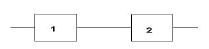 ]]>
Figura 1. Sistema con dos componentes en serie.
]]>
Figura 1. Sistema con dos componentes en serie. Figure 1. A system with two components in series.
CONCURRENTES A STUDY OF THE INFERENCE EFFECT CAUSED BY THE DEPENDENCE BETWEEN TWO COMPETING FAILURE MODES ON THE ESTIMATION OF THE RELIABILITY FUNCTION
EVA MANOTAS
Escuela de Estadística, Universidad Nacional de Colombia, Profesor Asistente, ecmanota@unal.edu.co
SERGIO YÁÑEZ
Escuela de Estadística, Universidad Nacional de Colombia, Profesor Asociado, syanez@unal.edu.co
CARLOS LOPERA
Escuela de Estadística, Universidad Nacional de Colombia, Profesor Asistente, cmlopera@unal.edu.co
MARIO JARAMILLO ]]> Escuela de Estadística, Universidad Nacional de Colombia, Profesor Asociado, mcjarami@unal.edu.co
Recibido para revisar Junio 22 de 2007, aceptado Noviembre 11 de 2007, versión final Noviembre 16 de 2007
RESUMEN: La metodología tradicional asume independencia entre los modos de falla concurrentes (competing risks) para la estimación de la funcion de confiabilidad, pero estudios recientes advierten sobre los posibles errores de estimación que dicho supuesto conlleva, cuando realmente existe dependencia entre los modos de falla. Este artículo pretende, a través de un estudio de simulación, explorar el efecto causado por dicha situación, en los casos de dos modos de falla lognormales y de dos modos de falla Weibull. De los resultados se aprecia que cuando la dependencia es ignorada, no hay diferencia significativa entre la función de confiabilidad verdadera y la función de confiabilidad estimada asumiendo independencia.
PALABRAS CLAVE: Función de confiabilidad, fallas concurrentes, competing risks, distribución del tiempo mínimo, lognormal bivariada, Weibull bivariada, parámetro de dependencia.
ABSTRACT: The traditional methodology assumes independence between competing failure modes to estimate the reliability function, but recent studies have shown that when this assumption is incorrectly assumed, usually gives pessimistic estimates. This paper intends, through a simulation study, to explore the effect caused by such a situation in the cases of two competing lognormal failures and two competing Weibull failures. It is appreciated from the results that, when the dependence is ignored, there are no significant differences between the true reliability function and the estimated reliability function assuming independence.
KEYWORDS: Reliability fuction, competing failures, minimum time distribution, lognormal bivariate, Weibull bivariate, dependence parameter.
1. INTRODUCCIÓN
]]> Las causas o las diferentes manera en que puede fallar un sistema o componente, reciben el nombre de modos de falla. Existen muchos sistemas, subsistemas y componentes que tienen más de un modo de falla; y en ciertas aplicaciones y para algunos propósitos es importante distinguir entre esos diferentes modos de falla (tipos o causas de falla), con el objeto de mejorar la confiabilidad (Meeker y Escobar, 1998).El tiempo de falla de un sistema con varios modos de falla puede ser modelado considerando un sistema en serie o un modelo de Competing Risks, donde cada modo de falla es una componente del sistema en serie, y cada componente tiene un tiempo de vida aleatorio, por lo tanto el sistema fallará cuando el modo de falla con el tiempo de vida más corto falle.
La dependencia para este tipo de problemas ha venido cobrando gran importancia. Crowder (2001), describe la importancia de la temática, no solamente para los temas demográficos y actuariales sino también desde el punto de vista de la inferencia estadística y las aplicaciones a la teoría de la confiabilidad y el análisis de supervivencia. Denuit et al, (2005), es otro ejemplo de la importancia actual del tema. Ver también Bedford (2005), y Nelsen (1999), que muestran la relación entre dependencia en modelos multivariados, competing risks y el trabajo en cópulas.
