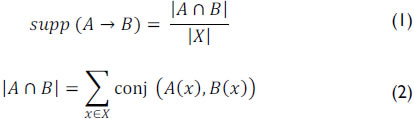
DOI: http://dx.doi.org/10.15446/ing.investig.v34n3.41638
T. Ceruto1, O. Lapeira2 and A. Rosete3
1Taymi Ceruto. Ingeniero Informático, Master en Ciencias, Instituto Superior Politécnico "José Antonio Echeverría", Cuba. Affiliation: Cujae, Cuba. E-mail: tceruto@ceis.cujae.edu.cu
2Orenia Lapeira. Ingeniero Informático, Instituto Superior Politécnico "José Antonio Echeverría", Cuba. Affiliation: Cujae, Cuba. E-mail: olapeira@ceis.cujae.edu.cu
3Alejandro Rosete Suárez. Ingeniero Informático, Doctor en Ciencias , Instituto Superior Politécnico "José Antonio Echeverría", Cuba. Affiliation: Cujae, Cuba. E-mail: rosete@ceis.cujae.edu.cu
ABSTRACT
Association rule mining is a very popular data mining technique. Rules in this technique are often used to identify and represent dependencies between attributes in databases. Specifically, fuzzy association rules are rules that use the concepts of fuzzy sets and can be considered as a special case of fuzzy predicates. Many quality measures have been defined for fuzzy association rules, but all consider a specific structure: antecedent and consequence. In the case of fuzzy predicates in the normal form (i.e., conjunctive or disjunctive), it is necessary to define different quality measures that do not consider the structure as an antecedent or a consequence. The only available measure for this scenario is the fuzzy predicate truth value (FPTV), which has serious limitations. The evaluation of fuzzy predicates in the normal form through appropriate quality measures has not yet been clearly defined in the literature. Thus, we propose several quality measures specifically for fuzzy predicates in the conjunctive (CNF) and disjunctive (DNF) normal forms. Experimental studies illustrate the use of the proposed measures and allow some general conclusions about each measure.
Keywords: data mining, fuzzy predicate, quality measures, conjunctive and disjunctive normal forms.
RESUMEN
La extracción de las reglas de asociación es una técnica de minería de datos muy popular, las cuales son utilizadas a menudo para identificar y representar dependencias entre atributos en bases de datos. Específicamente, las reglas de asociación difusas utilizan conceptos de conjuntos difusos y pueden ser vistas como un caso especial de predicados difusos. Muchas medidas de calidad han sido definidas para reglas de asociación difusa, pero todas consideran la estructura específica de reglas: antecedente y consecuente.
En el caso general de predicados difusos en forma normal (conjuntiva o disyuntiva), es necesario definir diferentes medidas de calidad que no estén en función de antecedente y consecuente, puesto que la única medida disponible para ello, es el valor de verdad para predicados difusos (FPTV) y tiene serias limitaciones. La evaluación de un predicado difuso en forma normal, a través de medidas adecuadas de calidad no ha sido todavía claramente definida por otros autores. Por esa razón, en este trabajo se proponen varias medidas de calidad para los predicados difusos, en formas normal conjuntiva o disyuntiva. Los experimentos demuestran el uso que se le puede dar a las métricas propuestas y permiten llegar a conclusiones generales de cada una de ellas.
Palabras clave: minería de datos, predicados difusos, medidas de calidad, forma normal conjuntiva y disyuntiva.
Received: January 20th 2014 Accepted: May 5th 2014
Introduction
]]> Knowledge discovery, whose objective is to obtain useful knowledge from data, is recognized as a basic necessity. The theory of fuzzy sets can certainly aid in the data-mining process to reach this goal. Fuzzy sets handle numerical values better than existing methods because fuzzy sets soften the effect of sharp boundaries (Zadeh, 1965; Fayyad, Piatetsky-Shapiro & Smyth, 1996; Duarte, 1999; Han & Kamber, 2006; Venugopal, Srinivasa & Patnaik, 2009).Many techniques used in datasets have their corresponding "fuzzy version." For instance, fuzzy association rules described by the natural language are well suited for human comprehension and help to increase the flexibility for supporting users in making decisions (Delgado, Marín, Sánchez & Vila, 2003). Fuzzy clustering generally provides a more suitable partition of a set of objects than does classical clustering (Han & Kamber, 2006).
