ARTÍCULOS
Valor en riesgo: evaluación del desempeño de diferentes metodologías para 5 países latinoamericanos
Value-at-Risk: evaluation of the behavior of different methodologies for 5 Latin American countries
Valor em risco: avaliação do desempenho de diferentes metodologias para 5 países latino americanos
]]> Julio César Alonsoa, Juan Manuel Chavesb
aDirector del Centro investigación en Economía y Finanzas, Universidad Icesi, Cali, Colombia
bJoven investigador, Centro investigación en Economía y Finanzas, Universidad Icesi, Cali Colombia
Autor para correspondencia: Universidad Icesi, Calle 18 N.° 122-135, Cali, Colombia Correo electrónico: jcalonso@icesi.edu.co (J.C. Alonso).
Historia del artículo:
Recibido el 1 de agosto de 2011
Aceptado el 22 de marzo de 2013
Resumen
]]> Este documento evalúa el comportamiento de veinte diferentes métodos (paramétrico, no paramétricos y semi- paramétricos) para estimar el VaR (Valor en Riesgo) de un portafolio representativo para 5 países latinoamericanos (Argentina, Brasil, Chile, Colombia y Perú). Después de encontrar la aproximación que mejor captura el nivel de riesgo seleccionado para cada portafolio, se encontró que los modelos no- paramétricos de simulación histórica y semi- paramétricos corresponde a la mejor medida de riesgo para todos los países de la muestra.Palabras Clave: Valor en riesgo, Backtesting, Aproximación paramétrica, Aproximación no paramétrica, América Latina.
Clasificación JEL: G11, G32
Abstract
This paper evaluates the performance of 20 different methods (parametric, and semi-parametric, and non-parametric), as well as the historical simulation method, to estimate the next- trading- day value- at risk (VaR) of a representative portfolio for 5 different Latin American countries (Argentina, Brasil, Colombia and Peru). We found that the non- parametric (i.e. historic simulation), and the semi- parametric methods were the best way to estimate the risk among the twenty different methods evaluated for all the countries in the sample.
Keywords: Value-at-Risk, Back-testing, Parametric Approach, Non-parametric Approach, Latin America.
JEL Clasification: G11, G32
RESUMO
Este documento avalia o comportamento de vinte diferentes métodos (paramétrico, não paramétrico e semi-paramétrico) para estimar o VaR (Valor em Risco) de um portfólio representativo para 5 países latino americanos (Argentina, Brasil, Chile, Colômbia e Peru). Depois de encontrar a aproximação que melhor capta o nível de risco seleccionado para cada portfólio, percebeu-se que os modelos não-paramétricos de simulação histórica e os modelos semi-paramétricos correspondem à melhor medida de risca para todos os países da amostra.
Palavras-Chave: Valor em Risco Backtesting Aproximação Paramétrica Aproximação não paramétrica América Latina
]]> Classificação JEL: G11, G32
1. Introducción
La gerencia del riesgo se ha convertido en uno de los tópicos más importantes para las instituciones financieras, no financieras, reguladoras y académicas. Este interés ha llevado al centro de la discusión académica y regulatoria, las mediciones de riesgo de mercado. Al mismo tiempo, el valor en riesgo (VaR, en inglés Value at Risk) se ha convertido en una de las herramientas más empleadas para la medición de riesgo tanto por reguladores, agentes y académicos. Una de las razones para esta popularidad es la sencillez del concepto; y, en especial, lo intuitivo de su interpretación. El VaR es la estimación de la máxima pérdida posible para un horizonte de tiempo y un nivel de significancia determinado, bajo circunstancias consideradas como ''normales'' en el mercado (Alonso & Berggrun, 2010).
Si bien el concepto detrás del VaR es muy sencillo y de fácil interpretación, el cálculo de este no lo es, pues implica en la mayoría de casos suponer el comportamiento de la distribución de los rendimientos. Algunas aplicaciones involucran suponer una distribución y un comportamiento de la varianza de los rendimientos, mientras que otras aproximaciones no necesitan supuestos sobre el comportamiento de los rendimientos.
Este documento evalúa el comportamiento predictivo de 20 diferentes aproximaciones de estimación del VaR para los portafolios representativos de 5 países latinoamericanos. Para tal fin, se emplean los rendimientos de los índices de Bolsa de Argentina (Merval), Brasil (Bovespa), Colombia (Igbc), Chile (Igpa) y Perú (Igbvl).
El documento está organizado de la siguiente manera. La primera parte corresponde a esta breve introducción. La segunda discute rápidamente los métodos que se han de emplear para la estimación del VaR. La tercera sección discute los cálculos realizados, así como los métodos que se emplearán para su evaluación. La tercera parte resume los resultados obtenidos. El documento concluye presentando unos comentarios finales.
