











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
Introducción
De acuerdo con Altman y Saunders (1997), “las fuerzas que han impulsado el desarrollo de la medición del riesgo de crédito son el aumento de quiebras de bancos, la tendencia a la desintermediación y el aumento de la competitividad”. En esencia, Colombia no ha sido ajena a esta dinámica y muestra de ello, la Superintendencia Financiera (SF) ha impulsado normas que tratan de recoger las mejores prácticas en cuanto a la administración del riesgo, particularmente los principios y sugerencias desarrollados por el Comité de Supervisión Bancaria de Basilea (BCBS).
Actualmente, el exceso de demanda de crédito con el aumento en la proliferación de nuevos productos de crédito como la tarjeta de crédito y operaciones de libranzas, expone a los usuarios del sistema financiero a la posibilidad de obtener créditos con más de una entidad, luego en procura de tener una mayor certeza sobre el comportamiento crediticio de un cliente, es necesario que las entidades sean eficientes en identificar y gestionar el riesgo al que están expuestas.
Aunque los sistemas de administración de riesgo de crédito (SARC) han sido definidos como un elemento fundamental en la gestión del riesgo del negocio financiero, la definición de modelos de medición de riesgo de crédito a partir de información estadística no ha sido una práctica ampliamente utilizada en el sector de la economía solidaria. Se registran algunos avances en aspectos de carácter procedimental, sistemas de información y mecanismos de control, pero muchos fondos de empleados aún no cuentan con modelos de medición de riesgo crediticio que puedan servir como base de los modelos internos para el otorgamiento, el seguimiento y el cálculo de la pérdida esperada.
En la gran mayoría de este tipo de entidades existentes en el campo nacional, el mecanismo de pago predominante es el descuento por nómina, lo que reduce significativamente el riesgo crediticio asociado. Sin embargo, la entidad utilizada como muestra en este proyecto tenía la particularidad de que para más del 95 % de los asociados, el mecanismo de pago principal son los canales virtuales de las entidades financieras. A pesar del riesgo que podría implicar esta situación, la entidad estudiada como caso presentaba índices de morosidad inferiores al 1 %, muy por debajo de los estándares nacionales e internacionales. Esta situación genera un reto adicional en el proceso de modelación, ya que es preciso definir un nuevo umbral de morosidad más exigente que los estándares tradicionales.
Dado lo anterior, resaltamos el aporte de este estudio en la utilización de técnicas probadas en la medición de riesgo de crédito, para configurar un modelo de otorgamiento propio para una entidad del sector de la economía solidaria, considerando las particularidades de la base social de la entidad, que podrían generar potenciales situaciones de riesgo, aun considerando las dificultades para calibrar adecuadamente un modelo de medición en una población con muy bajo nivel de impagos.
Para alcanzar el objetivo, el artículo se desarrolla en cuatro secciones. En primera instancia, se presenta la revisión de la literatura sobre la evaluación del riesgo de crédito. En la segunda se explica la metodología que se utilizó para la construcción del modelo de pérdida esperada. En la tercera se describen los principales resultados. Finalmente, se concluye el documento.
Marco teórico
La modelación de riesgo de crédito es un tema de gran trascendencia e importancia para la adecuada gestión del riesgo financiero. Son numerosos los trabajos que se han realizado sobre temas relacionados con modelos de otorgamiento, scoring, estimación de pérdida esperada, manejo de provisiones y entorno económico, entre otros. Entre las más recientes publicaciones encontradas en la literatura figuran Bülbül, Hakenes y Lambert (2019), que realizan un completo análisis de los determinantes en las entidades financieras bancarias en Alemania para la adopción de prácticas relacionadas con la gestión de riesgo crediticio. Según los autores, los niveles de sofisticación de las herramientas usadas en los sistemas de administración de riesgo crediticio en los bancos estudiados, son fundamentalmente consecuencia de los niveles de competencia y concentración del mercado de préstamos.
González y González (2019) presentan una aproximación alternativa para la medición de riesgo de créditos en bancos europeos a partir de la información disponible en Google. La aproximación desarrollada se fundamenta en búsquedas lexicográficas, con el propósito de producir un índice que logre capturar el riesgo crediticio considerando elementos de carácter no financiero.