The discovery of fuzzy predicates in conjunctive (CNF) and disjunctive normal form (DNF) provides a convenient and effective general way to identify and represent certain dependencies among items in fuzzy transactions (Ceruto, Lapeira, Rosete & Espin, 2013). We believe that fuzzy predicates in CNF and DNF can be generalized somewhat because they produce patterns that the classic methods cannot obtain; we can also use it to generate an equivalent pattern. For instance, in classic logic ¬A ∨ B is equivalent to a conditional rule A → B (Bruno, 1998; Trillas, 2009).
It is worth clarifying that some logical expressions that are equivalent in classical logic may have different truth values in fuzzy logic. In addition, the truth value of a formula depends on the type of fuzzy operator used. This implies that two formulas that are equivalent in classical logic are only approximately equivalent (i.e., only to a certain degree) in fuzzy logic. For example, it has been stated that the Axioms of Kleene Algebra are more true than false in Compensatory Fuzzy Logic (Espin, Fernandez, Mazcorro, Marx-Gómez & Lecich, 2006).
Fuzzy predicate mining is a task that can be faced as an optimization problem. You can combine fuzzy set concepts and higher-level procedures (i.e., metaheuristics) to find and generate automatically good fuzzy predicates. This learning process is not supervised.
All techniques require a suitable measure to evaluate the model correctly. When mining fuzzy predicates, only one quality measure is of value: the Fuzzy Predicate Truth Value (FPTV) (Ceruto, Lapeira, Rosete & Espin, 2013). Although the FPTV is not robust to outliers, it penalizes the presence of zeros strongly (i.e., veto criteria). This property introduces the necessary capacity of restriction in compensation when certain goals are not fully satisfied (Espin, Fernandez, Mazcorro, Marx-Gómez & Lecich, 2006). The use of a universal quantifier also restricts the final output, which will be determined by the type of fuzzy logic operator selected. As a result, we can conclude that other formulas that can be used to evaluate the quality of the predicates must be determined.
Measuring the quality of the discovered patterns is an active and important area of data mining research. For example, measures for association rules such as confidence, lift and certainty factor have been used extensively (Guillet & Hamilton, 2007; Chandraveer, Sana & Zaid, 2013). However, these measures are defined in terms of the antecedent and consequence (i.e., the structure of the model). Some of the measures that have been proposed for association rules, such as "support," may be used as a basic inspiration for measuring the quality of fuzzy predicates; in this paper, we focus on the limitations of some of the association rule measures and how they can be adapted to fuzzy predicates. Then, we propose several new quality measures for fuzzy predicates under a different knowledge representation model.
Section 2 addresses the basic definitions of the association rules and support measure. The second important pillar in this paper is the explanation of the primary concepts of fuzzy predicates in CNF and DNF (section 3). In section 4, we present the proposed quality measures for fuzzy predicates in CNF and DNF. Section 5 shows and discusses the results that are obtained using the proposed measures with real-world datasets. Section 6 presents some concluding remarks.
Association rules
An association rule is an expression of the form A → B, where 'A' and 'B' are different sets of attributes. This rule can be evaluated by a number of quality measures, but "support" is one of the best-known measures that is not defined in terms of the antecedent and consequence (Agrawal & Srikant, 1994).
]]> Support is the percentage of transactions that contain both A and B:
In (1), the numerator is the number of transactions that contain the itemset (A and B), and X is the size (i.e., number of transactions) of the database. Its values are in the range [0, 1]. If the antecedent and consequence are not present in any transaction, then it is equal to 0. If they occur in all transactions, its value is equal to 1.
An itemset with a support greater than the minimum support threshold is called a frequent or large itemset.
The disadvantage of support arises in the rare item problem. Items that occur very infrequently in the data set are deleted, although they would still produce interesting and potentially valuable rules (Sheikh & Tanveer, 2004).
