MODEL PARAMETERS TUNING USING GA, ON LIP
POSTURES RECOGNITION
JORGE A. JARAMILLO
Universidad Nacional de Colombia, Manizales, Grupo Control y Procesamiento Digital de Señales, jajaramillog@gmail.com
JUAN R. GONZÁLEZ
Universidad Nacional de Colombia, Manizales, Grupo Control y Procesamiento Digital de Señales, emarshall311@hotmail.com
GERMÁN CASTELLANOS ]]>
Universidad Nacional de Colombia, Manizales, Grupo Control y Procesamiento Digital de Señales, gcastell@telesat.com.coRecibido para revisar 15 de Diciembre de 2005, aceptado 6 de Abril de 2006, versión final 23 de Junio de 2006
RESUMEN: Se presenta un sistema de segmentación y reconocimiento de posturas labiales en imágenes por medio de la sintonización de modelos con parámetros ajustables: Para la segmentación se usa una plantilla deformable y para la caracterización se usa un modelo de variación de los contornos labiales. Ambos modelos son sintonizados por medio de algoritmos genéticos del tipo canónico, alcanzando desempeños de hasta el 86.5% y 76.6% respectivamente.
PALABRAS CLAVE: Algoritmos genéticos, Segmentación de imágenes, Caracterización, Clasificación de patrones, Análisis de componentes principales, Descomposición en valores singulares.
ABSTRACT: Here, a lip posture recognition and segmentation system by means of tuning adjustable parameter models, is shown. For segmentation, deformable templates are used, and for feature extraction a variational model of lip contours is implemented. Both models are tuned by canonical genetic algorithms yielding performances up to 86.5% and 76.6% respectively.
KEYWORDS: Genetic Algorithms, Image segmentation, Feature extraction, Pattern classification, Principal component analysis, Singular values descomposition.
1. INTRODUCCIÓN
En los últimos años se ha propuesto el empleo del reconocimiento de posturas labiales (speechreading) usando técnicas de procesamiento digital de imágenes, como complemento al análisis acústico para el reconocimiento de patologías asociadas a problemas o alteraciones de la emisión de voz [1]. La aplicación más difundida consiste en la creación de un modelo de los labios, cuyos parámetros sean ajustables para obtener versatilidad en las formas a reconocer. Sin embargo, una vez construido el modelo, la
sintonización de estos parámetros ha sido sometida a diversas restricciones prácticas. Por ejemplo, en [2] se utiliza el método de plantillas deformables descrito en [3]. El contorno de los labios es modelado por un conjunto de polinomios codificados que se ajustan al gradiente de la imagen considerada. La búsqueda en la imagen es llevada a cabo bajo la suposición de que se tienen bordes gruesos en los contornos de los labios. Esta suposición es violada en muchos casos reales, y además, la dependencia sobre la elección inicial de los polinomios no permite modelar contornos con detalles finos. En [4], se presenta una aplicación usando splines [5] y filtros de Kalman en la que se impusieron restricciones de deformación a la plantilla limitando el número de grados de libertad. En [6] se describió un método basado en snakes [7], las cuales tienen la habilidad de resolver detalles finos en los contornos. Sin embargo, los contornos fueron restringidos a un subespacio aprendido del conjunto de entrenamiento.
Los algoritmos genéticos (GA) han sido empleados en la optimización de tareas con espacios de búsqueda muy amplios (en particular, en el procesamiento de imágenes), gracias a su capacidad de búsqueda en paralelo. Por ejemplo, en [8] se utiliza un modelo con seis parámetros variables, para detectar el ventrículo izquierdo en imágenes de ultrasonido del corazón. Un algoritmo genético lleva a cabo la búsqueda a través de la variación de los seis parámetros y evalúa qué tan bien se acopla el modelo a la imagen, mediante una función de evaluación que depende de la intensidad de gris de unos vectores perpendiculares y calculados sobre contorno modelado.
