ERRORS IN THE USE OF ENGLISH TENSES
ERRORES EN EL USO DE LOS TIEMPOS VERBALES EN INGLÉS
Carmen Gloria Garrido*; Cristina Rosado Romero**
* holds a Master Degree in Education from Universidad de Concepción, Chile. She currently works as full time professor at Universidad San Sebastián, Chile. Mailing address: Camilo Henríquez 2710. Depto 401- A, Concepción, Chile. Post code: 4080655. E-mail: Carmen.garrido@uss.cl
]]> ** is an English-Spanish translator from Universidad de Concepción, Chile. She currently works as a professor at Universidad San Sebastián, Chile. E-mail: crosador@docenteuss.cl
Received: 04-28-11 / Reviewed: 05-21-12 / Accepted: 08-23-12 / Published: 12-01-12
How to reference this article: Garrido, C., & Rosado, C. (2012). Errors in the use of English tenses. Íkala, revista de lenguaje y cultura, 17(3), 285-296.
ABSTRACT
This article presents the results of an error analysis investigation carried out in Concepción, Chile, with a group of forty-eight native speakers of Spanish studying to become EFL teachers at Universidad San Sebastián. All participants were first year students who had studied English tenses and aspects for a year. The objectives of this investigation were the identification of students' errors regarding the use of tenses and aspects in English, the design of a hierarchy of difficulty and the explanation of main errors. According to the results obtained, after a year of formal instruction, students still showed problems with the correct use of English tenses and aspects. The main problem was accurately matching tenses and aspects to different contexts. Findings provide useful information to design remedial programmes to help students become successful in the use of English tenses and aspects.
Keywords: grammar, tenses, errors, context, formation, difficulties
RESUMEN
]]> Este artículo presenta los resultados de una investigación basada en el análisis de errores realizada en Concepción, Chile, con un grupo de cuarenta y ocho hablantes de español que estudian Pedagogía en Inglés en la Universidad San Sebastián. Todos los participantes eran alumnos de primer año que habían estudiado tiempos verbales y aspectos del inglés durante un año. El trabajo tuvo como objetivos la identificación de errores en relación al uso de tiempos verbales y aspectos en inglés; el diseño de una jerarquía de dificultades y la explicación de los principales errores. De acuerdo con los resultados, después de un año, los alumnos presentan problemas con el uso correcto de los tiempos verbales y aspectos, siendo el uso de acuerdo al contexto el mayor problema. Los resultados de esta investigación entregan información para el diseño de programas que ayuden a los alumnos a usar con éxito los tiempos y aspectos del inglés.Palabras claves: gramática, tiempos verbales, errores, contexto, formación, dificultades
1. INTRODUCTION, LITERATURE REVIEW, RESEARCH QUESTIONS
Introduction
Future English teachers studying at Universidad San Sebastián (USS) study grammar from the first semester onward. In the first year, they take English Grammar and Lexis I and English Grammar and Lexis II (each course lasts one semester). In both courses, they study the use and formation of English tenses and aspects. They have class twice a week for a period of eighty minutes. At the end of English Grammar and Lexis II, students are expected to use English tenses and aspects accurately. However, a high percentage of students (more than 60%) has failed the subject English Grammar and Lexis II in the last three years. This situation shows there is a problem to be solved. Because the emphasis of the syllabus is on tenses and aspects, it can be inferred that the main problem lies in the errors made by students in the use of English tenses and aspects.
The objectives of this investigation were (1) the identification of students' errors regarding the use of tenses and aspects in English, (2) the design of a hierarchy of difficulty and (3) the explanation of main errors to provide information about the difficulties students encounter when learning the formation and use of English tenses and aspects. This information can be used to design materials to help students succeed in the process of learning to use tenses and aspects accurately.
This study follows the Corder (1971) error analysis model. The model consists of a comparison between the utterances made by a learner of the target language and the same utterances made by an adult native speaker of that target language and establishes a set of steps to carry out error analysis. In this study, categories are established following Dulay, Burt and Krashen's surface taxonomy (1982). This taxonomy classifies errors into four categories: omission, addition, misformation and misordering.