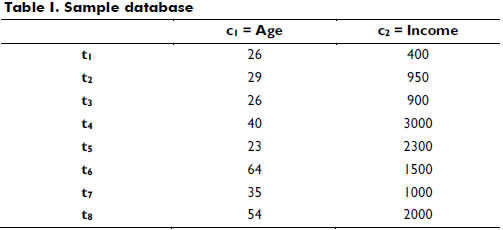
If T = {t1, t2, ..., tn} is the database, and ti represents one tuple in T, C = {c1, c2, ..., cm} can represent all attributes of the database. Table 1 shows a sample database with quantitative attributes (e.g., age and income). Thus, T = {t1, t2, t3, t4, t5, t6, t7, t8 } and C = {Age, Income}. For example, if the value of Income in the fourth record is required, t4 [c2] can be used to get the value 3000.
The theory of fuzzy sets can certainly help data mining reach this goal. The adjective "fuzzy" seems to be very popular and frequently used in contemporary studies concerning the logical and set-theoretical foundations of mathematics. Using the fuzzy set concept, the discovered patterns are more understandable to human comprehension. Fuzzy sets manage values more efficiently than existing methods because fuzzy sets soften the effect of sharp boundaries (Zadeh, 1965; Zadeh, 1975; Fayyad, Piatetsky-Shapiro & Smyth, 1996; Duarte, 1999; Han & Kamber, 2006; Venugopal, Srinivasa & Patnaik, 2009).
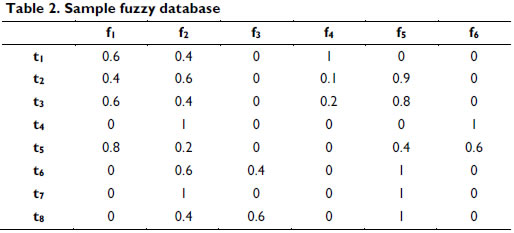
]]> We can define a set of meaningful linguistic labels represented by fuzzy sets on the domain of the quantitative attributes in Table 1; these are used as a new domain (Galindo, Urrutia & Piattini, 2006).Several fuzzy sets F= {f1, f2,..., fk} may be associated by attribute; for instance, if each attribute has three fuzzy sets, FAge may equal {f1=young, f2=middle-age, f3=old}, and FIncome may equal {f4=low, f5=medium, f6=high}.
This process is called fuzzification and may be performed using many of the available membership functions; for example, triangle, trapezoidal or left and right shoulder functions are commonly used because they yield good results, and their computation is simple. Other authors have proposed the use of other shapes including Sigmoid and Gaussian shapes (Cox, 1994; Mitsuishi, Endou & Shidama, 2000; Galindo, Urrutia & Piattini, 2006). Table 2 presents what could occur if the quantitative attributes (Table 1) were replaced by fuzzy attributes.
The standard approach to generalizing the quality measures for fuzzy association rules (Delgado, Marín, Sánchez & Vila, 2003) is to replace the set-theoretic operations, namely the Cartesian product and cardinality, with corresponding fuzzy set-theoretic operations: negation, t-norm and t-conorm (Dubois, Hüllermeier & Prade, 2003). These definitions establish families of measures, depending of the evaluation method and the quantifier of choice (Mitsuishi, Endou & Shidama, 2000).
Table 3 illustrates the computation of support for different examples of fuzzy association rules based on the database in Table 2 using the definitions of Zadeh (1965) (i.e., minimum for conjunction and maximum for disjunction).

Fuzzy predicates in CNF and DNF
]]> Predicates are commonly used to refer to the properties of objects by defining the set of all objects that have some property in common. In general, a predicate is a statement that may be true or false depending on the values of its variables. However, in fuzzy logic, the strict true/false valuation of the predicate is replaced by a quantity interpreted as the degree of truth (Trillas, 2009).A fuzzy predicate may be a tree where each internal node may be a fuzzy operator (e.g., conjunction, disjunction, and negation), and each leaf is a fuzzy variable of the database (Trillas, 2009). Each fuzzy variable can be associated with adverbs called hedges, which are terms that modify the shape of fuzzy sets. Hedges have two primary behaviors: reinforcement, such as "very", or weakening, such as "little" (Bouchon-Meunier & Yao, 1992).