]]> En [9], se presenta una aplicación para reconocimiento de rostros, el algoritmo genético es utilizado para buscar dentro de todas las posibles subimágenes del cuadro original en la que se quiere detectar un objeto determinado. Por esta razón, los parámetros a codificar corresponden a las posiciones de la esquina superior izquierda e inferior derecha del rectángulo que definirá la subimagen. En la fase de entrenamiento, un conjunto de imágenes previamente segmentadas y escaladas, conteniendo exclusivamente rostros, son entregadas al algoritmo para extraer las características más expresivas (MEFs) y las características más discriminantes (MDFs) [10]. Luego, con base en una organización jerárquica de estas características, el algoritmo genético busca cuál subimagen es la que más probable contiene un rostro humano.Un método similar al anterior es el usado en [11] para la detección y verificación de rostros. En este caso, ya que el objetivo es la verificación, el entrenamiento se hace con varias imágenes del mismo sujeto y se pretende hallar la mayor concordancia de la subimágen con el modelo definido en el entrenamiento. En [12], en lugar de variar directamente los parámetros que dan la forma a la imagen modelo, se utilizan transformaciones afines [13] para reconocer objetos en dos dimensiones. El algoritmo genético genera contornos a través de estas transformaciones y calcula las distancias entre cada punto del contorno modelado y el punto más cercano a éste en la imagen original, para calcular el error cuadrático medio y optimizar la ubicación de los contornos.
Teniendo en cuenta estos antecedentes, en este trabajo se plantea un método de segmentación y reconocimiento de posturas labiales mediante el uso de una plantilla deformable y un modelo de variación de los labios, los cuales son sintonizados por un algoritmo genético de dos etapas, específicamente, del tipo canónico. Este método de sintonización de los modelos, podría superar los problemas de implementación de las aplicaciones de speechreading, surgidos por el espacio de búsqueda resultante.
2. MODELOS Y SINTONIZACIÓN
2.1 Etapa de segmentación
Una plantilla deformable es un modelo matemático que se utiliza para rastrear los movimientos que un objeto específico [14]. Típicamente la plantilla se encuentra descrita por uno o varios polinomios que definen la intensidad de los píxeles en ésta.
Construcción de la plantilla deformable. Inicialmente, es necesario realizar la segmentación manual del conjunto de imágenes de entrenamiento (este caso se usaron ) para cada vocal. Se construye una superficie promedio como primera aproximación a la plantilla deformable, mediante el submuestreo posterior normalización del tamaño de todas las imágenes ( píxels). Luego se superponen las intensidades en las componentes R, G y B en la forma:
![]()
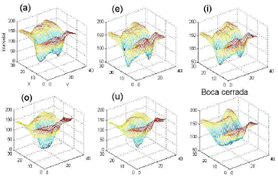
donde es la imagen promedio, es el número de imágenes de entrenamiento, y es el promedio de intensidad de la imagen. En la Figura 1 se observa un ejemplo de las superficies promedio de las imágenes de posturas labiales para todas vocales, además de la boca cerrada.
]]> Figura 1. Superficies promedio de las posturas labiales.Seguidamente se realiza la aproximación de cada superficie promedio mediante el respectivo polinomio, que permita la deformación realizando la variación de sus coeficientes, y la cual corresponde a la solución de la ecuación normal [15]:
![]()
La solución exacta, si es una matriz cuadrada de rango completo, está definida como
![]()
Cuando no es cuadrada o no se cuenta con una solución exacta, se tiene la solución dada por:
![]()
Para evitar el cálculo de se utiliza la aproximación por descomposición en valores singulares:
![]()
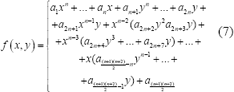
entonces, la notación de en forma matricial será:
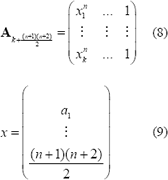
De (8), se obtiene la ecuación de la forma , donde son los valores de intensidad de la imagen a ajustar. Los resultados concretos obtenidos para ajustar cada imagen promedio a una función de orden se representan en la Fig. 2.