2. Consideraciones para el cálculo del valor en riesgo
]]> El VaR se define como la máxima pérdida esperada en un portafolio con cierto nivel de confianza en un determinado período de tiempo. Específicamente, siguiendo a Alonso & Berggrun (2010), el VaR para el siguiente período de negociaciones, dada la información disponible en el actual período, (VaRt+1|t) está definido por:
donde Zt+1 representa el cambio futuro en el valor del portafolio en un período de tiempo determinado y α es el nivel de significancia del VaR. Ciertamente, la implementación de la estimación del VaR depende de los supuestos subyacentes sobre la serie de los retornos. Si Zt+1 sigue una distribución cuyos 2 primeros momentos son finitos (como la distribución normal o la t), entonces el VaR será:

donde σ representa la desviación estándar (DE) de la distribución de Zt+1 y F(α) es el cuantil α de la correspondiente distribución (estandarizada). Así, si bien la interpretación e idea detrás del VAR es muy sencilla, su cálculo no lo es. Este depende crucialmente del supuesto de cómo se comporta la volatilidad de Zt+1 (DE σ) y cuál es la distribución F(α) (Alonso & Berggrun, 2010).
Existen varias aproximaciones metodológicas para la estimación del VaR que básicamente se clasifican en: 1) aproximación que implica calcular parámetros poblacionales y suponer una distribución (aproximación paramétrica); 2) aproximación que no necesita calcular parámetros poblacionales ni implica supuestos sobre el comportamiento de Zt+1 (aproximación no paramétrica), y 3) la semiparamétrica que corresponde a una combinación de las 2 anteriores aproximaciones, al calcular algunos parámetros pero no suponer una distribución (por ejemplo, la simulación histórica filtrada). A continuación se describen estas 3 aproximaciones.
2.1. Aproximación paramétrica
Esta aproximación implica suponer una determinada función de distribución F(·) y el comportamiento de la DE σ. Un hecho estilizado muy documentado sobre los rendimientos de activos es la presencia de varianza grupal (volatility clustering)1. En otras palabras, la volatilidad no es constante. Teniendo en cuenta este hecho estilizado, el VaR de un portafolio puede ser entonces estimado usando la siguiente expresión:

donde σt+1 representa la DE condicional a la información disponible en el período t. Un supuesto común es que los retornos diarios se distribuyen normalmente. A pesar de que este supuesto simplifica en gran medida los cálculos del VaR, esto implica un costo relativamente alto. De hecho, existe amplia evidencia que sustenta que las rentabilidades diarias y, por tanto, el valor del portafolio, si bien siguen una distribución acampanada y simétrica, poseen un alto grado de leptocurtosis2.
]]> Por otro lado, dado el supuesto en torno a la distribución de los rendimientos, será necesario determinar un comportamiento de la volatilidad. El modelo más simple para determinar la varianza de los rendimientos σ2t+1 es por medio de la varianza móvil MA (por sus siglas en inglés: Moving Avarage); de esta forma, la varianza recoge la información de los últimos n datos y va cambiando conforme a ella, período a período. Esta se calcula por medio de la siguiente fórmula:
donde Rt-i corresponde al rendimiento del período t-i. Otro método sencillo para calcular el VaR es mediante el promedio móvil ponderado exponencialmente (EWMA, en inglés Exponentially Weighted Moving Average). El EWMA implica la varianza del período siguiente como un promedio ponderado de la varianza actual y el rendimiento actual al cuadrado (z2t).

donde λ representa el factor de decaimiento que asigna la influencia en la volatilidad actual de la varianza del período anterior3. Como lo demuestran Guermant & Harris (2002), la estimación de la varianza condicional por el método del EWMA es un caso especial de un modelo de GARCH4 (Engle, 1982; Bollerslev, 1986). El modelo GARCH (1,1) para la varianza condicional de las rentabilidades viene dado por:
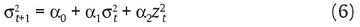
donde, α1 y α2 son parámetros que han de ser estimados5. Dado el supuesto de la distribución de las rentabilidades, las estimaciones de los parámetros del modelo (6) se pueden encontrar por medio del método de máxima verosimilitud.
Una forma más general del modelo GARCH, introducida por Ding, Granger & Engle (1993), es el modelo Asimetric Power ARCH (APARCH). Este captura la presencia de comportamientos asimétricos en la varianza condicional y tiene en cuenta el efecto deuda. La ecuación de la varianza para el modelo APARCH se define como:
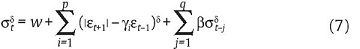
donde δ > 0 y -1< γj <1. Es importante tener en cuenta que si el valor de δ = 2 y γj =0, el modelo descrito en (7) es igual al (6).