En la actualidad, llama la atención de los investigadores aspectos como la heterogeneidad de los patrones de créditos de los usuarios de créditos de consumo. Esta característica dificulta los procesos de estimación de covarianza entre los diferentes sujetos participantes del portafolio de crédito de las entidades. En este contexto, Madeira (2019) presenta un estudio basado en las estadísticas de créditos hipotecarios en Chile. Entre las conclusiones de dicho estudio, se simulan diferentes condiciones de heterogeneidad asociadas a los clientes hipotecarios en función de lineamientos de orden macroeconómico.
Recientemente se incluyen trabajos como el de Bennouna y Tkiouat (2019), que combinan técnicas de análisis discriminantes múltiple y regresión logística para formular un modelo de scoring para microcréditos en Marruecos. Chadwick (2018) analiza los impactos de la política monetaria sobre el crecimiento y la volatilidad de los créditos de consumo en Turquía. Su conclusión más relevante señala que la efectividad de la política monetaria se amplifica si se combina con medidas prudenciales en relación con el manejo de las provisiones asociadas a los portafolios de crédito. En este mismo sentido, otro de los trabajos relevantes, relacionados con la formulación de modelos de scoring crediticio, es el desarrollado por Fang y Chen (2019), quienes proponen un modelo de evaluación de crédito basado en el indicador Kolmogorov-Smirnov (KS) para medir el desempeño de los criterios de calificación considerados.
Una de las aplicaciones más interesantes en relación con el uso de las técnicas de medición de riesgo de crédito, es la que proponen autores como Walke, Fullerton y Tokle (2018), que utilizan las probabilidades de incumplimiento derivadas de modelos de riesgo de crédito como insumo para la segmentación de bases de datos de usuarios en cooperativas de créditos, con el fin de establecer políticas de tasas de interés basadas en niveles de riesgo crediticio, en lo que se conoce como estrategias de risk pricing. Otra aproximación reciente, en el mismo sentido, se presenta en el trabajo desarrollado por Kozodoi, Lessmann, Papakonstantinou, Gatsoulis y Baesens (2019), que proponen segmentos de utilidad a partir de la información brindada por los modelos de riesgo de crédito.
Otros autores como Abdolreza, Farnoosh, Konstantin y Frank (2017), proponen un nuevo método para la predicción de probabilidad, dado el incumplimiento basado en modelos difusos en reglas y métodos de conjunto que incorporan una amplia gama de variables macroeconómicas que proporcionan un aumento significativo en las medidas de rendimiento en comparación con las metodologías propuestas en la literatura. Yu, Ching, Gu y Siu (2017) consideran un modelo de riesgo de crédito en función de la intensidad de forma reducida con un proceso oculto del estado de Markov. Jokivuolle y Peura (2003) optan por procesos estocásticos correlacionados para el valor de la tasa de recuperación y los activos del deudor.
En el ámbito local, Echeverri (2006) en su trabajo de grado compara y evalúa las bondades y desventajas de los modelos de probabilidad lineal, el logit y el análisis discriminante. Gómez y Orozco (2009) comparan los modelos estadísticos de alerta temprana frente a los modelos de respuesta binaria en la estimación de la probabilidad de incumplimiento. Ochoa, Galeano y Agudelo (2010) incorporan el uso de variables cualitativas y cuantitativas en la construcción de un modelo de scoring, haciendo uso del análisis discriminante. Támara, Aristizábal y Velásquez (2012) describen el uso de modelos econométricos en la estimación de la probabilidad de incumplimiento, obteniendo estimaciones que generan provisiones esperadas de menor cuantía que las descritas por el ente regulador y la entidad financiera. Caicedo, Claramunt y Casanovas (2011) utilizan el enfoque de Merton en la estimación de las probabilidades de incumplimiento y las tasas de recuperación dado el incumplimiento. Salazar (2013), haciendo uso de la teoría de los árboles de decisión, logra determinar las variables que influyen en la capacidad de pago.
Contar con la estimación de la probabilidad de incumplimiento de los asociados solo es un paso, en el camino a cuantificar la pérdida esperada y estimar las provisiones de la entidad. Para ello, es necesario determinar de forma adecuada la demanda solvente del crédito, entendiendo como demanda solvente del crédito, la petición de crédito por parte de aquellos asociados que sean merecedores de ello, mediante la medición de su solvencia (López, 2014). Para que la medición de solvencia no se considere una tarea subjetiva, Basilea II y III establece que cada entidad puede basarse en los puntajes emitidos por las agencias de calificación o definir un sistema de clasificación para determinar dicha solvencia.