Figura 2. Imagen promedio y plantilla construida
Figure 2. Average image and constructed template.
Finalmente, los puntos evaluados e corresponden a los índices de los píxels de la imagen promedio. Por tanto, la plantilla puede ser deformada calculando la función en intervalos menores a , si se quiere aumentar el número de píxels en una dirección, y mayores a si se requiere disminuirlos. En la Figura 3 se muestra como se deforma la plantilla en la dirección o escala y en o escala .
]]> Figura 3. Ejemplos de deformación de la plantillaAlgoritmo de Segmentación. Para realizar la segmentación como tal, se construyó una función de error que consta de cuatro variables independientes correspondientes a la posición ( , ) del punto central de la plantilla y las escalas ( ) correspondientes a la dimensión de la plantilla en las direcciones e respectivamente:
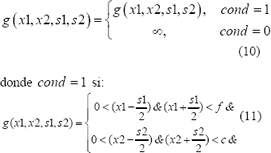
Siendo y las filas y las columnas de la imagen a segmentar. En caso contrario, . A fin de reducir el espacio de búsqueda, de acuerdo a la observación de la base de datos para las imágenes de , se tuvo en cuenta las siguientes consideraciones, siguiendo la cuales se agregaron condiciones al cálculo de la función de error, de forma que la nueva condición para el cálculo de la función de error es:
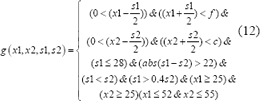
La función está definida como:
![]()
Siendo la imagen original que está siendo comparada con la plantilla deformada .
]]> La ecuación 13 depende de cuatro parámetros, dos de posición y dos de escalamiento, los que serán codificados y servirán como entrada al algoritmo genético que se describe en la sección 2.3, con el que se buscará minimizar esta ecuación, ya que cuando 13 sea mínimo, se sospecha de la existencia de un segmento correspondiente a la postura labial. La codificación se realiza transformando los parámetros en decimales a cadenas binarias independientes de bits, esto por la reducción del espacio de búsqueda hecha en el algoritmo de segmentación.2.2 Etapa de reconocimiento
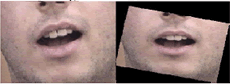
Construcción del modelo de variación de los contornos labiales Sobre las imágenes segmentadas en la etapa anterior, se realiza una normalización automática para eliminar los efectos de rotación, traslación y escala, es decir, se busca que las bocas quedaran horizontales, centradas y con una longitud estándar de comisura a comisura, como se muestra en la Figura 4.
Figura 4. Imagen original (izquierda) y la imagen preprocesada (derecha)
Figure 4. Original image (left side) and preprocesed image (right side ).
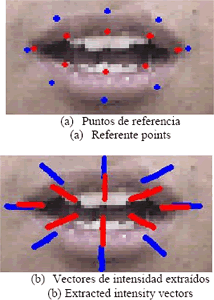
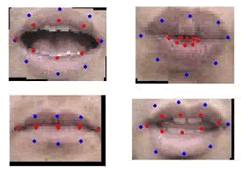
El sistema de caracterización que se implementó es propuesto en [16] y [17], el cual se basa en la construcción de modelos que tengan las principales formas de variación de la boca, tanto en forma como en la intensidad de la imagen en las cercanías de los contornos labiales. La construcción de estos modelos constituye la fase de entrenamiento del sistema de caracterización. Para construir el modelo de forma de la boca, a cada una de las fotos de entrenamiento del sistema le fueron señalados manualmente puntos, que describen los contornos exterior e interior de los labios, como se muestra en la Figura 4.