]]> 2.2. Aproximación no paramétricaEsta aproximación no emplea ningún supuesto sobre la distribución de los rendimientos ni supone ningún tipo de comportamiento de los parámetros. Una de las aproximaciones no paramétricas más empleadas es la simulación histórica (SH), la cual implica emplear los retornos históricos para derivar el VaR por medio del percentil empírico de la distribución muestral. Lo anterior equivale a la siguiente expresión:
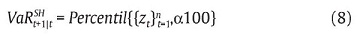
Es decir, la SH asume que la distribución de los rendimientos futuros es bien descrita por la distribución histórica de los rendimientos. Dado que no se supone ninguna distribución específica y que emplea las realizaciones de los rendimientos, este método tiene en cuenta posibles distribuciones no normales y colas pesadas. Sin embargo, no tiene en cuenta la posibilidad de una volatilidad condicional. Finalmente, es importante anotar que, si bien está aproximación aparentemente no implica supuesto alguno sobre la distribución de los rendimientos, de hecho si está suponiendo que la distribución es constante incluyendo su respectiva volatilidad.
2.3. Aproximación semiparamétrica
La aproximación paramétrica implica el supuesto crucial de la distribución de los rendimientos, pero permite considerar las innovaciones en la varianza. Por otro lado, la aproximación no paramétrica no necesita suponer una distribución, pero no permite actualizar la volatilidad. Existe una aproximación que permite combinar la aproximación paramétrica y no paramétrica denominada simulación historia filtrada propuesta por Hull & White (1998) y Barone-Adesi, Giannopoulos & Vosper (1999). Esta aproximación responde a los requerimientos de colas pesadas (ver Barone-Adesi & Giannopoulos [2001] para una discusión del tema) y actualización de la varianza. En este caso, el VaR es calculado como:
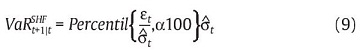
donde tanto εt y σt+1 son generados a partir de un modelo de comportamiento de la volatilidad, como por ejemplo un modelo GARCH (1,1) o APARCH(1,1).
2.4. Pruebas de Backtesting
Dentro de los resultados obtenidos se pueden encontrar 3 posibles escenarios. El primero, cuando el número de excepciones es menor que el nivel de confianza deseado (para el presente documento, 99%), en este caso, se estaría sobrestimando el riesgo o subestimando el VaR, y se estaría siendo muy conservador. Este es un resultado no deseado por una institución financiera dado que estarían teniendo una cobertura mayor a la deseada y se estaría dejando de utilizar recursos y de generar utilidades sobre ellos. El segundo escenario se presenta cuando se subestima el riesgo o se sobrestima el VaR; aquí la proporción de excepciones es mayor a la deseada y en el caso de que la institución financiera entre en insolvencia financiera no tendrá los recursos necesarios para cubrir sus necesidades. Por eso, lo ideal es encontrar las aproximaciones que tienen la cobertura igual al nivel de confianza deseado. Es decir, que ofrecen la cobertura adecuado al nivel de riesgo seleccionado por la institución financiera.
]]> Las pruebas de backtesting o de verificación le permiten al analista financiero saber si es buena la aproximación que está utilizando y si el modelo tiene la cobertura deseada. Los métodos más utilizados para determinar el comportamiento de diferentes formas de calcular el VaR son la prueba de Kupiec y de Christoffersen. Asimismo, el criterio de López permite escoger entre diferentes aproximaciones para encontrar la mejor aproximación para estimar el VaR.2.4.1. Prueba de Kupiec
Dado que la realización del VaR no es observable, se tienen que realizar varias consideraciones para evaluar las diferentes aproximaciones para estimar el VaR. La manera más intuitiva para comprobar la bondad del modelo propuesto será comprobar cuál es la proporción de períodos de la muestra en que se observa una pérdida superior a la predicción del modelo (es decir, superior al VaR). Dicha proporción debería ser en promedio igual al nivel de significancia. En otras palabras, el modelo debe proveer la cobertura no condicionada esperada por el diseño.
Para comprobar lo anterior, se calcula la proporción de excepciones (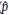 ) para cada una de las aproximaciones que son estimadas con el fin de evaluar la hipótesis nula de cobertura no condicional correcta ( = α); de esta forma, el estadístico de prueba de Kupiec (1995) corresponde a:
) para cada una de las aproximaciones que son estimadas con el fin de evaluar la hipótesis nula de cobertura no condicional correcta ( = α); de esta forma, el estadístico de prueba de Kupiec (1995) corresponde a:

donde N es el número total de predicciones. Kupiec (1995) demostró que ese estadístico sigue una distribución t con N-1 grados de libertad.