Por un largo tiempo, la modelación estadística en este tipo de problemas ha utilizado el supuesto de independencia. Este supuesto es matemáticamente conveniente, ya que la independencia puede ser definida de manera única, mientras que la dependencia puede ser formulada de muchas maneras. En muchas situaciones prácticas la dependencia es una condición usual, lo que ha generado el creciente interés por su estudio.
El problema clásico de competing risks es identificar las distribuciones marginales de los tiempos de falla asociados a los modos de falla a partir de datos de la forma (T,C), donde T es un tiempo de falla y C es la causa de falla. Tsiatis (1975) mostró que las distribuciones marginales y la distribución conjunta de dos riesgos que concurren, son en general no identificables, esto es, hay muchas funciones de distribución conjuntas diferentes que comparten las mismas funciones de sub-distribución.
Este estudio pretende explorar el efecto en la estimación de la confiabilidad, cuando se asume el supuesto de independencia entre tiempos de falla concurrentes que realmente son dependientes. Para ello se simulan tiempos de falla bivariados Weibull y lognormales, y se estima la confiabilidad conjunta asumiendo independencia. Los resultados no muestran diferencias significativas en la estimación de la función de confiabilidad.
2. CONFIABILIDAD EN SISTEMAS CON DOS MODOS DE FALLA
El tiempo de falla de un sistema con dos modos de falla puede ser modelado como un sistema en serie o un modelo de competing risk, como se ilustra en la figura 1. Cada unidad tiene un tiempo potencial de falla asociado a cada modo de falla. El tiempo de falla observado es el mínimo de esos tiempos potenciales individuales.
]]>
Figura 1. Sistema con dos componentes en serie.
Figure 1. A system with two components in series.
Así por ejemplo para un sistema con dos modos de falla, sean T1 y T2 los respectivos tiempos potenciales, y el tiempo de falla observado es
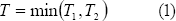
De esta manera en la práctica sólo se observa el mínimo entre T1 y T2 pero se conoce cual es el modo de falla. Así los datos tienen la siguiente forma
Tabla 1. Forma de los Datos del Tiempo Mínimo de dos Modos de Falla Concurrentes.
Table 1. Data form of Minimum Failure Time between Two Competing Failure Modes.
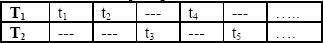
Observe que para este tipo de datos, no es posible estimar la medida de dependencia o de asociación entre las variables.
Para estimar lo parámetros y la distribución asociada a los tiempos de un modo de falla, los tiempos del otro modo de falla son tiempos de censura. Por ejemplo si T2 < T1, entonces T1 está censurado en el tiempo T2, es decir, no se observa. La censura es informativa y no puede ser ignorada.
]]> Los sistemas considerados en este estudio son no reparables, es decir, cada unidad que falla es reemplazada por una nueva, en este sentido se considera que el sistema sigue operando tan bueno como nuevo (Raussand y Hoyland, 2004). 2.1 Sistemas con Componentes en Serie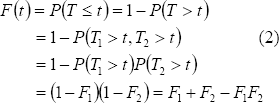
Donde Fi es la función de distribución para cada componente y Ti es el tiempo de vida asociado a cada componente, i = 1, 2, y T= min (T1 ,T2) es el tiempo de falla observado del sistema.
La función de confiabilidad S(t) = 1-F(t), de donde para el caso de independencia
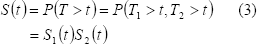
Para un sistema con dos componentes en serie y tiempos de falla dependientes
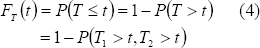
En este caso la evaluación debe hacerse con respecto a la distribución bivariada de T1 y T2, que debe incluir el parámetro de dependencia.
La función de confiabilidad para este caso es
]]>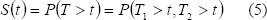
Una cantidad de gran interés en aplicaciones de confiabilidad es la vida media de un sistema, también conocida como tiempo medio para la falla. Se denota MTTF por sus siglas en inglés (mean time to failure) y se calcula así
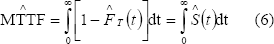
En un hospital se presentaba la siguiente situación: Cierto tipo de equipos, estaban fallando antes del tiempo estipulado para su mantenimiento. Se identificaron dos causas de falla de los equipos, una asociada a fallas por descargas eléctricas (se denota S), y la otra falla debida al desgaste de los equipos (se denota W).
