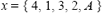
SPACE DISTRIBUTION IN INDUSTRIAL PLANTS USING TABU SEARCH METHOD
CARLOS ANDRÉS DOMÍNGUEZ GUAL
Escuela de la Organización, Facultad de Minas, Universidad Nacional de Colombia
GEOVANNI DE LOS RÍOS SALDARRIAGA
Escuela de la Organización, Facultad de Minas, Universidad Nacional de Colombia
JUAN DAVID VELÁSQUEZ HENAO
Escuela de Sistemas, Facultad de Minas, Universidad Nacional de Colombia
Recibido para revisión 6 de Abril de 2004, aceptado 29 de Julio de 2004, versión final recibida 10 de Noviembre de 2004
RESUMEN: En el problema de la distribución de espacios en plantas industriales se pretende ubicar de forma óptima los departamentos de acuerdo con sus necesidades. Este es un problema complejo de optimización combinatoria debido al gran número de distribuciones posibles, y para cuya solución han sido propuestos varios algoritmos heurísticos; no obstante, dichas técnicas de solución exploran parcialmente y de forma limitada el espacio de posibles combinaciones. Como una alternativa de solución a este problema, se presente una adaptación del método de Búsqueda Tabú, la cual realiza una exploración heurística de mayor amplitud que los métodos tradicionales. Los resultados obtenidos para los casos de aplicación presentados, indican que la metodología propuesta puede encontrar distribuciones de calidad superior, o al menos igual, a los métodos tradicionales.
]]> PALABRAS CLAVE: Algoritmos Heurísticos, Búsqueda Tabú.ABSTRACT: In the problem of space distribution in industrial plants the aim is to locate optimally the departments according to its necessities. This is a combinatory optimization complex problem due to great number of possible distributions, and for whose solution has been proposed several heuristic algorithms; notwithstanding, these solution techniques explore partially and in a limit way the space of possible combinations. As a alternative solution, an adaptation of Tabu search method is presented, which made a heuristic exploration of major extend that the traditional methods. The obtained results indicate the proposed methodology can find distributions of better quality, or at least equal, than the traditional methods.
KEYWORDS: Heuristic Algorithms, Tabu Search.
1. INTRODUCCIÓNEl problema de distribución de los espacios en plantas industriales (DEPI) ha sido comúnmente resuelto mediante técnicas heurísticas que hacen la distribución de acuerdo con algún criterio empírico previamente definido, realizando una búsqueda restringida sobre las posibles configuraciones realizables. Estas regiones de búsqueda en el espacio de posibles combinaciones son definidas de acuerdo con los criterios heurísticos utilizados, obteniéndose como resultado, soluciones factibles que no son necesariamente las óptimas.
No obstante, la distribución óptima de espacios puede ser interpretado como un problema de optimización combinatoria, cuyo espacio de soluciones está conformado por todas las distribuciones factibles que puedan realizarse; en consecuencia, su solución puede ser realizada mediante algoritmos heurísticos de búsqueda diseñados para la solución de problemas combinatorios.
El objetivo de este trabajo es explorar la aplicabilidad de la Búsqueda Tabú (Glover y Laguna, 1993), en la solución del problema de distribución de espacios en plantas industriales (DEPI), y proponer una adaptación de dicha metodología para la solución del problema en cuestión. Para ello, en la sección 2 se clasifican algunas de las metodologías convencionales comúnmente utilizadas, y posteriormente en la sección 3, se analizan algunas de sus limitantes. En la sección 4 se presenta la metodología propuesta, para exponer posteriormente en la sección 5 un ejemplo real de aplicación. Finalmente, las principales conclusiones son presentadas en la sección 6.
2. CLASIFICACIÓN DE LAS METODOLOGÍAS CONVENCIONALESLas metodologías convencionales utilizadas para la DEPI pueden clasificarse en diferentes formas:
3. DESVENTAJAS DE LAS METODOLOGÍAS CONVENCIONALES
Entre las principales desventajas encontradas en estos métodos es que la exploración está limitada a subregiones del espacio de soluciones conformado por todas las posibles combinaciones en que pueden repartirse los departamentos, las cuales no garantizan contener la distribución óptima que minimiza el criterio de selección usado.
Dichas técnicas convencionales están basadas en criterios heurísticos disímiles para la distribución de espacios, lo que genera para un mismo problema diferentes distribuciones finales.
Los algoritmos de mejoramiento usan una distribución inicial de arranque dada por el usuario, la cual debe ser obtenida por otro método. Como una consecuencia, se pueden alcanzar soluciones diferentes dependiendo del punto inicial de arranque. Dichos algoritmos de mejoramiento, basan su búsqueda en el intercambio entre departamentos que tienen un área igual o comparten un borde.