A formula is in conjunctive normal form (CNF) if it is a conjunction of clauses, where a clause is a disjunction of literals; otherwise put, it is an AND of ORs. A formula is in disjunctive normal form (DNF) if it is a disjunction of clauses, where a clause is a conjunction of literals. As in the DNF, the only propositional connectives that a formula in CNF can contain are AND, OR, and NOT. The NOT operator can only be used as part of a literal, which indicates that it can only precede a propositional variable or a predicate symbol.
We believe that fuzzy predicates in CNF and DNF have some grade of generality because they yield patterns that classic methods cannot obtain; also, equivalent patterns can be generated. This transformation is based on the rules of logical equivalences (Bruno, 1998) (Trillas, 2009). Even when these equivalences are more true than false in multivalued logic, fuzzy predicates in CNF and DNF is a good pattern representation to generalize knowledge.
These predicates are sometimes created by a human expert or, in the best circumstances, by the mutual consent of a group of them. However, they can also be created by algorithms that "learn" when "processing" real data. Predicate mining is a task that can be examined as an optimization problem and metaheuristics can be used to solve it.
Each fuzzy predicate in CNF or DNF can code by a vector that represents the attributes in different clauses and values. You can use positional integer encoding, where each value has a translation according to the following scale (see Table 4). In the predicate, variables can appear more than once (i.e., they may be included in two or more clauses).}
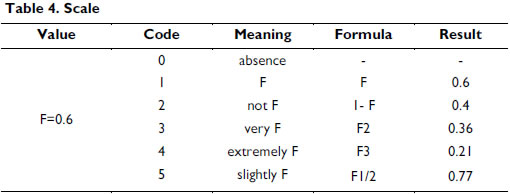
An example of one predicate and its corresponding code solution is shown in Table 5.
]]>

For each predicate, the unique quality measure that is known is the FPTV (Ceruto, Rosete & Espin, 2010), which depends on the number of clauses (Z), variables (Y) and records (X) of the data set. The fuzzy value of the FPTV is in range [0, 1]:

The procedure to compute FPTV is summarized in the next pseudocode.
BEGIN
For each record in the database (X)
For each clause in the predicate (Z)
For each attribute of the clause (Y)
Calculate the real value (TVvar) of all attributes involved in the predicate (use Table 4) ]]>
The FPTV is computed using fuzzy logic operators. Fuzzy logic does not give a unique definition of the classic operations such as union or intersection. Different operators that can be used imply differences in the truth value that will be obtained. Zadeh operators (i.e., min-max) are insensitive (Zadeh, 1965). In this case, the change of one argument may not change the value of the result (e.g., 0.5 ∧ 0.5 = 0.5; 0.5 ∧ 0.8 = 0.5). Probability operators (Mizumoto, 1981a) are not idempotent; the conjunction of two variables with the same values does not result in the same number (0.5 ∧ 0.5 = 0.25). Compensatory fuzzy logic is sensitive and idempotent (Espin, Fernandez, Mazcorro, Marx-Gómez & Lecich, 2006) because associativity is excluded; examples of this include the Geometric Mean and their dual (Mizumoto, 1989).
To illustrate the computation of FPTV, we show a simple example based on the database in Table 2, the predicate in Table 5 (i.e., DNF with two clauses) and the Zadeh fuzzy operator (i.e., minimum and maximum) using the pseudocode described above. In Table 6, the first three columns represent the TV of all variables. The fourth denotes the result of computing the TV of the first clause (i.e., middle-age AND NOT high) using a minimum to create the conjunction between the first and second column. The TV (clause 2) has the same value of TV (very medium).
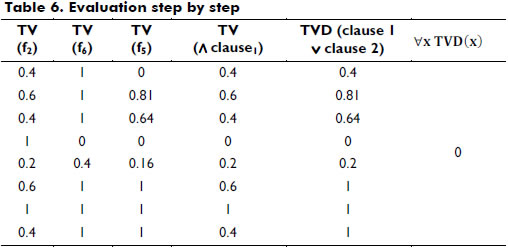
As shown in this example, the FPTV of this predicate is 0 (i.e., conjunction of the values obtained in TVD) because there is a zero in the fourth row. Veto criteria introduce this hard restriction when certain goals are not satisfied (Espin, Fernandez, Mazcorro, Marx-Gómez & Lecich, 2006). This record is only an outlier; in general, the predicate functions well in this database. If it happens during the search, the predicate obtained would be wrongly discarded.