2.4.2. Prueba de Christoffersen
Christoffersen (1998) propuso otra forma de evaluar los pronósticos provistos por el VaR. Esta prueba parte de observar que si una aproximación para la estimación del VaR captura de manera precisa la distribución condicional de los retornos y sus propiedades dinámicas6, entonces, las excepciones deben ser impredecibles. La primera prueba realizada por Christoffersen mide la correcta cobertura condicional del modelo, con un estadístico de máxima verosimilitud que sigue una distribución Chi-cuadrado con 1 grado de libertad el cual se define como:
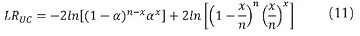
donde x es el número de excepciones en la muestra, n es el número de observaciones y α es la proporción esperada teóricamente. Ahora se prueba la independencia del modelo por medio del siguiente estadístico:
]]>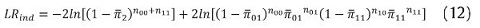
Este estadístico sigue una distribución Chi-cuadrado con un grado de libertad, donde nij es el número de veces en que el estado i-esimo es seguido del estado j-esimo, siendo cero el estado en el cual la pérdida del portafolio es menor que el VaR estimado, y 1 cuando el retorno actual es mayor que el VaR estimado7. Los valores de 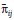 están dados por:
están dados por:
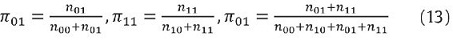
Finalmente, bajo la hipótesis de correcta cobertura e independencia y con una distribución Chi-cuadrado con 2 grados de libertad se calcula el siguiente estadístico:

2.4.3. El criterio de López
López (1998) propone evaluar la bondad de ajuste de las aproximaciones para estimar el VaR por medio de una función de pérdida y no por medio de una prueba estadística. En este caso, López (1998) sugiere tener en cuenta el tamaño de las desviaciones del VaR de la siguiente manera:
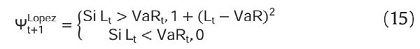
Así, esta función penaliza de mayor manera, al método en el que las excepciones sean más grandes. Siguiendo a López (1998) una aproximación de medición de riesgo será preferido si minimiza 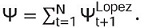
]]> 3. Muestra y diseño del ejercicio
En la sección anterior se describieron diferentes métodos para la estimación del VaR: i) Cinco métodos paramétricos (con supuesto de normalidad y con varianza constante, y con supuesto de normalidad con varianza no constante calculada por medio de MA, EWMA, GARCH [1,1] y APARCH [1,1]); ii) uno no paramétrico (SH), y iii) dos semiparamétricos (generados a partir de un modelo GARCH [1,1] y APARCH [1,1]). En esta sección se genera, para cada una de estas aproximaciones, la estimación del VaR para el siguiente día para portafolios representativos de 5 países latinoamericanos. En el presente ejercicio, el nivel de confianza que se emplea es del 99%.
Los datos empleados para comprobar estas aproximaciones corresponden a las rentabilidades diarias (continuas) desde el 7 de Marzo de 2001 hasta el 15 de octubre de 2010 para 5 índices de Bolsa de países latinoamericanos: Argentina, Brasil, Colombia, Chile y Perú con un tamaño de muestra igual a 2.292, 2.302, 2.271, 2.318 y 2.311 observaciones, respectivamente. En especial, los índices empleados corresponden, respectivamente a: MERVAL, BOVESPA, IGBC, IGPA y IGBVL. Dichos datos fueron obtenidos a partir de la base de datos de Reuters, omitiendo los fines de semana y festivos. El resumen estadístico se registra en la tabla 1.
Para los modelos de SH y paramétrico normal se emplean ventanas móviles que utilizan 250, 500, 750, 1.000 y todos los datos. Los demás modelos se calculan utilizando ventanas móviles que emplean la totalidad de los datos. En la tabla 2 se relacionan los modelos utilizados, en total 20, donde el cálculo se realiza generando la estimación del VaR fuera de la muestra para el período t+1, después la ventana se mueve para generar el siguiente pronóstico y así sucesivamente hasta generar un vector de 250 estimaciones.
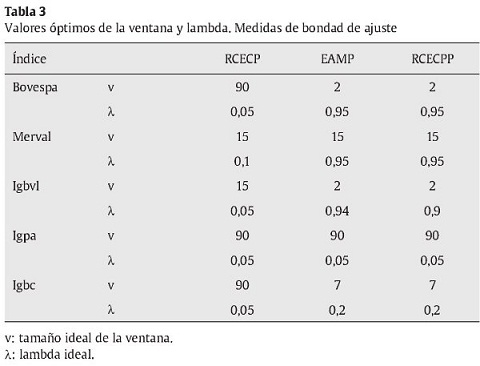
Para el caso específico de los modelos de media móvil y EWMA se utilizaron diferentes tamaños de ventana y valores de lambda para su estimación, después se escogió el tamaño ideal de estos valores empleando las 3 medidas de bondad de ajuste siguientes: RCECP, EAMP y RCECPP (ver Alonso & Berggrun [2010] para un detalle del procedimiento empleado). En la tabla 3 se reportan los valores óptimos obtenidos por medio de las 3 medidas.