Finalmente, las metodologías analizadas no exploran todas las posibilidades para realizar la distribución de los departamentos, lo que conlleva a que para un mismo problema, cada método entregue una solución diferente.
4. METODOLOGÍA PROPUESTAComo ya se indicó, la DEPI es un problema de optimización combinatoria, por lo que los algoritmos comúnmente usados para la solución de este tipo genérico de problemas pueden ser potencialmente usados para hallar las distribuciones óptimas de los espacios. Diversos autores ya han explorado el uso de Algoritmos Genéticos en la solución del problema DEPI (Islier, 1998; Tam y Chan, 1998) encontrándose que estas técnicas permiten hallar soluciones superiores a las obtenidas usando técnicas convencionales. Sin embargo, estas técnicas de optimización son voraces en cuento a los recursos computacionales y al tiempo requerido para encontrar soluciones óptimas, debido principalmente, a la forma en que está concebido el algoritmo.
Se propone entonces, una nueva aproximación metodológica basada en la técnica de Búsqueda Tabú (BT) desarrollada por Glover y Laguna (1993), la cual realiza una exploración heurística inteligente del espacio de soluciones, y que requiere menores recursos computacionales que los Algoritmos Genéticos para su aplicación, permitiendo obtener resultados superiores a las técnicas convencionales.
4.1 BÚSQUEDA TABÚLa BT es un método heurístico de búsqueda global en el espacio de soluciones de un problema, en la cual una memoria de largo plazo registra las soluciones visitadas, y obliga a que el proceso de búsqueda visite de forma determinística soluciones no evaluadas; sin embargo, es posible hacer el proceso estocástico adicionando algunos elementos probabilísticos.
]]> En su forma tradicional, la BT opera sobre una cadena binaria que representa una posible solución del problema. El proceso de optimización consiste en explorar las vecindades de la mejor solución encontrada hasta el momento, moviéndose a una nueva solución óptima, en la medida en que ella tenga un mejor valor de la función objetivo.Para evadir los óptimos locales, la BT evita visitar algunas de las soluciones vecinas a la solución óptima actual, considerando que los movimientos en el espacio de soluciones que llevan de una solución a la otra son tabú, de tal forma que ellos no pueden ser aceptados durante un cierto tiempo o un cierto número de iteraciones. Para ello, los movimientos aceptados son almacenados en una memoria de corto plazo.
Cuando el algoritmo converge finalmente a un punto de óptima local, para el cual no es posible encontrar soluciones vecinas mejores, la solución es almacenada como el mejor óptimo encontrado; posteriormente, la memoria de corto plazo es borrada, y se escoge como nuevo punto de arranque del algoritmo, alguna de las soluciones previamente visitadas que se encuentran almacenadas en la memoria de largo plazo. Para mayores detalles sobre el algoritmo véase a Glover y Laguna (1993).
4.2 BÚSQUEDA TABÚ MODIFICADALa metodología de BT no puede ser directamente aplicada al problema de DEPI, por lo que debe ser modificada teniendo en cuenta las condiciones particulares de este problema.
4.2.1 Representación de la soluciónEn primer lugar es necesario definir la representación de la solución en una forma tal que pueda ejecutarse el algoritmo de BT. En nuestra aproximación, la solución es representada como un vector con tantas posiciones como departamentos más uno sea necesario ubicar en la planta industrial. A diferencia de la BT tradicional, que usa un vector binario, cada posición del vector contiene un ordinal que representa el índice del departamento, e indica el orden en que ellos serán repartidos en el área; la última posición contiene las letras A o B, que representan la forma en que se realizará la distribución. De esta forma, un problema con 4 departamentos podría tener la siguiente solución:
En la actualidad, la versión implementada considera dos formas de repartir los departamentos: oscilatoria en forma horizontal que es representada por la letra A, y oscilatoria en forma vertical que es representada por la letra B, las cuales pueden apreciarse en las Figuras 1 y 2. Para realizar la repartición, es necesario dividir el área de la planta en una cuadrícula donde cada cuadro representa la unidad mínima de superficie que es usada en la ubicación de cada departamento; en consecuencia, es necesario ajustar el requerimiento de área de cada departamento a un número entero de unidades mínimas de superficie.
