada cantidad de investigaciones y desarrollo de sistemas basados en métodos principalmente de machine learning y deep learning para la detección de intrusos como parte del sistema de seguridad de la red.
Entre los algoritmos de ML considerados como poco profundos más comúnmente utilizados para la seguridad en redes encontramos: máquinas de vectores de soporte, k vecinos más próximos, árboles de decisión, Naïve Bayes, las redes neuronales artificiales y regresión logística, aunque podemos encontrar otros como clustering, aprendizaje en conjunto híbrido, entre otros. Así mismo, los algoritmos y métodos del aprendizaje profundo, más empleados son: red de creencias profundas (Deep Belief Network; DBN), redes neuronales recurrentes (Recurrent Neural Networks; RNN), redes neuronales convolucionales (Covolutional Neural Networks; CNN), red generativa antagónica (Generative Adversarial Network; GAN), entre otros [36], [43], [44], [45], [46]. Encontramos que en [36] se resume las ventajas de la utilización de algunos de los algoritmos mencionados en los sistemas de detección y prevención de intrusiones, [43] y [44] describen el conjunto de datos utilizados para la ciberseguridad y algunos de los algoritmos de ML y DL más comunes. En [46] se realiza un estudio en el que se compara los métodos superficiales o poco profundos sobre los métodos profundos o de deep learning en cinco características: tiempo de ejecución, número de parámetros, representación de características, capacidad de aprendizaje e interoperabilidad; mostrando mayores ventajas como es el caso del rendimiento en los algoritmos de DL.
Algunos ejemplos de trabajos que han implementado los anteriores algoritmos mencionados u otros relacionados se describen brevemente a continuación:
[41] [48] hacen uso de técnicas de representación de imágenes para detección de malware; realizan la clasificación de tráfico de malware basado en las redes neuronales convolucionales con el enfoque de aprendizaje por representación. Este enfoque toma los datos del tráfico sin procesar y son representados en imágenes las cuales permiten clasificar el tipo de tráfico correspondiente, ya que se logró determinar que, para un tipo de tráfico particular, las imágenes generadas son muy similares entre sí; permitiendo distinguir el tráfico de malware del tráfico de otras aplicaciones de usuario (correo, video juegos, skype, etc) e incluso distinguir el tráfico entre diferentes tipos de malware.
Los Ataques DoS y DDoS llevan décadas preocupando a los gestores de seguridad en los sistemas, por su capacidad de dejar indisponibles los servicios, para estas preocupaciones en [49] y [50] nuevamente se propone la utilización de métodos de ML para la detección de estos ataques. En [49] los autores estudian la construcción de un modelo de ML basado en el análisis de regresión múltiple para la detección de ataques DDoS, mientras que en [50] se presenta un sistema basado en ML para la detección de DoS, en el que luego de explorar con varios algoritmos en la fase de clasificación determinan que random forest (RF) es quien muestra una mayor precisión. Se destaca que según los resultados obtenidos en [50] se obtiene una tasa de detección del 96%, con alta precisión y una tasa baja de falsas alarmas.
Algunas de las herramientas convencionales de detección de intrusiones en la red suelen presentar niveles considerables de falsas alarmas. Debido a esto, los autores en [51] deciden diseñar un enfoque para la detección de tráfico de red malicioso basado en un clasificador de red neuronal artificial que permite identificar patrones de shellcode, obteniendo mejores resultados de los métodos de detección que se basan en firmas, logrando una tasa de falsos positivos inferior al 2% durante pruebas con más de 400.000 muestras de contenido de archivos de tráfico de red benigno.
D. Optimización de ruteo
La optimización de enrutamiento permite un uso con mayor eficacia de los recursos de red y mejorar la calidad del servicio [52]. Por esto, suele ser de gran interés para los proveedores de internet, pero no solo se aplica a las redes de datos tradicionales sino también a otros tipos de red como la creciente Internet de las cosas IoT [53].
Existe algoritmos de optimización como la colonia de hormigas que puede ser muy efectivos en la optimización del enrutamiento y por esto varios protocolos de enrutamiento se basan en este tipo de algoritmos [54]. Pero estos algoritmos no son adecuados para optimizaciones en tiempo real debido a que al ser un método heurístico implica un elevado costo computacional. Sin embargo, gracias a las virtudes de ML se puede optimizar el enrutamiento en tiempo real, principalmente con el aprendizaje con refuerzo [52].
Algunas soluciones para la optimización del tráfico sugieren optimización únicamente de los flujos que sean considerados críticos, lo que implica nuevamente un proceso de clasificación el cual puede ser de alta carga de computacional, por lo cual [55] proponen la CFR-RL (Critical Flow Rerouting-Reinforcement Learning). CFR_RL utiliza una red neuronal la cual se entrena mediante el aprendizaje automático por refuerzo con políticas de selección del tráfico critico en los diferentes tipos de tráfico y logra un rendimiento óptimo al redirigir entre el 10% y el 21,3% del tráfico total.