The study of errors is important since errors permit the description of developmental stages in the acquisition of a second/foreign language. For learners themselves, errors are indispensable, because the making of errors can be regarded as a device the learner uses in order to learn. From a pedagogical perspective, errors can give invaluable information in relation to the difficulties students encounter when learning English as a second or foreign language.
]]> Literature reviewError analysis (EA) was established by Stephen Pit Corder and colleagues in the 1960s and ''consists of a set of procedures for identifying, describing and explaining learners' errors'' (Ellis & Barkhuizen, 2005, p. 51). According to Corder (1981), learners' errors are significant in three ways: first, they give information about the language a learner is using; second, they provide information on how a language is learnt and finally, they provide information to the learner himself or herself since errors can be regarded as a device the learner uses in order to learn. Error analysis also has pedagogical benefits because it gives useful input for designing and carrying out the teaching/learning process.
Error analysis became a common method of getting information about learners' language during the early 1970s as an alternative method to contrastive analysis which was based on behaviourist theories and therefore claimed that the difficulties in mastering certain structures in a second language (L2) were only based on the differences between the learners' mother language (L1) and the second language (L2). Error analysis has become less used mainly because it has some limitations. First, it only focuses on learners' errors and not on what learners can do right. According to Brown (2000), another disadvantage of EA is the fact that it overemphasizes production data. James (1998) and Tarone (1981) have also shown that EA fails to account for avoidance strategy. Despite these drawbacks, error analysis is still considered a useful tool to gather information about learners' language. Erdogan (2005), for example, states that ''error analysis enables teachers to find out the sources of errors and take pedagogical precautions towards them'' (p. 262). For Mahmoud (2011), EA constitutes a link between language learning and teaching that can be exploited in initial as well as remedial teaching. As these authors illustrate, EA can become a useful tool to improve language teaching and, consequently, student learning.
When conducting research based on error analysis, a distinction between errors and mistakes must be made. Mistakes are unsystematic, due to memory lapses, physical states (tiredness) or psychological conditions while errors are systematic and correspond to the underlying knowledge of the language or transitional competence. An error is ''a linguistic form or combination of forms, which in the same context and under similar conditions of production, would, in all likelihood, not be produced by the speakers' native speaker counterparts'' (Lennon, 1991, p. 182). An error, therefore, reflects the learner's competence in L2. According to Brown (2000), a mistake can be self- corrected while an error cannot. This means, given the time and opportunity, the student should be able to correct his/her mistake(s).
Corder (1981) establishes four steps to carry out error analysis research: collection of learners' speech sample, identification of errors, the description of the errors that have been identified and finally the explanation of learner's errors.
In the first step, researchers collect a sample of learner language. Because the type of sample that is collected may influence the nature and distribution of the errors observed, it is important to describe the type of discourse collected and whether learners had time to plan their production or not.
The identification of errors is the second step. It involves a comparison between what the learner has produced and what a native speaker counterpart would produce in the same context. Every utterance/sentence produced by the learner is assumed to be erroneous. Those utterances that are shown to be well-formed through a comparison with a native speaker's sample are eliminated. The remaining utterances/sentences are the ones that contain errors.
Once errors have been identified, the next step is describing learners' errors. To do so, it is necessary to have descriptive categories to classify and record the frequency of the errors that have been identified. There are different categories for describing errors. Corder (1981) classifies errors into two categories: overt and covert errors. ''Overtly erroneous utterances are unquestionably ungrammatical at the sentence level. Covertly erroneous utterances are grammatically well-formed at the sentence level, but are not interpretable within the context of communication'' (Brown, 2000, p. 220). Dulay, Burt and Krashen's (1982) surface structure taxonomy is based on the ways surface structures are altered in erroneous utterances/sentences. According to this taxonomy, there are four principal ways in which learners modify target forms: omission, addition, misformation and misordering. Errors of omission refer to an element which should be present but has been omitted. Addition is the presence of an element which should not be part of the sentence or utterance. Misformation is the use of the wrong form or morpheme or structure. Misordering errors are incorrect placement of a morpheme or group of morphemes in an utterance.