Estos puntos son la referencia para la extracción de los vectores de intensidad alrededor de los contornos labiales. Dichos vectores son radiales al centro de la imagen y de una longitud de pixels, siendo el pixel número uno de los puntos previamente señalados, como se muestra en la Figura 4. Los vectores son extraídos de la matriz de tono de la imagen, que corresponde a la primera matriz del sistema HSV, por lo que la imagen se lleva antes a este espacio de color, en lugar del RGB.
Figura 5. Modelo de forma de la boca ]]>
Figure 5. Mouth shape modelEl objetivo de construir modelos de variación de los contornos labiales, es restringir el uso de suposiciones heurísticas acerca de las formas legales de variación de la boca, a la hora de realizar la búsqueda en una imagen [17].
En este caso, para obtener una forma promedio, se señalaron los contornos de un conjunto de entrenamiento representativo, conformado por imágenes de la postura labial correspondiente a cada una de las vocales: /a/,/e/,/i/,/o/,/u/ y boca cerrada.
La i-ésima forma del conjunto de entrenamiento (i=1...N ) es representada por el vector , de la forma:
![]()
donde {xij,yij}son las coordenadas del j-ésimo punto (ji=1...32 ) correspondiente a la i-ésima forma.
Teniendo las formas de entrenamiento, se calcula la forma promedio y la matriz de covarianza .
En calidad de características representativas del modelo se obtienen los vectores propios y valores propios de la matriz de covarianza usando análisis de componentes principales (PCA) [18]:
![]()
donde es una matriz con los vectores propios correspondientes a los valores propios más altos y es un vector con los coeficientes correspondientes a cada eigenvector. La variación de estos coeficientes será la que dé el espacio de búsqueda para el algoritmo genético. Las Figuras 15 y 15 muestran las formas producidas por la variación de los dos primeros coeficientes, desde desviaciones estándar hasta desviaciones estándar, respectivamente.
]]>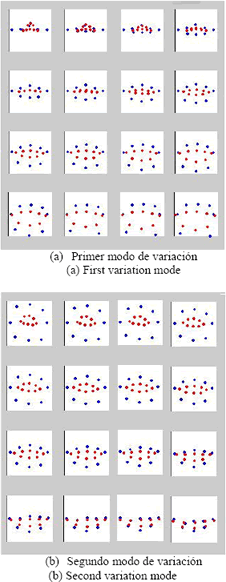
Figura 6. Modos de variación del modelo de forma
Figure 6. Variation modes of the shape model
El modelo completo contiene 6 modos de variación que generan diversos detalles y asimetrías de las formas de variación del conjunto de entrenamiento y serán utilizados como características para la clasificación.
La búsqueda en cada imagen realiza mediante el modelo de las variaciones de intensidad alrededor de los contornos labiales, para lo cual se extraen los vectores de intensidad representados en la Figura 4, siendo el j-ésimo vector de la i-ésima imagen de entrenamiento, con los cuales se conforma la matriz respectiva:
![]()
Luego se calcula nuevamente la media y la matriz de covarianza para representar las formas de variación de intensidad por:
![]()
siendo la matriz con los primeros vectores propios de , de forma que se tenga el de varianza acumulada y es el vector de los coeficientes correspondientes a cada vector propio.
2.2.1 Algoritmo de reconocimiento de posturas
]]> El algoritmo genético implementado es el encargado de localizar los contornos labiales dentro de la imagen. Los cromosomas representarán al vector de coeficientes para formar diferentes posturas labiales utilizando la ecuación (15), en la cual cada uno de los coeficientes puede tomar uno de valores discretos, desde desviaciones estándar hasta desviaciones estándar con incrementos de , de tal manera que cada uno se representa con bits. El cromosoma total, tendrá entonces bits (Ver Figura 7 ), lo que genera un espacio de búsqueda de más de dieciséis millones de posibles posturas. La solución de esta tarea de búsqueda sobre espacios tan amplios, genera la necesidad de emplear los algoritmos genéticos.Figura 7. Codificación del vector en un cromosoma
Figure 7. b vector encodig onto a chromosome
El algoritmo genético va extrayendo los vectores de intensidad de la matriz de rojo de la imagen. Dado que los vectores propios de la ecuación (17) son ortogonales, el vector de parámetros puede ser calculado como:
![]()
Teniendo este valor, se puede calcular el error entre la descripción de intensidad de la imagen y la descripción del modelo alineado, de la siguiente forma:
![]()
El algoritmo genético busca minimizar este error, por lo tanto la función de evaluación será inversamente proporcional:
![]()
Para la clasificación se tomaron los 6 coeficientes del vector en (15), que son descriptores de la forma del modelo, y los coeficientes del vector calculado en (18).