E. Algoritmos aplicados al control de tráfico
De acuerdo con las fuentes consultadas en el presente artículo, en la Tabla I se realiza un consolidado de los diferentes algoritmos y métodos usados para el control de tráfico.
Tabla I Algoritmos aplicados al control de tráfico.
| Área de Aplicación | Algoritmos/Métodos | Documento |
|---|---|---|
| Clasificación del tráfico | Máquinas de vectores de soporte. (SVM) | Sun, Chen y Su. [12] Cao et al. [13] Dong. [14] Punitha y Mala. [15] Saber, Fergani y Abbas. [16] |
| Redes neuronales | Ang et al. [17] Li et al. [18] Moreira et al. [19] Mengmeng, Xiangzhan y Likun. [20] |
|
| Árboles de decisión | Li, et al. [21] Tong, Qu y Prasanna. [22] Nair y Sajeev. [23] |
|
| K-means y esperanza-maximización | Singh. [24] Liu et al. [25] |
|
| Predicción del tráfico | Perceptrón multicapa (MLP): red neuronal | Prado, Salem y Santos. [28] Nikravesh et al. [29] |
| Codificador automático apilado (SAE): red neuronal | Jin et al. [30] Li et al. [31] |
|
| Redes neuronales recurrentes (RNN) | Jaffry y Hasan. [32] Ramakrishnan y Soni. [33] Andreoletti et al. [34] |
|
| Seguridad de la red | Red de creencias profundas (DBN) | Vinayakumar et al. [44] Lima et al. [46] |
| Redes neuronales recurrentes (RNN) | Vinayakumar et al. [44] Lima et al. [46] |
|
| Red generativa antagónica (GAN) | Lima et al. [46] | |
| Redes neuronales artificiales | Dilek, Çakır y Aydın. [36] Wang. [43] Sambangi y Gondi. [45] Lima et al. [46] Ly y Yao [51] |
|
| Clustering | Wang. [43] Lima et al. [46] |
|
| Árboles de decisión | Wang. [43] Vinayakumar et al. [44] Sambangi y Gondi. [45] Lima et al. [46] |
|
| Naive Bayes | Wang. [43] Sambangi y Gondi. [45] Lima et al. [46] |
|
| Máquina de vectores de soporte (SVM) | Wang. [43] Vinayakumar et al. [44] Sambangi y Gondi. [45] Lima et al. [46] |
|
| K-vecinos más cercanos | Vinayakumar et al. [44] Sambangi y Gondi. [45] Lima et al. [46] |
|
| Autoencoder | Lima et al. [46] | |
| Máquina de Boltzmann restringida (RBM) | Lima et al. [46] | |
| Red neutral profundas (DNN) | Lima et al. [46] | |
| Redes bayesianas | Wang. [43] | |
| Redes neuronales convolucionales (CNN) | Farah et al. [41] Vinayakumar et al. [44] Zhang et al. [48] |
|
| Algoritmos de regresión múltiple | Saleem et al. [49] | |
| Random forest | Sanchez et al. [50] | |
| Modelos ocultos de Markov | Wang. [43] | |
| Optimización de ruteo | Redes neuronales | Zhang et al. [55] |
V. CONCLUSIONES
La inteligencia artificial ha contribuido de manera significativa en el mejoramiento de las técnicas usadas en el proceso de control de tráfico de redes de datos, en aspectos tales como la clasificación y predicción del tráfico, la seguridad en las redes y la optimización del ruteo. Esto debido a las bondades proporcionadas principalmente por los algoritmos de aprendizaje automático y aprendizaje profundo (velocidad, precisión, autoaprendizaje, entre otros), los cuales permiten a los sistemas de gestión de redes trabajar de una manera más autónoma, proactiva y eficiente, haciendo que las redes funcionen de manera óptima, mejorando con ello la calidad del servicio ofrecido a los usuarios.
Por otro lado, se puede apreciar una clara tendencia hacía la implementación de algoritmos de aprendizaje profundo sobre algoritmos de aprendizaje automático tradicional, debido a que con el aprendizaje profundo se requiere menos preparación de los datos obtenidos de la red para poder generar los modelos de clasificación necesarios en los procesos de optimización de ruteo e identificación de intrusiones. Entre los algoritmos más usados se destacan los basados en redes neuronales, debido a su gran capacidad en el procesamiento de información de forma paralela y su alta precisión.
De igual manera, se evidencia que, independientemente de los algoritmos aplicados, la fase de clasificación debe ser bien estructurada y planificada de acuerdo con el problema específico, ya que de esta fase depende la eficiencia en la ejecución del algoritmo y/o la precisión de sus resultados.
Para finalizar, se debe indicar que a pesar de que se han optimizado los mecanismos de procesamiento de la información y del constante avance en el aumento de los porcentajes de precisión y en la reducción de las tazas de error, sigue existiendo un pequeño porcentaje de error que en algunos escenarios hace necesaria la supervisión humana.