The last step is the explanation of learners' errors. Even though the explanation of errors is still highly speculative because of the complex psychological and neurological process involved in language learning, experts have identified three major processes: interlingual transfer, intralingual transfer and context of learning. Interlingual errors are explained as the results of mother tongue influences. Intralingual errors reflect the operation of learning strategies that can be considered universal. According to James (1998) these strategies can be classified as false analogy, misanalysis, incomplete rule application, exploiting redundancy, overlooking co-occurrence restrictions and system simplification. Finally, context of learning refers to the learning experience. The non-occurrence or low frequency of errors could be the result of a successful teaching. On the other hand, a high frequency of errors could be the result of inappropriate teaching methods and materials.
Error analysis focuses on the errors learners make and is based on the comparison of learners' utterances/sentences in the target language and a native's utterances/sentences. Although error analysis has some drawbacks, it can help us to see how a learner's production deviates from target language forms and get information about the difficulties students face when learning a second or foreign language. With this information, instructors can plan the teaching/learning process to help students become successful in the task of learning a foreign or second language.
]]> Research questions
2. METHOD
Participants
A group of forty-eight native speakers of Spanish studying to become EFL teachers at Universidad San Sebastián participated in this study. All participants were first year students who had studied English tenses and aspects for a year in their English and Grammar & Lexis classes (English Grammar and Lexis I and English Grammar and Lexis II). They studied tenses and aspects in both courses, though these topics were particularly emphasized in English Grammar and Lexis II.
Instruments, materials, apparatus
]]> Following Corder (1981), the first step was to collect a sample of learner language. To collect this sample, students were asked to translate a letter from Spanish into English (see Appendix 1). The translation required the correct use of all tenses studied in class (simple present, present continuous, present perfect, present perfect continuous, simple past, past continuous, past perfect and simple future).This activity was one of the final evaluations of Grammar and Lexis II. Students had eighty minutes to plan, write the translation of the letter and check mistakes.
Data analysis
A translation into English of the letter written in Spanish was prepared and those sentences containing tenses studied in class which differed from the reconstructed version were identified. The analysis considered only errors in the use of English tenses and aspects. The next step was the analysis of erroneous sentences. Since English Grammar and Lexis I & II were taught by two different teachers (one of them was also an English-Spanish translator), both teachers were responsible for the analysis of errors. Each teacher worked individually and then shared results. In case of discrepancy, the other teacher was asked his opinion and errors were further analysed until agreement was reached. The first step was the classification of errors into two main categories: overt and covert errors. Overt errors were further classified using Dulay, Burt and Krashen's (1982) Surface Structure Taxonomy. Consequently, errors were classified into the following categories: omission, addition, misformation and misordering.
Once errors were classified into the different categories, type and frequency of errors were recorded. In the last step the source of the errors was explained. Because of the type of sample collected and the information gathered, only two processes were identified: interlingual and intralingual errors.
3. RESULTS AND DISCUSSION
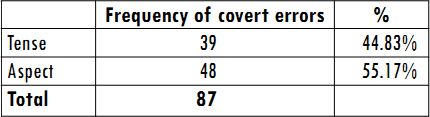
Following Corder (1981), errors were first classified into overt and covert errors (see Table 1). Both covert and overt errors were further analysed and even though the explanation of errors is speculative, explanations that could guide the teaching learning process were given by the researchers.
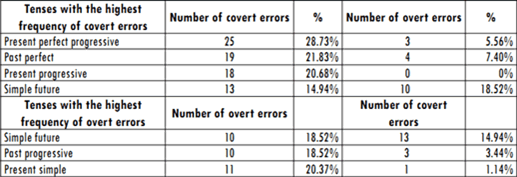
According to the analysis, covert errors show the highest frequency. In this category, tenses with the highest frequency of errors correspond to the present perfect progressive (28.73%), past perfect (21.83%), present progressive (20.68%) and simple future (14.94%).
The problem with present perfect progressive is not the choice of tense, but the choice of aspect (100% of errors corresponds to this type of error). A similar situation can be seen with the use of present progressive, with 94.44% of errors corresponding to wrong choice of aspect. Following James' (1998) classification of intralingual errors, the wrong choice of aspect can be categorized as system simplification because students consider the correct choice of tense as enough to express the writer's perspective on the time of an event.