La tabla 2 presenta los tiempos de falla de 30 unidades que fueron instaladas en un ambiente de servicio estándar. Se determinó la causa de falla para cada unidad que falló. El modo de falla S fue causado por acumulación de daños producidos por altos picos de voltaje durante tormentas eléctricas, resultando en falla de una componente electrónica desprotegida. Estas fallas predominaron temprano en la vida de los dispositivos. El modo de falla W, es producido por el desgaste normal de los equipos, y empieza a aparecer después de 100000 ciclos de uso.
Tabla 2. Tiempos de Falla y Modos de Falla para los Equipos de Rayos X que Fallaron y Tiempos de Funcionamiento de las Unidades que No Han Fallado.
Table 2. Failure Times and Failure modes of X Ray that Failed and Running Times for Units that Did Not Fail.
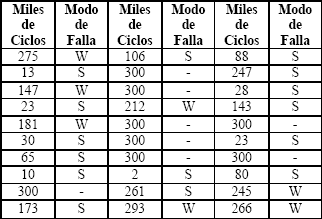
Para cada modo de falla se observa un buen ajuste Weibull, realizando el análisis como se describió en la sección 2, esto es, por ejemplo para el modo S, las fallas debidas al modo W se consideran tiempos de censura
]]> En la figura 2 las líneas discontinuas corresponden a los gráficos de probabilidad Weibull estimados con máxima verosimilitud para los dos modos de falla individuales. En este ejemplo, la suposición de independencia entre los dos modos de falla concurrentes es aceptable de manera que se puede aplicar el enfoque tradicional. Así de acuerdo con (2) F(t) se puede estimar así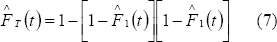
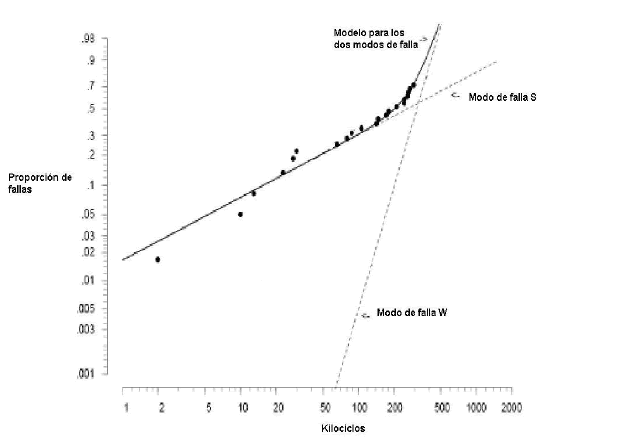
Figura 2. Análisis Weibull de los datos estimado para las fallas del Modo S, fallas del Modo W y distribución del tiempo mínimo entre el Modo S y el Modo W.
Figure 2. Weibull analysis of data estimating time to failure Mode S only, failure Mode W only and the distribution to the minimum of Mode S and Mode W.
En la figura 2, la línea curva corresponde a la función de distribución estimada 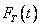 del sistema en serie para dos modos de falla actuando juntos, es decir concurrentes. La estimación del tiempo medio para la falla, MTTF, fue calculada usando (6) y se obtuvo 196 mil ciclos, esta cantidad se usa para el montaje del programa de mantenimiento preventivo.
del sistema en serie para dos modos de falla actuando juntos, es decir concurrentes. La estimación del tiempo medio para la falla, MTTF, fue calculada usando (6) y se obtuvo 196 mil ciclos, esta cantidad se usa para el montaje del programa de mantenimiento preventivo.