Sobre este conjunto de 38 características, se aplicó la metodología de selección efectiva de características por medio de PCA, KPCA y MANOVA descrita en [19].
La validación del clasificador se llevó a cabo utilizando validación cruzada. Para este caso, se usó tres subconjutos de validación =3, o sea, que se dividió la base de datos en grupos de 84 imágenes (28 de cada clase) y se validó 3 veces. El valor de fue escogido de tal manera que los grupos de validación representaran el de la cantidad total de imágenes, entrenando así con el cada vez.
2.3 El Algoritmo Genético
En el presente trabajo se emplea un algoritmo genético de estructura simple (algoritmo canónico), el cual se corre en dos etapas. Primero, se utiliza como población de entrada la codificación de los parámetros de la ecuación 13 para segmentar la imagen, como se describe en la sección 3. Cuando el algoritmo converge, inmediatamente comienza a correr de nuevo, utilizando esta vez la codificación descrita en la sección 2.2.1 para caracterizar la postura labial.
El algoritmo se implementó con los operadores indicados por [20] para un algoritmo genético canónico:
con los parámetros planteados en [21]:
Las condiciones de parada se establecieron experimentalmente, llegando a que el algoritmo debe detenerse bajo una de las siguientes condiciones:
La base de datos con que se probó el método de segmentación y reconocimiento de posturas labiales, consta de 252 imágenes de posturas labiales extraídas de una población de personas con edades en el rango de 17 a 25 años. Las imágenes se encuentran divididas en seis clases correspondientes a las 5 vocales del idioma español, además de la boca cerrada en relajación. Las muestras fueron tomadas con resolución de imágenes ,formato bmp de 24 bits sin compresión.
3.1 Segmentación
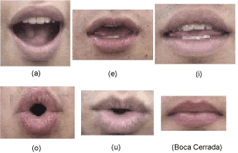
Los resultados concretos de segmentación de posturas labiales de las vocales /a/, /e/, /i/, /o/, /u/ y la boca cerrada se muestran en la Figura 8. Las muestras se clasificaron de la forma en que se muestra en la Tabla. 1, de acuerdo a la imagen que resulta después de aplicada la segmentación.
Figura 8. Imágenes segmentadas de todas las vocales y boca cerrada
Figure 8. Segmented images for all vowels and closed mouth
Tabla 1. Clasificación cualitativa del segmentador.
Table 1. Qualitative classification

Tabla 2. Resultados del segmentador propuesto
Table 2. Results of the proposed segmentation.
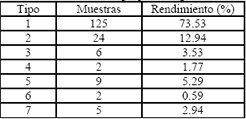
El método de segmentación propuesto mostró un rendimiento de , haciendo del segmentador por error minimizado mediante algoritmos genéticos un buen método, a pesar de la carga computacional que implica debido a su carácter iterativo, el cual converge en un rango de 50 a 100 generaciones con un tiempo de cálculo de por generación, haciendo que el tiempo máximo de procesamiento por imagen sea ( ), que es un tiempo considerablemente alto para un procesador pentium(R) 4 de 2.4 GHz y 512Mb de Ram.
3.2 Caracterización
La figura 9 muestra, algunos de los resultados del sistema de caracterización.