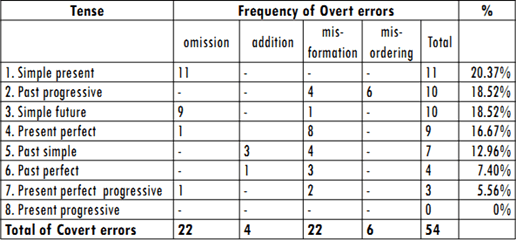
]]> The students showed problems with the choice of tense regarding the use of past perfect and simple future, both with 100% of errors corresponding to wrong choice of tense. Students used present perfect instead of past perfect. This error can be explained as false analogy because students seem to be overgeneralizing the use of present perfect. As to the wrong choice of future, the error can be explained as interference of L1 because in students' native language, the simple present would be used for the same context.Respect to overt errors (54 errors), the tenses with the highest frequency of errors are the simple present (20.37%), past progressive (18.5%), simple future (18.5%) and present perfect (16.7%). The present progressive is the only tense with zero errors of this type.
One-hundred per cent of errors using simple present corresponds to the omission of the third person s. This type of error can be labelled as exploiting redundancy, which means students are omitting characteristics of language that do not change the meaning of the utterance.
The most frequent error for the past progressive (18.5%) corresponds to misordering. After analysing students' answers, it can be concluded that there is interference from L1 because the structure of students' answers corresponds to the structure of sentences grammatically accepted in Spanish.
Even though the simple future appears with a high frequency of errors (18.5%), most of those errors correspond to the formation of the simple present since students chose this tense for the given context.
Finally, the present perfect (16.67%) also shows a high frequency of errors. The most frequent error is misformation (use of infinitive instead of past participle form of an irregular verb). This means there is incomplete rule application.
The high frequency of covert errors indicates that students have problems with the correct use of aspect. Remedial tasks to raise students' awareness of the importance of aspect should be implemented. Also, exercises contrasting the use of present perfect and past perfect could help students use these tenses appropriately. Finally, some contrastive analysis between English and Spanish could help students internalize the use of simple future in English.
The analysis of overt errors in students' work suggests a need for drilling and more time devoted to weak aspects detected such as the omission of third person s, the wrong order of elements and the incorrect use of past participle form of irregular verbs. Again, some contrastive analysis between English and Spanish could help students learn the patterns for word order in the formation of English tenses.
Table 1: Frequency of errors
]]>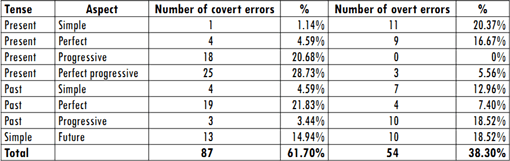
Table 2: Tenses with the highest frequency of errors
COVERT ERRORS
Table 3: Total frequency of covert errors: tense and aspect
TENSE: PRESENT
]]> Aspect: SimpleExpected answer: Hugo wants
Student's error: Hugo will want
Table 4: Simple present frequency of errors
As Table 4 shows, only one student chose the wrong tense regarding simple present. This means most students have mastered the use of simple present in English.
Aspect: Progressive
Expected answer: I am writing ...
]]> Students' errors:
Table 5: Present progressive frequency of errors
]]> Eighteen (out of forty-eight) students had problems identifying progressive aspect as the aspect a native speaker would have used for the given context. This number represents 94.44% of errors for the expected answer ''I'm writing ...'' and 37.5% of all covert errors, which means a significant number of students have not learned the correct use of the present progressive in English.
Aspect: Perfect
Expected answer: You haven't written...
Students' errors:
]]> Table 6: Present perfect frequency of errors
Only four students could not identify the present perfect as the correct tense for the given context. Those students seem to be confused with tense and aspect.
Table 7: Present perfect progressive frequency of errors
This is the tense with the highest frequency of errors. Students used continuous aspect instead of the perfect continuous. This error shows students can identify and use the tense but confuse the use of perfect continuous and the use of continuous aspects in English.
PRESENT
]]> Total frequency of errors
Table 8: Present tenses total frequency of errors
TENSE: PAST
Aspect: Simple
Expected answer: Did you receive the letter?