Desde el 2006, el Comité de Basilea para la supervisión bancaria, permite a los bancos utilizar sus propios modelos o enfoques de calificación, con el fin de calcular el capital requerido para la constitución de garantías de crédito, es decir, un modelo o enfoque basado en calificaciones internas de la entidad. Este concepto estipula la idea de la pérdida esperada como producto de tres parámetros: la probabilidad de incumplimiento (PI), la proporción de pérdida dada el incumplimiento (PDI) y la exposición del activo (EA). Siendo importante para la entidad contar con estimaciones confiables de cada componente (PI y PDI), con la finalidad de reducir la pérdida esperada y, por tanto, una reducción de capital de riesgo.
Todos estos referentes, dejan en evidencia el auge y constante desarrollo referente al análisis del riesgo crediticio, utilizando diferentes enfoques para la búsqueda de la probabilidad de incumplimiento.
Metodología
Dada la regulación bancaria de Basilea y teniendo en cuenta la reglamentación de la Superintendencia Financiera de Colombia (SFC), el estudio tiene como objetivo describir la construcción del modelo de scoring para una entidad de economía solidaria, a partir de la metodología de los modelos de regresión logística binaria, el cual permite calcular la probabilidad de incumplimiento (PI) en el camino a cuantificar la pérdida esperada y estimar las provisiones de una entidad de economía solidaria; teniendo presente que muchas de estas entidades aún no cuentan con modelos de medición de riesgo crediticio, que puedan servir como base de los modelos internos para el otorgamiento, el seguimiento y el cálculo de la pérdida esperada. Es así como la metodología se desarrolla teniendo en cuenta las siguientes tres fases:
Con el objetivo de determinar los parámetros que permitan estimar la pérdida esperada, de acuerdo con López (2014), se emplea un modelo de puntajes internos básico (conocido generalmente como modelo de scoring), en el cual la entidad estima las PI a partir de un modelo interno. Es así que para la construcción del modelo de scoring, se usó un modelo de regresión logística, el cual se construye a partir de variables de la historia de crédito del asociado, provenientes de las bases de datos propias de la entidad solidaria y de la Central de Información Financiera (CIFIN). Contando con la información de los créditos realizados por la entidad durante un periodo de 19 meses, y el estado actual del asociado en la central de riesgo CIFIN.
Para la modelación se utilizó el software estadístico R (R Core Team, 2020), usando la función glm, la cual permite configurar la modelación y evaluar fácilmente su desempeño. Los modelos de regresión logística permiten predecir el comportamiento de una variable categórica a partir de un conjunto de covariables discretas o continuas, siendo una de sus principales fortalezas. Estos pertenecen al conjunto de Modelos Lineales Generalizados introducidos por Nelder y Wedderburn (1972) y presentados en Dobson y Barnett (2018), parten de una variable de respuesta dicotómica o binaria (Y), la cual puede tomar dos valores: 0 (cumplido) y 1 (incumplido).
Con la finalidad de expresar la probabilidad de que un asociado sea incumplido con su obligación crediticia como función de otras variables influyentes, en la ecuación (1) se presenta la forma analítica en que esa probabilidad se vincula con las variables explicativas.
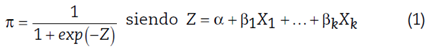
Donde π representa la probabilidad de default de un asociado (esto es, P(Y = 1) = PI), 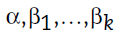 son los parámetros del modelo y exp denota la función exponencial. La expresión (2) es lo que se conoce como la función logística. Los parámetros de la regresión lineal pueden transformarse con la función logaritmo natural y se interpretan como la relación de odds de la variable dependiente (variable respuesta). Los odds corresponden al cociente entre el número eventos (número de veces que toma el valor de 1) sobre el número de no eventos (número de veces que toma el valor de 0). El modelo lineal generalizado no tiene supuestos teóricos sobre la distribución del error, si no que asume que se dispone de n variables independientes Y
i
, tal que todas y cada una sigue la misma distribución, que pertenece a la familia exponencial.
son los parámetros del modelo y exp denota la función exponencial. La expresión (2) es lo que se conoce como la función logística. Los parámetros de la regresión lineal pueden transformarse con la función logaritmo natural y se interpretan como la relación de odds de la variable dependiente (variable respuesta). Los odds corresponden al cociente entre el número eventos (número de veces que toma el valor de 1) sobre el número de no eventos (número de veces que toma el valor de 0). El modelo lineal generalizado no tiene supuestos teóricos sobre la distribución del error, si no que asume que se dispone de n variables independientes Y
i
, tal que todas y cada una sigue la misma distribución, que pertenece a la familia exponencial.