4. Análisis de resultados
4.1. Análisis descriptivo
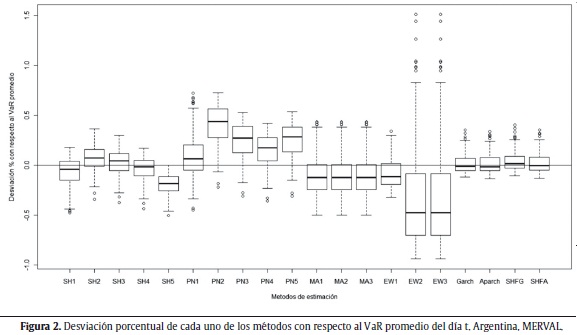
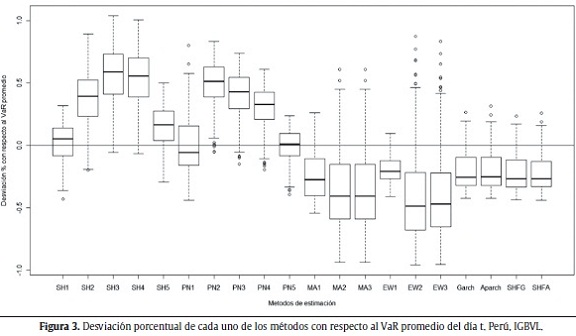
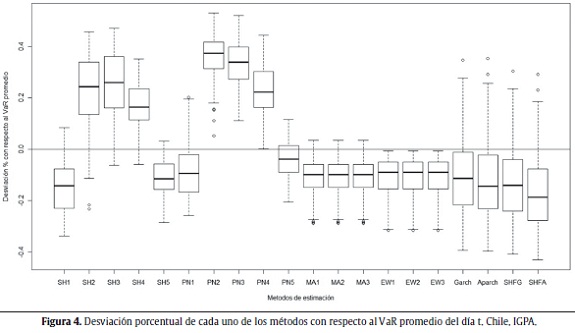
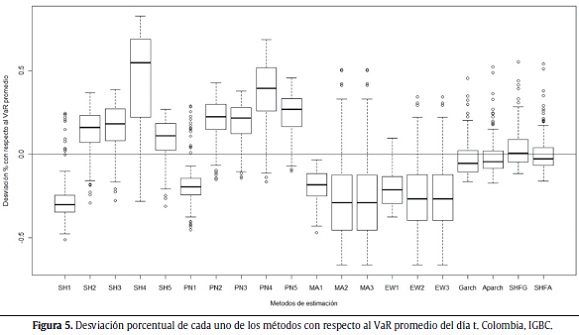
Las figuras 1 a 5 muestran la desviación porcentual de cada una de las aproximaciones (20 en total) con respecto al VaR promedio del día t. Es decir, para cada aproximación, se calculó la media de todos los VaR para el total de los 250 últimos períodos y con esta información se realiza el gráfico de cajas. La línea del centro de la caja representa el valor medio de las 250 estimaciones del VaR, el techo y base de la caja representan el cuartil superior e inferior de los datos. Las líneas verticales por fuera de la caja son 1,5 veces el tamaño de la caja y ayudan a identificar los outliers (puntos por fuera de las líneas).
]]>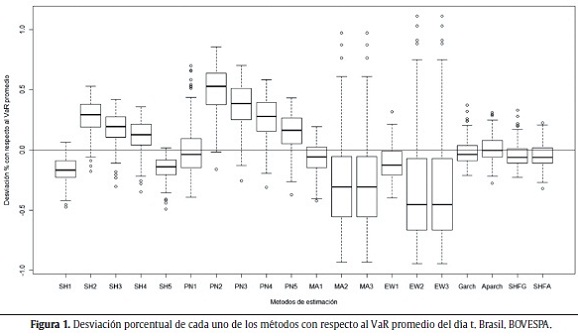
]]> Se esperaría obtener consistencia a través de las diferentes aproximaciones en los cálculos del VaR para un mismo índice. Es decir, al cambiar de aproximación no debería haber modificaciones grandes en el tamaño y ubicación de la caja, dado que se está estimando la misma cantidad con las diferentes aproximaciones y los datos son los mismos. Como se puede ver en las siguientes figuras, no parecería existir consistencia entre las aproximaciones para todos los índices. En otras palabras, para todos los casos considerados, las aproximaciones generan estimaciones del VaR que difieren sustancialmente entre ellas.