Students' errors:
Table 9: Simple past frequency of errors
Table 10: Past progressive frequency of errors
]]> This tense represents one of the tenses with the lowest frequency of covert errors. And even though aspect is wrong, tense is correct, which means students can identify the time of the situation.
Aspect: Perfect
Expected answer: I had never seen ...
Students' errors:
Table 11: Past perfect frequency of errors
]]>This tense presents a high frequency of errors. All students made the same mistake: they used present perfect instead of past perfect.
PAST
Total frequency of errors
Table 12: Past tenses total frequency of errors
TENSE: FUTURE
Aspect: Simple
]]> Expected answer: When will you come to Europe?Students' errors:
Table 13: Simple future frequency of errors
The use of this tense is not clear for some students who still confuse the use of the simple present tense with the use of the simple future in English.
]]> FUTURE
Total frequency of errors
Table 14: Future total frequency of errors
OVERT ERRORS
The highest frequency of overt errors corresponds to the omission of an element. As the table below shows, the tense with the highest frequency of this type of error is the simple present.
Table 15
]]>
TENSE: PRESENT
Aspect: Simple
Expected answer: Hugo wants ...
Students' errors:
This type of error is a common one among Chilean students learning English as a foreign language. It can be explained as an intralingual error which is overcome with time and practice.
]]> TENSE: PRESENT
Aspect: Progressive
Expected answer: I am writing ...
No errors of the overt type.
TENSE: PRESENT
Aspect: Perfect
Expected answer: You haven't written...
Students' errors:
Results show students still have problems to form the present perfect. The main problem in this case is the past participle of the irregular verb write.
TENSE: PRESENT Aspect: Perfect Progressive
Expected answer: I have been spending ...
]]> Students' errors:This tense does not show a high frequency of errors.
TENSE: PAST
Aspect: Simple
Expected answer: Did you receive the letter?
]]> Students' errors:When analysing the type of errors, it can be inferred that some students do not have difficulties with the formation of the simple past but with the formation of the simple present because this was the tense they chose for the given context. Only three students need more practice with the formation of questions. Therefore, this tense does not show a high frequency of errors.
TENSE: PAST Aspect: Progressive
Expected answer: Our friend Franz was waiting here...
]]> Students' errors:The most recurrent type of error is not the formation of the tense in terms of the elements needed but the position of the subject.
TENSE: PAST Aspect: Past Perfect
]]> Expected answer: I had never seen ...Students' errors:
This tense does not present a high frequency of errors but as with the present perfect there are errors in the formation of the perfect form of an irregular verb.
TENSE: FUTURE Aspect: Simple
]]> Expected answer: When will you come to Europe?Students' errors:
In this tense, the most frequent errors are not really errors in the formation of the future tense, but errors in the correct formation of the simple present which students chose as the correct tense according to the context.
4. CONCLUSIONS
Error analysis attempts at identifying, describing and explaining learners' errors, thereby providing valuable information about the language the learner is using. Even though error analysis has some drawbacks, it is still a useful tool from a pedagogical perspective.
This research used error analysis to study the way first year English Pedagogy students use English tenses and aspects. After analysing students' errors, it can be concluded that the highest frequency of errors corresponds to the covert type.
]]> The wrong choice of aspect is the main type of covert error. Present perfect progressive and present progressive show a high frequency of this type of error. From a pedagogical perspective, these results suggest that it would be helpful to implement remedial tasks to raise students' awareness of the importance of aspect to convey meaning.Utterances containing past perfect and simple future also showed a high frequency of covert errors, but the problem was not the wrong choice of aspect but the wrong choice of tense. To overcome problems using past perfect, we suggest that teachers use exercises that contrast the use of present perfect and past perfect since students seemed to overgeneralize the use of present perfect. Finally, some contrastive analysis between English and Spanish could help students internalize the use of simple future in English.
Although the number of students who showed difficulties with the formation of tenses (overt errors) is not as significant as the number of students who had problems using tenses and aspects, it is an area that also needs to be analysed in terms of the time and type of drilling students need to be exposed to. The omission of the s for the third person singular is the most frequent error. The past participle form of irregular verbs and the position of elements are still a problem for some students.