Para determinar qué variables presentan un aporte significativo en la explicación de la probabilidad de incumplimiento para la población de asociados pertenecientes a la entidad, y lograr estimar un modelo adecuado para la entidad, se emplea el procedimiento de selección de variables utilizando el test chi-cuadrado de razón de verosimilitudes (RV), el cual se basa en el estadístico desvianza definido en la ecuación (2) para el caso del modelo logístico.
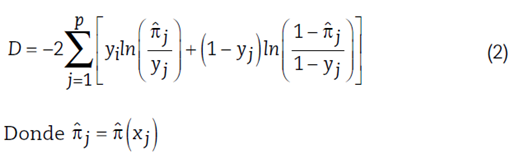
La desvianza compara el logaritmo de la verosimilitud del modelo ajustado con el logaritmo de la verosimilitud del modelo saturado; es decir, el modelo que contiene todas las variables de interés que se quieren evaluar y todas las interacciones posibles, para lograr el contraste de las siguientes hipótesis: H0: el modelo ajustado no difiere del modelo saturado, y H1: el modelo ajustado difiere del modelo saturado. El modelo saturado es el que contiene la mayor cantidad de parámetros como número de observaciones en el conjunto de datos. El modelo ajustado se refiere al modelo en el que se ha realizado una evaluación de las variables del modelo donde se prueba la significancia de estas en relación con las variables de estudio.
El estadístico 𝐷 presenta distribución asintótica 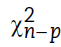 , donde p corresponde al número de parámetros en el modelo, en el que la hipótesis nula será rechazada para un nivel de significancia 𝛼 cuando
, donde p corresponde al número de parámetros en el modelo, en el que la hipótesis nula será rechazada para un nivel de significancia 𝛼 cuando 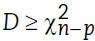 , equivalente a que el p-valor del contraste sea menor que el nivel de significancia 𝛼 dado.
, equivalente a que el p-valor del contraste sea menor que el nivel de significancia 𝛼 dado.
De lo anterior, se describen los pasos a realizar en el procedimiento de selección de variables, donde se evalúa el aporte que presenta cada una de las variables independientes en la explicación de la probabilidad de incumplimiento (PI):
Se parte de un modelo que incluye solo una variable predictora. Para determinar cuál es esa primera variable, se ajustan todos los posibles modelos de una sola variable, con cada una de las variables a evaluar.
Se elige el modelo que presente menor desvianza.
Se evalúa la significancia de la variable introducida mediante un test chi-cuadrado de RV.
Si la variable resulta significativa, se deja en el modelo y se continúa con la selección de la próxima variable a incorporar, añadiendo por separado cada una de las variables restantes.
Se repiten los pasos 2, 3 y 4, hasta que la inclusión de una variable no sea significativa.
La capacidad para predecir la probabilidad o el riesgo de default de un individuo debe ser el atributo más útil del modelo. Es decir, la capacidad predictiva de clasificar como “cumplidos” a aquellos que presenten una baja PI y como “incumplidos” a aquellos que presenten una alta PI.
En una segunda fase se valida el modelo valorando su nivel de ajuste y capacidad predictiva. Para ello se estima la curva ROC (receiver operating characteristic), la cual indica qué tanto poder de clasificación presenta el modelo (representación gráfica de la proporción de verdaderos positivos respecto a la proporción de falsos positivos). A su vez, la tasa de clasificaciones correctas se entiende como la medida de la bondad del ajuste global y se obtiene como el cociente entre los aciertos y el tamaño de muestra, dependiendo del punto de corte del cual se considera un individuo debe clasificarse como incumplido. Primero se clasifica el estado observado del asociado, si es incumplido (1) o cumplido (0), frente al estado pronosticado por el modelo ajustado, como se relaciona en la tabla 1.
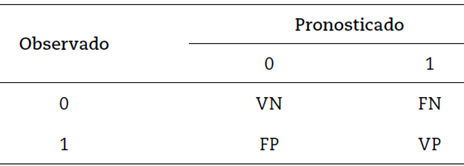
Donde:
VP (verdaderos positivos): son incumplidos y el modelo los clasifica como incumplidos.
VN (verdaderos negativos): son cumplidos y el modelo los clasifica como cumplidos.