4.2. Análisis inferencial
Las tablas 4, 5, 6, 7, y 8 muestran los resultados para todas las 20 aproximaciones listadas anteriormente: las no paramétricas, las semiparamétricas y las paramétricas con varianza constante. Estos resultados se presentan para los siguientes índices de bolsas latinoamericanas, respectivamente: BOVESPA, MERVAL, IGVBL, IGPA e IGBC. En cada tabla se reportan los p-valores y estadísticos de las pruebas de Kupiec y de máxima verosimilitud de Christoffersen (correcta cobertura condicional (LRCC), independencia del modelo (LRind) y correcta cobertura e independencia (LRCC)) y la suma de la función de pérdidas de López. Las estrellas, al lado izquierdo de los estadísticos de prueba representan el nivel de confianza al cual se puede rechazar la hipótesis nula de correcta cobertura (condicional o no condicional) y el marcador  se encuentra del lado de la aproximación del VaR seleccionada que cuenta con la correcta cobertura condicional y no condicional correcta y minimiza la función de pérdidas de Lopez.
se encuentra del lado de la aproximación del VaR seleccionada que cuenta con la correcta cobertura condicional y no condicional correcta y minimiza la función de pérdidas de Lopez.
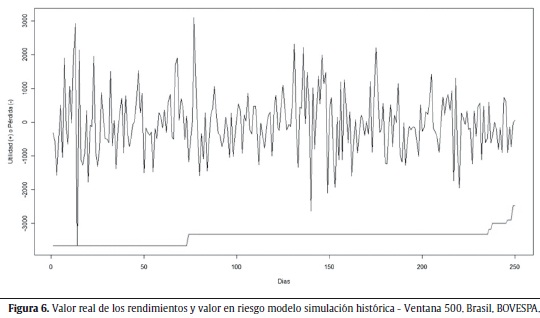
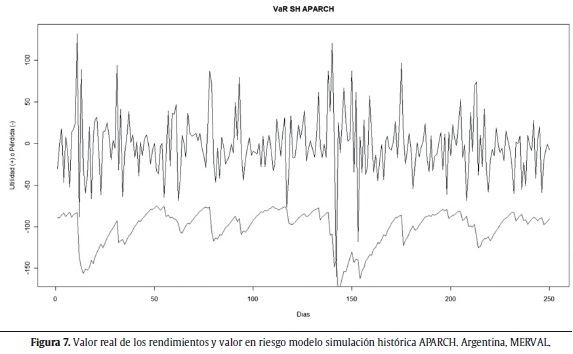
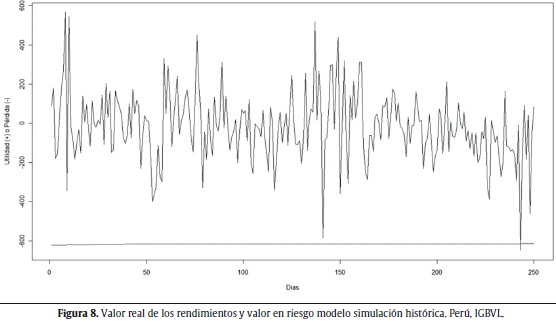
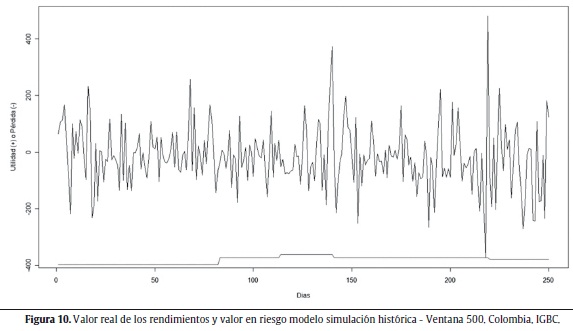
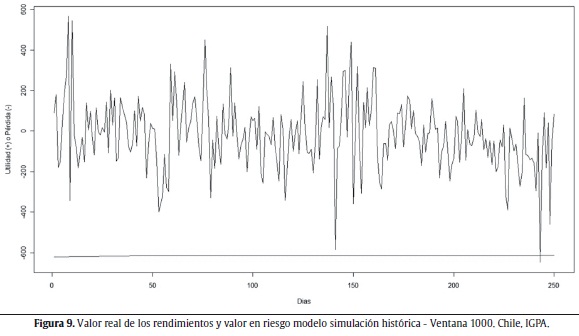
Las figuras 6 a 10 muestran los valores reales de los rendimientos y la aproximación del VaR seleccionada para cada uno de los índices de bolsas estudiados.
]]>
La tabla 4 muestra los resultados para el índice de Brasil (BOVESPA). Como se puede ver en esta tabla, para la aproximación APARCH (1,1) no se presentó ninguna excepción (no excepciones), esto quiere decir que el VaR calculado nunca tuvo un valor inferior al valor real del rendimiento a un nivel de confianza del 99%. Como se mencionó antes, este es un resultado no deseado dado que se está dando una cobertura mayor a la deseada. La aproximación seleccionada fue la de SH con una ventana móvil de 500 observaciones dado que cuenta con la correcta cobertura condicional y minimiza la suma función de pérdidas de López. La representación gráfica de esta aproximación se encuentra en la figura 6.