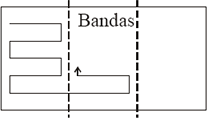
Figura 1. Repartición de departamentos oscilatoria vertical
Figure 1. Departments distribution vertical oscillating

Para realizar la ubicación de acuerdo con los valores del vector solución se procede de la siguiente forma: en la repartición oscilatoria vertical el área de la planta es dividida en bandas verticales; luego se toma el primer departamento, el 4 para el ejemplo presentado, y se empiezan a asignar unidades mínimas de área en el sentido indicado por la flecha en la Figura 1, hasta completar el número de unidades requerido por dicho departamento; posteriormente se procede a ubicar los departamentos restantes de igual forma. La repartición oscilatoria vertical es realizada de manera similar.
4.2.2 Evaluación de la función de costo
Para establecer la bondad de una solución, se evalúa una función de costo que relaciona la distancia entre los departamentos, el costo unitario de transporte y el flujo entre ellos.
4.2.3 Solución inicialNuestra propuesta de modificación de la BT para este problema funciona de la siguiente forma: cuando se inicia el algoritmo, se genera una distribución aleatoria de los departamentos en el vector de solución, y se evalúan las dos formas de repartición, calculándose para cada una de ellas su costo respectivo. La solución inicial corresponde a la repartición con mejor costo.
4.2.4 Generación de las soluciones vecinasA partir de este punto se entra en un proceso iterativo en el cual se van intercambiando departamentos en el vector de solución hasta que el algoritmo converge a un punto de óptima. Supóngase que la solución inicial, para un problema con 7 departamentos, está dada por:
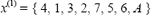
la cual tiene un costo inferior a la solución x =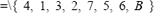 tal como ya se indicó. Para encontrar las soluciones en la vecindad de la solución optima actual, el departamento en la primera posición del vector intercambia su posición con cada uno de los departamentos restantes. Es así como la primera solución vecina se obtiene intercambiando el departamento 4 en la primera posición con el departamento 5; posteriormente el 4 con el 6 y así sucesivamente. Para cada una de las soluciones vecinas al punto actual, se evaluarán cada una de las formas de repartición consideradas; es así como para el ejemplo presentado, se evalúan las siguientes formas de repartición; la solución marcada con asterisco corresponde a la solución vecina con menor costo:
tal como ya se indicó. Para encontrar las soluciones en la vecindad de la solución optima actual, el departamento en la primera posición del vector intercambia su posición con cada uno de los departamentos restantes. Es así como la primera solución vecina se obtiene intercambiando el departamento 4 en la primera posición con el departamento 5; posteriormente el 4 con el 6 y así sucesivamente. Para cada una de las soluciones vecinas al punto actual, se evaluarán cada una de las formas de repartición consideradas; es así como para el ejemplo presentado, se evalúan las siguientes formas de repartición; la solución marcada con asterisco corresponde a la solución vecina con menor costo:
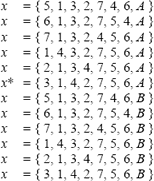
Sí x* tiene un costo inferior a x(1), ella será aceptada como la nueva mejor solución encontrada x(2) = x*.
4.2.5 Memoria de Corto PlazoPara implementar la memoria de corto plazo se usa un vector de enteros con tantas posiciones como departamentos hay en el problema, donde el entero en cada posición indica el número de iteraciones que dicha posición será tabú y con la cual no es posible realizar intercambios de departamentos. Ya que en el ejemplo presentado se encontró una solución mejor, la primera posición quedará bloqueada, y su valor no podrá cambiar durante las próximas n iteraciones; de esta forma, y si el bloqueo es por las próximas 3 iteraciones, la memoria de corto plazo será:
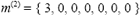
Nótese que cuando se inicia el algoritmo, m(1)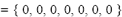 , por lo que se evalúan todos los intercambios de departamentos. En esta la implementación, este valor n es igual al número de departamentos sobre dos.
, por lo que se evalúan todos los intercambios de departamentos. En esta la implementación, este valor n es igual al número de departamentos sobre dos.
La memoria de largo plazo se implementa como una matriz de enteros donde cada fila corresponde a una de las soluciones visitadas. Cuando se inicia el algoritmo la matriz está vacía. Cada vez que se evalúa una solución no visitada, ella es introducida en la matriz, tal que al final del primer ciclo, la memoria de corto plazo contiene a x(1) y todas sus soluciones vecinas. En el siguiente ciclo, se tomará como solución inicial a:
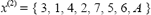
Ya que la primera posición del vector se encuentra bloqueada en la memoria de corto plazo, se procede a realizar el intercambio de departamentos entre la segunda y el resto, tal que se evalúan las siguientes combinaciones:

Nótese que no hubo intercambios con el departamento 3. Ahora, cada vez que se genera una solución vecina, se verifica que ella no se encuentre en la memoria de largo plazo para ser considerada. En el caso de que ya hubiera sido visitada, es descartada del conjunto de soluciones vecinas. Ya que se encontró la solución vecina x* con un costo menor a x(2), se disminuye en 1 todas aquellas posiciones de la memoria de corto plazo diferentes de cero, y se asigna 3 a la posición 2. De esta forma, la memoria de corto plazo se transforma a:
]]>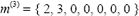
A la memoria de largo plazo se ha adicionado la solución x(2) y todas sus vecinas.