FP (falsos positivos): son incumplidos y el modelo los clasifica como cumplidos.
FN (falsos negativos): son cumplidos y el modelo los clasifica como incumplidos.
Posteriormente se calcula la sensibilidad (es incumplido y ha sido correctamente clasificado) y especificidad (no es incumplido y ha sido correctamente clasificado) del modelo, utilizando las ecuaciones (3) y (4), respectivamente.


Con el fin de validar la consistencia del comportamiento obtenido con el modelo estimado, se valora el desempeño del modelo evaluando su poder de discriminación de cumplidos e incumplidos utilizando el método Hold Out repetido, en el que se generarán 100 muestras aleatorias de la base de datos original, manteniendo la estructura 80 % para la construcción del modelo y 20 % para la validación, como se realiza en la estimación del modelo.
La pérdida esperada es el valor que, por la naturaleza del negocio de crédito, las entidades están dispuestas a perder y se reflejan en la contabilidad como las provisiones. La pérdida se debe a que por diversas razones no todos los deudores pagan sus créditos; además, las entidades no pueden saber de manera anticipada el comportamiento de pago de cada deudor o las dificultades financieras futuras del mismo. Teniendo en cuenta los lineamientos de la SFC (Capítulo II: Reglas relativas a la gestión del riesgo crediticio), la estimación de la pérdida esperada en el marco del sistema de administración de riesgo de crédito (SARC) resulta de la aplicación de la ecuación (5).

Donde:
PE: pérdida esperada o provisión de cartera.
PI: probabilidad de incumplimiento. Se determina por la calificación que le otorga a cada asociado el modelo construido.
EA: exposición del activo. Corresponde al valor total neto de dinero que está exponiendo la entidad financiera al otorgar un crédito.
PDI: pérdida dado el incumplimiento. Depende del tipo de garantía que presente el asociado deudor.
Con el modelo de scoring construido y validado en las fases anteriores se estiman las PI para la entidad, mientras que para la estimación de la PDI se tiene en cuenta que un factor importante en la estimación de las pérdidas esperadas en el evento de no pago son las garantías que respaldan las operaciones. Por consiguiente, dado que no hay referentes en la estimación de las PDI por tipo de garantía en el sector solidario, se adoptan los parámetros definidos por la SFC en el capítulo II, como se presenta en la tabla 2.
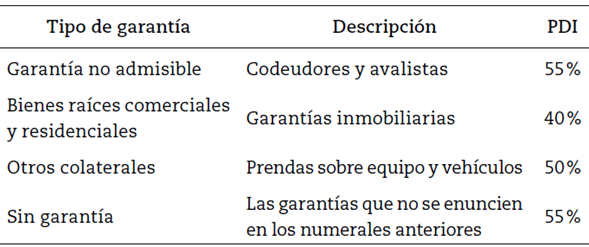
Finalmente, de acuerdo con la Circular Básica Contable y Financiera 004 de 2008: “todas las organizaciones solidarias sometidas al control y vigilancia de la Superintendencia de la Economía Solidaria, independientemente que califiquen y realicen la valoración establecida en la norma, deberán someterse al régimen de provisiones” y deberán constituir como provisión general, “como mínimo una provisión del uno por ciento (1%) sobre el total de la cartera de créditos bruta”. Sin embargo, según las Normas Internacionales de la Información Financiera (NIIF) para las pymes, lo que se llama “provisiones” de acuerdo con el Decreto 2649 de 1993, hoy se denomina “deterioro” y debe ser de forma individual (Cardozo, 2014); esto permite establecer el riesgo crediticio con el fin de registrar la contingencia de pérdida en la cuenta correctora. Es así que dejando a salvo la provisión general, además deberán mantener una provisión individual para la protección de sus créditos.
Resultados
A continuación, se presentan los resultados por cada una de las fases descritas en la metodología.
En la construcción del modelo de scoring (modelo de regresión logística), se inicia con el procedimiento de selección de variables, presentando los resultados de las pruebas chi-cuadrado de RV para cada uno de los modelos resultantes en cada paso realizado, como se observa en la tabla 3. Se encuentra que:
Del primer paso, se observa que la variable compromiso cuota presenta la mayor reducción de la desvianza, con una reducción de 18.59, siendo esta diferencia estadísticamente significativa, con un p-valor de 0.000, indicando que debe ser la primera variable en introducirse en el modelo.