Conversely, it always uses the universal quantifier (i.e., conjunction of all results). This operator tends to restrict the output that will be determined by the type of fuzzy logic operator that is selected. FPTV will only return a high true value when all records have higher values.
]]> For all of the reasons mentioned before, it is important to have others measures to evaluate the quality of fuzzy predicates in normal form to guide the search.New quality measures of fuzzy predicates in CNF or DNF
The first measure proposed is the Fuzzy Predicate Support (FPS). In this case, the numerator is the sum of the truth values of the predicate in each tuple without applying the universal quantifier in each transaction divided by the absolute number of transactions. FPS can be interpreted as the average support of the predicate:

The second measure is the Fuzzy Predicate Binary Support (FPBS). FPBS allows the determination of which percentage of records in the databases has a truth value below the threshold. Depending of the threshold selected, if the value of FPBS is low, then the predicate is not good:
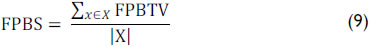
In this case, a threshold is used to calculate the Fuzzy Predicate Binary Truth Value (FPBTV) in each record. FPBTV can be considered alpha-cut (i.e., a subset of elements with membership grades of at least alpha).
Table 7 shows the computation of FPS and FPBS following the previous example. The selected threshold was 0.4, and all values greater than or equal to the threshold were set to 1.
The other proposals are associated with measures of central tendency. The mean or average is affected by the asymmetry of the data distribution and the presence of "outliers." For these reasons, average pruning, a technique in machine learning that reduces the size of the instances by removing sections that may be based on noisy or mistaken data, is selected for use (Han & Kamber, 2006). To calculate it, the data are first sorted in ascending order, and then a certain percentage of data in each end of the distribution is removed.
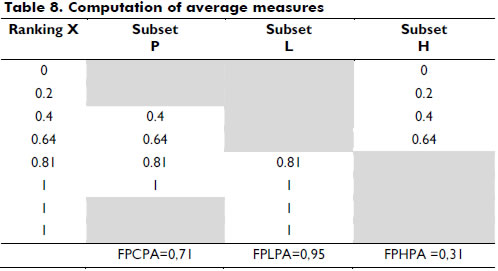
We propose three new measures (see Table 8):
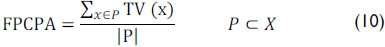
This measure may be interpreted as the average truth value of the transaction with median truth values; it yields a version of the Fuzzy Predicate Support (FPS) that is less sensible to the extreme truth values in the transactions.
]]>
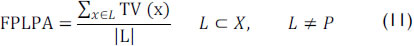
This measure may be interpreted as the average truth value of the transaction with high truth values; it yields an optimistic version of the FPS.
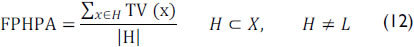
This measure may be interpreted as the average truth value of the transaction with low truth values; it yields a pessimistic version of the FPS.
In addition, we propose a measure of comprehensibility, which attempts to quantify how easy it can be to understand the predicate. The generated predicates may have a large number of attributes, making them difficult to understand. In the cases of association rules, there have been some measures to manage this subject by evaluating the number of variables that are included in the rule (Martín, Rosete, Alcala-Fdez & Herrera, 2013). The same idea may be applied to fuzzy predicates.
]]> The Fuzzy Predicate Comprehensibility (FPC) is defined as:

In equation 13, Y is the number of variables involved in the predicate. This measure may be interpreted as the inverse of the number of variables that are used in the predicate. As shown, this measure does not depend on the number of fuzzy variables in the databases. The value of FPC in the previous example is 0.33.
The fuzzy value of all measures proposed in this section is in the range [0, 1], where the value 1 indicates the best possible value (i.e., the given knowledge is true in all database); if the value drops to 0, the fuzzy value is more false than true.
The last measure proposed is the Quantity of Zeros (QZ) in the databases. This measure helps to determine if the value of FTPV is accurate. If the value of QZ is low, while the other measures have a high true value, then the value in question is likely an outlier, and the predicate then provides relevant knowledge.