Para el caso del índice de Argentina (MERVAL) se seleccionó la aproximación semiparamétrica de SH a partir de un modelo APARCH (1,1). Es importante notar que para este caso no se obtuvieron aproximaciones en las cuales se sobrestimara el riesgo y para las cuales no existieran excepciones. La figura 7 muestra el valor real de los rendimientos del índice y el VaR para el modelo de SH APARCH.
El modelo de SH parece adaptarse bien para el caso de los índices de Perú (IGBVL) y Chile (IGPA) con una ventana móvil de todos los datos y 1.000 observaciones, respectivamente. Las figuras 8 y 9 muestran los resultados descritos.
Al igual que en el caso de Brasil, la aproximación seleccionada para el índice de Colombia (IGBC) es la de SH con una ventana móvil de 500 observaciones. Una observación importante para este caso es la presencia de 9 aproximaciones en las cuales no se presentan excepciones y, por lo tanto, no se obtiene la cobertura deseada sobrestimando el riesgo. La figura 10 muestra los resultados obtenidos bajo esta aproximación.
5. Comentarios finales
]]> Una de las tareas fundamentales en la gestión de riesgo es la medición de este. Si bien existen varias medidas de riesgo, tal vez la más popular y más empleada tanto por reguladores como por actores de los mercados financieros es el VaR. El VaR implica un concepto muy sencillo, pero su cálculo supone un reto para el back-office de las instituciones financieras.Este documento presenta un ejercicio para 5 países latinoamericanos en el que se evalúan 20 diferentes aproximaciones para estimar el VaR. Entre los resultados más destacables del ejercicio se encuentra que las estimaciones del VaR que proveen estos 20 métodos son relativamente muy diferentes para la misma muestra. Es decir, no existe una consistencia entre las estimaciones de cada una de las aproximaciones consideradas en el momento de estimar la misma cantidad: el VaR para el siguiente día de negociación.
Por otro lado, también se encontró la existencia de aproximaciones para las cuales no se presentan excepciones para la muestra considerada. Este es un resultado no deseable en una estimación del VaR dado que implica una estimación del VaR muy conservadora y, en términos de la institución financiera, se estarían haciendo provisiones más grandes que las necesarias. Un analista financiero, normalmente desea tener una cobertura igual a la esperada en el momento de construir su estimación del VaR (en el presente caso, igual al 99%). Esto significa que se esperaría que el VaR o pérdida máxima estimada fuera mayor a la pérdida real en un 1% de los casos. De lo contrario, no estaría siendo eficiente y tendría una cobertura superior.
Si se tiene en cuenta solo aproximaciones que tienen la cobertura correcta (tanto condicional como no condicional) y que presentan las excepciones que menos se desvían del valor realmente observado (criterio de López) se encuentra que para todos los países, a excepción de Argentina, el modelo de SH es seleccionado como el mejor. En el caso de Argentina, la mejor aproximación corresponde a la semiparamétrica, en la que se emplea la SH filtrada con el modelo APARCH (1,1).
Este último resultado tiene varias implicaciones interesantes. Primero, este resultado podría implicar que dado que el supuesto de normalidad de los datos no es válido para la muestra seleccionada de estos países, es preferible trabajar con la distribución que traen los datos (ver pruebas de normalidad en el resumen estadístico de la tabla 1).
Segundo, este resultado presenta un ejemplo muy interesante, en la medida en que, aun si una aproximación para calcular el VaR es sencilla, no se puede descartar que funcione bien para algunos casos. Este resultado demuestra que en algunos casos, un cálculo muy sofisticado no necesariamente mejora el desempeño de la estimación del VaR. Así, en el momento de escoger un método de estimación del VaR para una institución financiera, es sano contar con un gran arsenal de aproximaciones y evaluar cada una de ellas sin descartar alguna por su sencillez.
Finalmente, es importante tener en cuenta que estos resultados no son extrapolables a otras muestras, ya sea los mismos índices para otras muestras u otros índices accionarios. Así, el analista financiero encargado de encontrar la mejor aproximación para estimar el VaR tendrá que estar periódicamente evaluando diferentes aproximaciones para estimar el VaR.