Este proceso continua hasta que después de visitar todas las posiciones del vector no bloqueadas que pueden cambiarse, no se obtiene una solución vecina mejor al punto actual. En este momento se hacen todas las posiciones de la memoria de corto plazo iguales a cero y se toma como nuevo punto inicial, una solución almacenada en la memoria de largo plazo seleccionada de forma aleatoria.
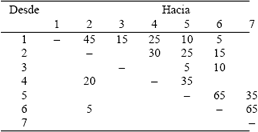
5.APLICACIÓN A UN CASO REALEl método propuesto fue aplicado a la distribución de siete departamentos en una planta. Los departamentos tienen las áreas presentadas en la Tabla 1. Los flujos entre departamentos son presentados en la Tabla 2.
Tabla 1. Área de los Departamentos
Table 1. Departments area

Tabla 2. Flujo de productos entre departamentos por unidad de tiempo
Table 2. Product flow between departments by time unit
Este mismo problema fue solucionado usando los programas CRAFT y ALDEP, encontrándose que la configuración obtenida usando la metodología propuesta, tiene un costo inferior a las soluciones encontradas con estos dos programas. Los resultados se resumen en la Tabla 3, y las distribuciones encontradas se presentan en las Figuras 3 a 5; en cada una de dichas Figuras, cada dígito indica una unidad mínima de área. El cero representa unidades de área que no han sido asignadas a ningún departamento. Los dígitos entre 1 y 7 indican a que departamento a sido asignada cada unidad mínima de área. De esta forma, en la Figura 4, el departamento 1 ocupa una región de 10 unidades horizontales por 3 unidades verticales, ubicada en la esquina superior izquierda de la planta.
Tabla 3. Costos obtenidos para las distintas configuraciones encontradas
Table 3. Costs for different found configurations
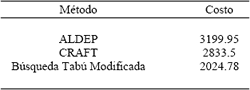

Figura 3. Solución encontrada usando el programa ALDEP
Figure 3. Found solution using program ALDEP

Figura 4. Solución encontrada usando el programa CRAFT ]]>

Figura 5. Solución encontrada usando el programa Propuesto
Figure 5. Found solution using proposed program
6. CONCLUSIONES
La metodología propuesta permite explorar de una forma más completa el espacio de solución. Debido a la forma en como está expresada la función de costo a optimizar, es posible hacerla tan compleja como sea necesario, pudiendo incorporarse elementos de análisis multiobjetivo si fuese necesario.
En su forma conceptual y de implementación, la BT modificada propuesta, es conceptualmente mucho más simple que otras técnicas que pueden producir resultados comparables tales como Algoritmos Genéticos. Igualmente la metodología propuesta, puede obtener soluciones en menor tiempo, ya que realiza comparativamente un número inferior de cálculos, si se la compara con Algoritmos Genéticos.
La metodología propuesta combina elementos de los programas normalmente utilizados, explorando un espacio solución mucho más amplio que el de ellos, lo que posibilita encontrar mejores soluciones.
Para el caso de aplicación, se encontró que la solución obtenida por nuestra aproximación metodológica equivale al 63% del costo encontrado con ALDEP y del 71% del encontrado con CRAFT. Estos resultados muestran que la nueva metodología puede permitir encontrar valores inferiores respecto a las metodologías tradicionales.
REFERENCIAS [ Links ]
[2] Islier, A. A. (1998), A genetic algorithm approach for multiple criteria facility layout design, Int. J. Prod. Res. 36(12), 15491569. [ Links ]
[3] Tam, K. Y. y Chan, S. K. (1998), Solving facility layout problems with geometric constrains using parallel genetic algorithms: experimentation and findings, Int. J. Prod. Res. 36(12), 32533272. [ Links ]
[4] Tompkins, J. y Moore, J. (1978), Computer Aided Layout: Users Guide. FP & D Monograph Series No 1. AIIE-FP & D - 77 - 1.