Experiments
This section illustrates how the proposed measures can be used to evaluate the quality of fuzzy predicates in normal form. Experiments were conducted with real-world datasets available in UC Irvine Machine Learning Repository (http://archive.ics.uci.edu/ ml/). The algorithm used in this experiment to discover fuzzy predicates in CNF or DNF is called FuzzyPred, which was proposed by Ceruto, Rosete & Espin (2010); Rosete, Ceruto, Espin & Marx-Gómez (2011); and Ceruto, Lapeira, Rosete & Espin (2013).
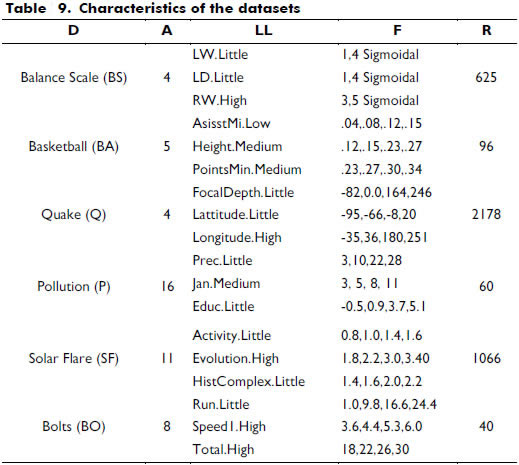
Table 9 summarizes the primary characteristics of the datasets, which uses the following labels: D = databases; A = total number of attributes; LL = linguistic labels used; F = parameters of fuzzification; R = quantity of records. We extracted three quantitative attributes randomly from each database. The membership functions of each attribute were defined primarily by a uniform partition with trapezoidal membership functions. The linguistic label for each variable selected was also selected randomly.
]]>
We perform 30 runs, each with a maximum of 500 iterations, using several metaheuristics to obtain predicates with high truth values (FPTV) using FuzzyPred. The FPTV was computed using the Zadeh Operator (Min-Max).
Table 10 contains the evaluations of the best three predicates in each database using all proposed measures. The first column (Fuzzy Predicated Identifier, FPId) corresponds to an identifier associated with each predicate in each database. The first part of the FPId identifies the corresponding database; for example, BS2 is a predicate obtained from the database Balance Scale (BS). The selected threshold to compute the measure FPBS was 0.2.
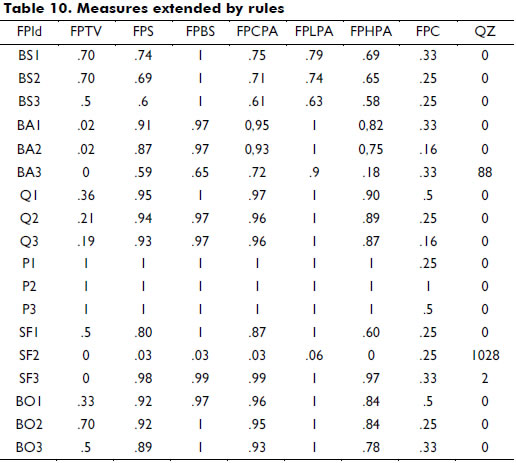
Because the number of potentially applicable predicates may be large, we illustrate one example for each database:
Analyzing the results presented in the Table 10, the following facts can be stated:
Conclusions
The approach outlined in this paper justifies the use of different types of quality measures for fuzzy predicates in CNF and DNF. We compared fuzzy predicate truth values to seven other measures, three of which were statistical. The experiments show that when FPTV is near 1, no other measure is required for good performance. We suggest that the new measures are a good choice in other cases, particularly when FPTV is equal to 0 because they can help determine if the veto criteria are important. The proposed measures may be used to evaluate fuzzy predicates in different contexts independently of the way they are obtained. We also intend to use diverse and extensive test data to confirm the claims made in this paper.