As our research shows first year English Pedagogy students face problems regarding the use of tenses in English. Therefore, teaching methods and materials should be revised in light of learners' errors to find ways to help them learn the use of tenses and aspects.
This study used error analysis to identify students' errors in relation to the use and formation of English tenses and aspects. Despite the fact that error analysis has some drawbacks, it was an useful tool to obtain information about students' problems and to provide suggestions for improving the teaching-learning process.
REFERENCES
1. Brown, H. (2000). Principles of language learning and teaching. New York, NY: Addison Wesley Longman. [ Links ]
2. Corder, S. (1971). Idiosyncratic dialects and error analysis. IRAL, 9(1), 147-160. [ Links ]
3. Corder, S. (1981). Error analysis and interlanguage. Oxford, England: Oxford University Press. [ Links ]
4. Dulay, H., Burt, M., & Krashen, S. (1982). Language two. Oxford, England: Oxford University Press. [ Links ]
5. Ellis, R., & Barkhuizen, G. (2005). Analysing learner language. Oxford, England: Oxford University Press. [ Links ]
6. Erdogan, V. (2005). Contribution of error analysis to foreign language teaching. Mersin University Journal of the Faculty of Education, 1(2), 261-270. [ Links ]
7. James, C. (1998). Errors in languages learning and use: Exploring error analysis. London, England: Longman. [ Links ]
8. Lennon, P. (1991). Error and the very advanced learner. IRAL, 29(1), 31-44. [ Links ]
9. Mahmoud, A. (2011). The role of interlingual and intralingual transfer in learner-centered EFL vocabulary instruction. Arab World English Journal, 2(3), 28-49. [ Links ]
10. Tarone, E. (1981). Some thoughts on the notion of the communication strategy. TESOL Quarterly, 15(3), 285-295. [ Links ]
APPENDIX 1
Instrument used to gather information.
]]> Instructions:Translate the following letter into Spanish. Marks will be assigned for the correct translation of tenses.
Querida Ana:
Te escribo desde Ámsterdam, donde estoy pasando mis vacaciones con mi pololo, Hugo, desde hace dos semanas.
El vuelo hasta aquí estuvo bien, aunque tuvimos un poco de turbulencia. Salimos de Santiago el 17 de octubre a las 11:00 de la mañana y llegamos el 18 a las 7:00. No hicimos escala en Sao Paulo como otras veces, sino que fue un vuelo directo hasta París, donde tomamos otro avión hasta Ámsterdam. Aquí nos esperaba nuestro amigo Franz para llevarnos a nuestro hotel.
Todo aquí es maravilloso. La gente es muy amable, la comida es deliciosa y la arquitectura es sensacional. Yo no había visto nunca nada como esta ciudad y, como sabes, he viajado bastante. Estuve en Perú, Brasil, Estados Unidos, Italia y Japón.
Ayer visitamos el Museo del Juguete. Fue muy emocionante ver tantas cosas con las que yo jugaba cuando chica, pero lo que más me impactó fue ver un Atari. Mientras jugaba con él, vino el guardia y me dijo que estaba prohibido tocar los juguetes. No me gustó que no me dejara divertirme. Me dio mucha vergüenza.
Hugo quiere visitar el Barrio Rojo, pero yo no. Discutimos todo el tiempo acerca de eso.
En este momento me tomo un jugo en este precioso café cerca del hotel. Hugo conversa con la camarera, que es preciosa. Lo pasamos bien aquí, aunque últimamente me siento un poco celosa.
La próxima semana vamos a Dinamarca. Franz nos acompaña, ya que quiere reunirse con un socio allá. Después viajamos a Colonia, en Alemania, donde yo tengo unos parientes, pero no nos quedaremos allí mucho tiempo. Creo que volvemos a Chile en enero.
]]> ¿Cómo estás tú? ¿Cuándo vienes a Europa? ¿Me echas de menos? ¿Recibiste el mail que te mandé ayer? Tú no me has escrito ¿no es cierto? Cuéntame cómo andan las cosas ahí.Tengo que irme. Te veo en enero.
Cariños,
Sentences considered for error analysis
]]>