Por otro lado, se sugiere que futuros ejercicios similares al realizado aquí tengan en cuenta la posibilidad de otros supuestos sobre la distribución de los rendimientos y regularidades en el comportamiento de los índices accionarios denominados efectos calendario. Por ejemplo, en el caso de los efectos calendario, podría incluirse el efecto del día de la semana que ha sido ampliamente documentado por autores como Cross (1973), French (1980), Gibbons & Hess (1981), Lakonishok & Levi (1982), Keim & Stambaugh (1984) y Rogalski (1984) para diferentes mercados de países de la Organización para la Cooperación y el Desarrollo Económico, y más recientemente documentado por Rivera (2009) para el caso colombiano. Este último tipo de adición a las aproximaciones del cálculo del VaR podría mejorar el desempeño sin necesidad de sofisticar mucho los métodos de estimación involucrados.
Notas
]]> 1 Ver, por ejemplo, a Cont (2001) y Alonso y Arcos (2005) para una discusión sobre los hechos estilizados de los rendimientos de un activo.2 Cuando las rentabilidades son leptocúrticas, el uso de una distribución normal subestima la probabilidad de las rentabilidades en los extremos; y por tanto, se generarán estimaciones del VaR que son, por lo general, muy pequeñas. Una opción es asumir que la distribución de los rendimientos sigue una distribución t.
3 JP Morgan emplea en su RiskMetrics® un λ de 0,94 para datos diarios y 0,97 para datos mensuales.
4 Del inglés, Generalized Autoregressive Condicional Heteroscedasticity.
5 Note que cuando α0 = 0 y α2 = 1-α2, esto reduce el GARCH(1.1) en el modelo EWMA y es conocido como un modelo GARCH integrado o IGARCH.
6 Condiciones tales como volatilidad variable a través del tiempo y la curtosis.
7 El estadístico LRc sigue una distribución Chi-cuadrado con 3 grados de libertad.
Bibliografía
Alonso, J. C. & Arcos, M. A. (2005). Cuatro Hechos Estilizados de las series de rendimientos: Una ilustración para Colombia. Mimeo. [ Links ]
Alonso, J. C. & Berggrun, L. (2010). Introducción al análisis de riesgo financiero. Colección Discernir. Serie Ciencias Administrativas y Económicas. Cali: Universidad Icesi. [ Links ]
Barone-Adesi, G. & Giannopoulos, K. (2001). Non-parametric VaR Techniques: Myths and Realities. Economic Notes, 30(2), 167-181. [ Links ]
Barone-Adesi, G., Giannopoulos, K. & Vosper, L. (1999). VaR without correlations for nonlinear Portfolios. Journal of Futures Markets, 19, 538-602. [ Links ]
Bollerslev, T. (1986). Generalized autoregressive conditional heteroscedasticity. Journal of Econometrics, 31, 307-327. [ Links ]
Christoffersen, P. (1998). Evaluating interval forecasts. International Economic Review, 39, 841-862. [ Links ]
Cont, R. (2001). Empirical Properties of Asset Returns: Stylized Facts and Statistical Issues. Quantitative Finance, 1(2), 223-236. [ Links ]
Cross, F. (1973). The behavior of stock prices on fridays and mondays. Financial Analyst Journal, 67-69. [ Links ]
Ding, Z., Granger C. W. J. & Engle, R. F. (1993). A Long Memory Property of Stock Market Returns and a New Model. Journal of Empirical Finance, 1, 83-106. [ Links ]
Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of United Kindom inflation. Econometrica, 31, 987-1007. [ Links ]
French, K. (1980). Stock returns and the weekend effect. Journal of Financial Economics, 8, 55-69. [ Links ]
Gibbons, M., & Hess, P. (1981). Day of the week effects and asset returns. Journal of Business, 54, 579-596. [ Links ]
Guermat, C. & Harris, R. (2002). Forecasting value at risk allowing for time variation in the variance and kurtosis of portfolio returns. International Journal of Forecasting, 18, 409-419. [ Links ]
Hull, J. & White, A. (1998.). Incorporating volatility updating into the historical simulation method for VaR. Journal of Risk, 1, 5-19. [ Links ]
Keim, D. B. & Stambaugh, F. (1984). A further investigation of weekend effects in stock returns. Journal of Finance, 819-840. [ Links ]
Kupiec, P. H. (1995). Techniques for verifying the accuracy of risk measurement models. The Journal of Derivatives, 3, 73-84. [ Links ]
Lakonishok, J. & Levi, M. (1982). Weekend effect in stock return: a note. Journal of Finance, 37, 883-889. [ Links ]
López, J. A. (1998). Methods for evaluating Value-at-Risk estimates. Federal Reserve Bank of New York. Economic Policy Review, (2), 3-17. [ Links ]
Rivera, D. M. (2009). Modelación del efecto del día de la semana para los índices accionarios de Colombia mediante un modelo Star Garch. Revista de Economía del Rosario, 12, 1-24. [ Links ]
Rogalski, R. J. (1984). New findings regarding day-of-the-week returns over trading and non-trading periods: a note. Journal of Finance, 1603-1614. [ Links ]
]]>