Para el segundo paso, se parte del modelo con la variable compromiso cuota y se ajustan nuevos modelos para cada una de las variables restantes. De los resultados del test de RV sugiere incluir como segunda variable, la antigüedad en la entidad, ya que reduce la desvianza en 6.72, con un p-valor de 0.009535, siendo estadísticamente significativo.
Siguiendo el mismo procedimiento, la tercera variable a ingresar sería monto deuda, siendo estadísticamente significativa con un p-valor de 0.083.
Partiendo del modelo con las variables compromiso cuota, antigüedad y monto deuda, se ajustan modelos para cada una de las restantes variables y se realiza la prueba de RV. A este nivel, la variable máximo número de cuotas en crédito de consumo, aunque presenta la más alta diferencia en razón de verosimilitud (0.53), no es estadísticamente significativa con un p-valor 0.467. En este paso, la inclusión de cualquiera de las otras variables no mejora el modelo, por tanto, se queda con las variables ingresadas hasta el paso anterior.
Para finalizar, se probaron las diferentes interacciones entre las variables ingresadas, observando que el aporte del efecto de las interacciones no fue significativo con un p-valor de 0.224.
En resumen, de acuerdo con el procedimiento descrito, las variables a ingresar en el modelo como covariables en la explicación de la probabilidad de incumplimiento, son las variables compromiso cuota, antigüedad y saldo deuda por crédito de consumo, sin ninguna interacción de ningún orden, como se presenta en la tabla 3.
Tabla 3 Bondad ajuste del modelo: test chi-cuadrado de RV
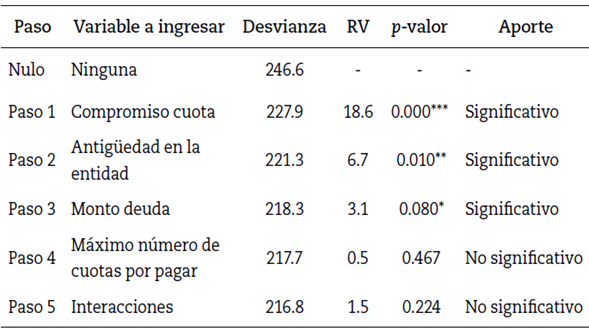
Significancia al *0.1; **0.05; ***0.01.
Fuente: elaboración propia con datos de la entidad.
Reemplazando las estimaciones de los parámetros de la tabla 4 en la ecuación (1), la probabilidad de incumplimiento para la entidad de economía solidaria queda expresada de la siguiente manera:

Contiene las variables significativas en la estimación del riesgo crediticio del asociado para la entidad y sus respectivas ponderaciones en el modelo.
Los contrastes sobre los parámetros se realizan a través del test de Wald. Según puede verse en la tabla 4, los p-valores asociados a las variables compromiso cuota y antigüedad son mucho menores de 0.05, mientras que para la variable monto de la deuda es menor a 0.1. Por tanto, se obtiene que las tres variables son significativas, es decir, sus coeficientes son significativamente distintos de 0, sus OR (Odds Ratios) son significativamente distintas de 1 y los intervalos de confianza para las mismas no contienen el 1.
Los parámetros del modelo se interpretan en términos de cocientes de ventajas. Se entiende que cuando se habla de una variable en concreto, las conclusiones extraídas asumen que el resto de las variables permanecen fijas.
Compromiso cuota, presenta un OR = 1.042, e indica que por cada unidad (1 %) que aumente el compromiso de la cuota de un asociado, aumenta algo más de una (1) vez la posibilidad a favor de ser incumplido en el pago de la obligación.
Antigüedad en la entidad, obtuvo un OR = 0.947, e indica que por cada año menos de antigüedad en la entidad, la posibilidad a favor de ser incumplido en el pago de la obligación aumenta en 1.06 veces.
Monto deuda por crédito de consumo, muestra un OR = 1.004, lo que significa que por cada $ 100 000 que aumenta el saldo de la deuda, aumenta en 1.04 veces la posibilidad a favor de ser incumplido en el pago de la obligación.
Tabla 4 Estimación de parámetros para la probabilidad de incumplimiento
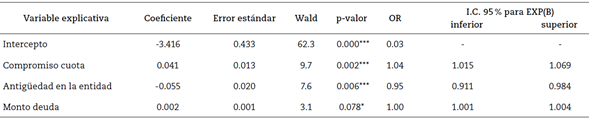
Significancia al *0.1; **0.05; ***0.01.