Figura 9. Resultados del sistema de caracterización
Figure 9. Feature extraction results.
Clasificación
Para la clasificación se tomaron los 6 coeficientes del vector en 15, que son descriptores de la forma del modelo, y los coeficientes del vector calculado en 18. En el experimento se obtuvo que para tener un de varianza acumulada, .
Sobre este conjunto de 38 características, se aplicó la metodología de selección efectiva de características por medio de PCA, KPCA y MANOVA descrita en [?]. Los resultados de esta clasificación se encuentran en la Tabla 3.
Tabla 3. Porcentaje de clasificación
Table 3. Classification rates.
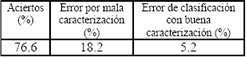
Para analizar las causas de error, se construyó la matriz de confusión de clases mostrada en la Tabla 4. Las filas representan la clase verdaderas y las columnas representan la clase reconocida.
Tabla 4. Matriz de confusión en la clasificación
Table 4. Confussion matriz
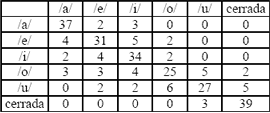
Puede observarse que la mayor confusión de clases se encuentra entre la /o/ y la /u/. Esto se debe a que en muchas ocasiones hay sombra alrededor del contorno interior de la boca, y esta sombra es interpretada por el sistema como parte de la apertura de la boca, caracterizándola más grande de lo que es en realidad. Otros casos en los que se presenta confusión es en las personas con dientes muy grandes, ya que el clasificador reconoce los dientes como un rasgo distintivo de la letra /i/; además se encuentra el caso de la pronunciación exagerada, que puede hacer que el clasificador identifique la apertura de la boca como característica de una /a/, cuando la vocal pronunciada es una /o/ o una /e/. El desempeño total del sistema se encuentra resumido en la tabla 5.
Tabla 5. Error total del sistema
Table 5. Total error of the system
![]()
Se observa que el porcentaje de error crece debido a que el sistema funciona serialmente, por lo tanto el error de la primera fase se acumula para la segunda.
4. CONCLUSIONES
Se ha descrito un método de segmentación de posturas labiales basado en un modelo de aproximación polinomial a la imagen promedio. Al combinar este modelo con el algoritmo genético simple, se obtuvo un sistema con un buen desempeño en la ubicación de posturas labiales, teniendo en cuenta que la plantilla de comparación contiene las características de iluminación de la base de datos y la aproximación polinomial(SVD) contiene las características de forma más generales, por lo cual el algoritmo no depende de condiciones de iluminación ni de detalles finos de las imágenes.
La utilización de algoritmos genéticos en la minimización de la función de error mostró ser una herramienta computacional de optimización que lleva a cabo la búsqueda de soluciones en paralelo, lo que los hace muy eficientes en espacios de búsqueda extensos, permitiendo obtener el mínimo de la función de error en un máximo de generaciones teniendo en cuanta que habían posibilidades.
Se ha descrito un método de caracterización y clasificación de posturas labiales basado en un modelo de las variaciones de forma de los contornos labiales. Al combinar este modelo con el algoritmo genético canónico [20], se obtuvo un sistema con un buen desempeño en la caracterización y reconocimiento de posturas labiales en imágenes.
]]> En la clasificación de posturas labiales, no es suficiente con utilizar características de forma, dado que hay posturas que son prácticamente iguales en cuanto a forma y sólo se diferencian por la posición de la lengua. Para solucionar éste inconveniente, es necesario añadir características de intensidad de la imagen.Debido a la naturaleza serial del proceso, el error se vuelve acumulativo, lo que genera un error total bastante alto. Sin embargo, teniendo en cuenta las 2 etapas por separado, presentan buenos desempeños en sus respectivas tareas.