References
Agrawal, R., & Srikant, R. (1994). Fast Algorithms for Mining Association Rules. In Proc. 20th Very Large Data Bases, 487-499. [ Links ]
Bruno, A. (1998). Normal forms. Mathematics and Computers in Simulation, 45, 413-427. [ Links ]
Bouchon-Meunier, B., & Yao, J. (1992). Linguistic modifiers and imprecise categories. International Journal of Intelligent Systems, 7(1), 25-36. [ Links ]
]]>Ceruto, T., Lapeira, O., Rosete, A., & Espín, R. (2013). Discovery of fuzzy predicates in database. Advances in Intelligent Systems Research, 51, 45-54. [ Links ]
Ceruto, T., Rosete, A., & Espín, R. (2014). Knowledge Discovery by Fuzzy Predicates. Soft Computing for Business Intelligence, 537, 187-196. [ Links ]
Chandraveer, S., Sana, A., & Zaid, M. (2013). Comparison of Interestingness Measures: Support-Confidence Framework versus Lift-rule Framework. International Journal of Engineering Research and Applications, 3(2), 208-215. [ Links ]
Cox, E. (1994). The Fuzzy Systems Handbook: A Practitioner's Guide to Building, Using, and Maintaining Fuzzy Systems. Boston: AP Professional. [ Links ]
Delgado, M., Marín, N., Sánchez, D., & Vila, M. (2003). Fuzzy association rules: general model and applications. IEEE Transactions on Fuzzy Systems, 11(2), 214-225. [ Links ]
]]>Duarte, O. (1999). Sistemas de Lógica Difusa-Fundamentos. Revista Ingeniería e Investigación, 42, 22-30. [ Links ]
Dubois, D., Hüllermeier, E., & Prade, H. (2003). A note on quality measures for fuzzy association rules. In Fuzzy Sets and Systems-IFSA 2003, 346-353. [ Links ]
Espin, R., Fernandez, E., Mazcorro, G., Marx-Gómez, J., & Lecich, M. (2006). Compensatory Logic: A fuzzy normative model for decision making. Investigación Operacional, 27(2), 178-193. [ Links ]
Fayyad, U., Piatetsky-Shapiro, G., & Smyth, P. (1996). The KDD Process for Extracting Useful Knowledge. Communications of the ACM, 39, 27-34. [ Links ]
Galindo, J., Urrutia, A., & Piattini, M. (2006). Fuzzy Databases: Modeling, Design and Implementation (pp. 341). Idea Group Publishing. [ Links ]
]]>Guillet, F., & Hamilton, H. (2007). Quality Measures in Data Mining. Studies in Computational Intelligence, 43. [ Links ]
Han, J., & Kamber, M. (2006). Data Mining: Concepts and Techniques (pp. 1-14) (2nd ed.). The Morgan Kaufmann Series in DataManagement Systems. [ Links ]
Martín, D., Rosete, A., Alcala-Fdez, J., & Herrera, F. (2013). QAR-CIP-NSGA-II: A new multi-objective evolutionary algorithm to mine quantitative association rules. Information Sciencies, 258, 1-28. [ Links ]
Mitsuishi, T., Endou, N., & Shidama, Y. (2000). The concept of fuzzy set and membership function and basic properties of fuzzy set operation. Journal of Formalized Mathematics, 9(2), 315-356. [ Links ]
Mizumoto, M. (1981). Fuzzy Sets and their Operations I. Information and Control, 48(1), 31-48. [ Links ]
]]>Mizumoto, M. (1989). Pictorial Representations of fuzzy conectives, Part II: cases of Compensatory operators and Self-dual operators. Fuzzy Sets and Systems, 32, 45-79. [ Links ]
Rosete, A., Ceruto, T., Espin, R., & Marx-Gómez, J. (2011). A General Method for Knowledge Discovery Using Compensatory Fuzzy Logic and Metaheuristics. In Gathering Knowledge Discovery, Knowledge Management and Decision Making (pp. 240-271). [ Links ]
Sheikh, L., Tanveer, B., Hamdani, M. (2004). Interesting measures for mining association rules. In Proceedings of INMIC 2004 (pp. 641-644). [ Links ]
Trillas, E. (2009). On a model for the meaning of predicates. A naive approach to the genesis of fuzzy sets. Studies in Fuzziness and Soft Computing, 243(9), 175-205. [ Links ]
Venugopal, K., Srinivasa, K., & Patnaik, L. (2009). Soft Computing for Data Mining Applications. Studies in Computational Intelligence, 190, 1-15. [ Links ]
]]>Zadeh, L. (1965). Fuzzy Sets. Information Control, 8, 338-353. [ Links ]
]]>