Fuente: elaboración propia con datos de la entidad.
De lo anterior, se puede pensar en dos posibles perfiles de asociados en cuanto al riesgo de incumplimiento para la entidad: por un lado, son más propensos al riesgo aquellos que presenten mayores compromisos en cuota, indicando que tendrían comprometido una mayor parte de sus ingresos. En cuanto al tiempo de antigüedad en la entidad, cabe notar que esta variable está directamente relacionada con la edad de los asociados y, por ende, se podría pensar en personas que son mucho más jóvenes que no presentan ingresos muy altos; y finalmente, el monto de la deuda, que entre más grande sea, es sinónimo de un mayor nivel de endeudamiento. Siendo coherente con el sentido de los signos en los parámetros estimados y los resultados obtenidos en la parte descriptiva del estudio. Por otro lado, estarían los menos propensos, como aquellos que presenten un compromiso de cuota más bajo, lleven más tiempo en la entidad y el monto de la deuda sea menor.
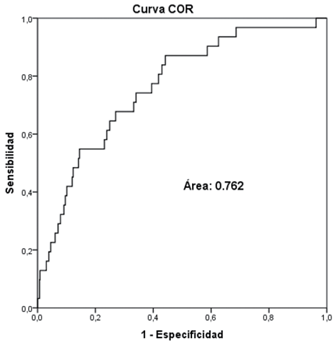
Una vez estimado el modelo, se valora su nivel de ajuste y capacidad predictiva. La figura 1presenta la curva característica de operación para el modelo ajustado, presentando un área de 76.2 %, lo que permite considerar que el modelo estimado es adecuado en su capacidad de discriminación, ya que, según Hosmer et al. (2004), un modelo se considera preciso y tiene alta capacidad de discriminación cuando el área es al menos de 70 %. En cuando a la bondad de ajuste del modelo, la figura 2 presenta las sensibilidades y especificidades obtenidas para diferentes puntos de corte entre 0.05 y 0.9, tanto para el 80 % de los datos con que se construyó el modelo, como para el 20 % que se dejó para la validación. Para ambos casos se obtiene que las curvas convergen al mismo punto de corte del 0.05, donde se maximiza la sensibilidad y especificidad del modelo.
La figura 3 presenta las sensibilidades y especificidades para cada uno de los 100 modelos estimados, tanto para los datos con que se construyó el modelo, como para el 20 % que se dejó para la validación, observando un comportamiento consistente con el obtenido en el modelo estimado para la entidad en el que la máxima sensibilidad y especificidad del modelo se obtiene para un punto de corte del 0.05. Este punto de corte indica el punto a partir del cual debe clasificarse a un asociado como posible default para la entidad.
De lo anterior se obtiene que para la población de asociados a la entidad el score de clasificación entre cumplido e incumplido es del 5 %. Sin embargo, tomando como referencia que en la mayoría de las entidades financieras el score de clasificación está entre 50 % y 65 %, se sugiere que la utilización del modelo esté alineada como un generador de alarmas, en cuyos casos de asociados identificados como posibles default sean objeto de un estudio más detallado, complementario al proceso de otorgamiento de créditos que realiza la entidad.
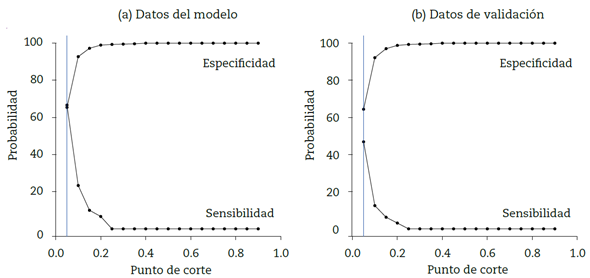
Fuente: elaboración propia con datos de la entidad.
Figura 2 Sensibilidad y especificidad: modelo estimado
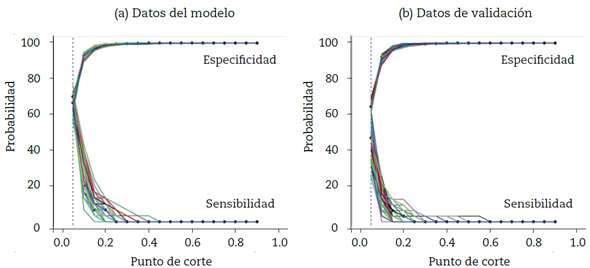
Fuente: elaboración propia con datos de la entidad.