REFERENCIAS
[1] G. Potamianos, C. Neti, G. Iyengar, and E. Helmuth, Large vocabulary audio-visual speech recognition by machines and human 2001. [ Links ]
[2] M. Hennecke, K. Prasad, and D. Stork, Using deformable templates to infer visual speech dynamics, 1994. [ Links ]
[3] A. L. Yuille, P. W. Hallinan, and D. S. Cohen, Feature extraction from faces using deformable templates, Int. J. Comput. Vision, vol. 8, no. 2, pp. 99111, 1992. [ Links ]
[4] R. Kaucic, B. Dalton, and A. Blake, Real-time lip tracking for audio-visual speech recognition applications, in ECCV (2), 1996, pp. 376387. [ Links ]
[5] R. H. Bartels, J. C. Beatty, K. S. Booth, E. G. Bosch, and P. Jolicoeur, Experimental comparison of splines using the shape-matching
paradigm, ACM Trans. Graph., vol. 12, no. 3, pp. 179208, 1993.
[6] C. Bregler and S. M. Omohundro, Surface learning with applications to lipreading, in Advances in Neural Information Processing Systems, J. D. Cowan, G. Tesauro, and J. Alspector, Eds., vol. 6. Morgan Kaufmann Publishers, Inc., 1994, pp. 4350. [ Links ]
[7] M. Kass, A. Witkin, and D. Tersopuolos, Snakes: Active contour models. International Journal of Computer Vision, vol. 1, no. 4, p.321331, 1988. [ Links ]
[8] A. Hill and C. J. Taylor, Model-based image interpretation using genetic algorithms, Image and Vision Computing, vol. 10, no. 5, pp. 295300, 1992. [ Links ]
[9] D. L. Swets, B. Punch, and J. Weng, Genetic algorithms for object recognition in a complex scene, in ICIP, 1995, pp. 25952598. [ Links ]
[10] Y. Cui, D. L. Swets, and J. J. Weng, Learning-based hand sign recognition using shoslif-m, in Proc. International conference on computer vision, 1995. [ Links ]
[11] G. Bebis, S. Uthiram, and M. Georgiopoulos, Face detection and verification using genetic search, International Journal on Artificial Intelligence Tools, vol. 9, no. 2, pp. 225 246, 2000. [ Links ]
[12] S. J. Louis, G. Bebis, S. Uthiram, and Y. Varol, Genetic search for object identification, in Evolutionary Programming VII, V. W. Porto, N. Saravanan, D. Waagen, and A. E. Eiben, Eds. Berlin: Springer, 1998, pp. 199208. [ Links ]
[13] G. Bebis, M. Georgiopoulos, N. DaVitoria Lobo, and M. Shah, Learning affine transformation of the plane for model-based object recognition, Proceedings of the 13th Intenational Conference on Pattern Recognition, pp. 6064, 1996. [ Links ]
[14] I. Matthews, T. Cootes, S. Cox, R. Harvey, and J. Bangham, Lipreading using shape, shading and scale, 1998. [ Links ]
[15] H. Gene and F. Charles, Matrix computations, in John Hopkins, 1997. [ Links ]
[16] J. Luettin and N. A. Thacker., Active shape models for visual speech feature extraction, Electronic Systems Group Report, University of Sheffield, 1995. [ Links ]
[17] J. Lüttin and N. A. Thacker, Speechreading using probabilistic methods, 1997. [ Links ]
[18] L. Smith, A tutorial on principal component analysis, 2002. [ Links ]
[19] G. Daza and L. G. Sánchez, Pca, kpca y manova sobre señales de voz en imágenes de posturas labiales y audio, Trabajo de grado. Universidad Nacional de Colombia, sede Manizales, 2004. [ Links ]
[20] D. Whitley, An overview of evolutionary algorithms: practical issues and common pitfalls, Information and Software Technology, vol. 43, no. 14, pp. 817831, 2001. [ Links ]
[21] M. Mitchell, An Introduction to Genetic Algorithms. Massachusetts Institute of Technology, 1996. [ Links ]
]]>