Figura 3 Sensibilidad y especificidad: remuestreo (100 modelos).
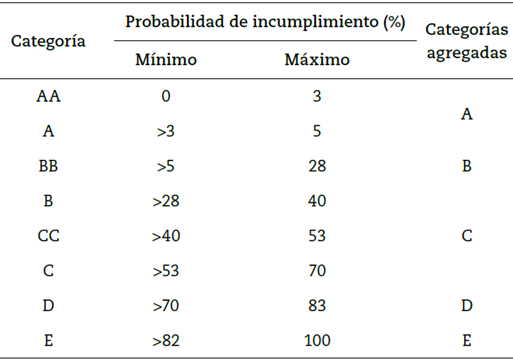
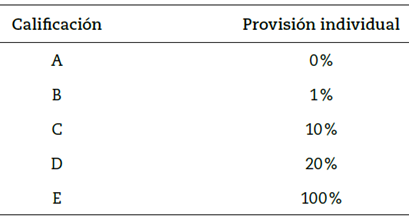
Una vez estimado y validado el modelo, para efectos de los registros en los estados financieros y reportes a las centrales de información, las entidades deben homologar las calificaciones de incumplimiento de sus modelos internos. Por tanto, el modelo construido, además de discriminar entre cumplidos e incumplidos, asigna una calificación a los clientes necesaria para determinar las provisiones de cartera. Con este propósito y siguiendo las buenas prácticas enunciadas por la SFC, se basó en la regla de calificación expuesta en el modelo de referencia de consumo, encontrando así los puntos de corte y escalas de calificación, como se muestra en la tabla 5. Una vez recalificados los asociados de acuerdo con su probabilidad de incumplimiento, la entidad deberá mantener una provisión individual mínima en los porcentajes que se relacionan en la tabla 6.
Finalmente, tomando como base la cartera de un mes específico, se tiene un saldo expuesto de $ 10 868 203 851, de los cuales se estima una pérdida esperada de $ 974 455 726, calculada a partir de la ecuación (1)definida en la primera etapa de la metodología, donde la PI es estimada por el modelo construido y la PDI es estimada a partir del referente definido en la tabla 1 dependiendo el tipo de garantía. De la pérdida esperada, se estima la provisión general e individual para la entidad solidaria, siendo de $ 108 millones y $ 418 millones, respectivamente, como se muestra en la tabla 7. Sin embargo, “la decisión de constituir una provisión general superior al mínimo exigido corresponderá a una política adoptada por el consejo de administración, junta directiva o quien haga sus veces” (Circular Básica Contable y Financiera 004 de 2008).

Conclusiones
Usando la información propia de la entidad, en condiciones de bajo default, se logra construir en este trabajo un modelo para determinar el riesgo de crédito y para limitar y tener conocimiento sobre el nivel de riesgo que puede afectar el capital de la entidad, logrando una adecuada cobertura acorde con la realidad de su portafolio.
Los resultados obtenidos permiten valorar el uso de la regresión logística, ya que por ser una herramienta flexible logra modelar de modo sencillo y elegante la probabilidad de incumplimiento de los asociados. El modelo admite el uso de covariables de cualquier naturaleza, sean categóricas, discretas o continuas y limita los supuestos a la independencia de variables aleatorias independientes provenientes de una única distribución de la familia exponencial. Estos elementos teóricos, unidos a su riqueza interpretativa, hacen de esta herramienta un instrumento versátil para perfilar a los asociados y, a partir de allí, proponer la implementación de modelos acordes con el entorno en que se desenvuelve el sector solidario.
Otro elemento destacable a partir de los resultados obtenidos es la necesidad de seguir utilizando métodos clásicos, como el de regresión logística para la evaluación de riesgo de crédito; ya que en algunos casos, como el de la entidad utilizada en el artículo, el tamaño de la base de usuarios de los productos crediticios y sus hábitos de pago dificultan la utilización de métodos basados en el manejo de grandes cantidades de datos. De hecho, los bajos niveles de morosidad que presenta la entidad analizada, obligaron a una redefinición de los umbrales de impago, para el modelo de riesgo, considerando como clientes riesgosos aquellos que han obtenido en el algún momento de su vida crediticia calificación B. Esto presenta una diferencia sustancial con los modelos de riesgo crediticio que normalmente se usan en el sector financiero tradicional.