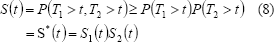
Para este ejemplo, se observa que los tiempos de falla entre 150000 y 300000 ciclos presentan una posible dependencia. Bajo este supuesto hipotético en la sección 4.3 se calculan los MTTF cambiando el parámetro de dependencia para ilustrar los resultados del estimador que se describe a continuación.
]]> 3. ESTUDIO DEL EFECTO DE LA DEPENDENCIA POSITIVA ENTRE TIEMPOS DE FALLA EN LA ESTIMACIÓN DE LA CONFIABILIDAD DE UN SISTEMA CON DOS MODOS DE FALLA CONCURRENTES.
Para modos de falla concurrentes con dependencia positiva se sabe que (Barlow y Proschan, 1975),
Donde 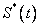 es la función de confiabilidad asumiendo independencia. Por lo tanto es pesimista en relación con
es la función de confiabilidad asumiendo independencia. Por lo tanto es pesimista en relación con 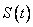 , esto es para un mismo tiempo t, la probabilidad de sobrevivencia bajo el supuesto de independencia está siempre por debajo de la probabilidad conjunta que incluye la dependencia.
, esto es para un mismo tiempo t, la probabilidad de sobrevivencia bajo el supuesto de independencia está siempre por debajo de la probabilidad conjunta que incluye la dependencia.
En la práctica hay que estimar S(t) y S*(t) por lo cual el resultado probabilístico en (8) no se satisface necesariamente.
Este estudio pretende explorar el efecto en la estimación de la confiabilidad del sistema, cuando se asume el supuesto de independencia entre tiempos de falla concurrentes que realmente son dependientes. Para ello se compara la función de confiabilidad verdadera S(t), para distintos valores del parámetro de dependencia entre las variables, con un estimador de S*(t) que se denota 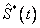 . Este es un estimador de la función de confiabilidad del tiempo mínimo de falla de un sistema con dos modos de falla concurrentes, obtenido estimando los parámetros asociados a cada modo de falla individual, como se explicó en la sección 2, para estimar lo parámetros y la distribución asociada a los tiempos de un modo de falla, los tiempos del otro modo de falla son tiempos de censura. Así
. Este es un estimador de la función de confiabilidad del tiempo mínimo de falla de un sistema con dos modos de falla concurrentes, obtenido estimando los parámetros asociados a cada modo de falla individual, como se explicó en la sección 2, para estimar lo parámetros y la distribución asociada a los tiempos de un modo de falla, los tiempos del otro modo de falla son tiempos de censura. Así
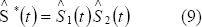
donde 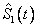 y
y 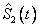 son las funciones de confiabilidad marginales estimadas para cada modo de falla. Es importante reiterar que el interés del estudio es sobre el estimador de la confiabilidad del sistema, y no sobre los estimadores de las marginales; bajo dependencia se sabe que
son las funciones de confiabilidad marginales estimadas para cada modo de falla. Es importante reiterar que el interés del estudio es sobre el estimador de la confiabilidad del sistema, y no sobre los estimadores de las marginales; bajo dependencia se sabe que 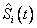 no es un buen estimador de
no es un buen estimador de 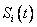 (Crowder, 2001).
(Crowder, 2001).
Para ello utilizaremos un estudio de simulación cuyo esquema se describe a continuación.
Esquema de SimulaciónSe chequearon las probabilidades P(T1<T2) y los valores obtenidos indican que en todos los casos se tienen probabilidades que garantizan la pertinencia del esquema de simulación. Se observo que dichas probabilidades son mayores o iguales que 0.30 lo que garantiza que al simular se tienen datos de los dos modos de falla.
Para efectos de comparación se obtienen los intervalos de confianza boostrap percentil del 95% para S*(t) y la MTTF de la función de confiabilidad verdadera y de la función de confiabilidad estimada.
Caso Lognormal
Para generar tiempos de falla lognormales bivariados con coeficiente de correlación 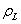 , se generan normales bivariadas con coeficiente de correlación
, se generan normales bivariadas con coeficiente de correlación 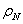 , donde está definido
, donde está definido
mediante la siguiente relación:
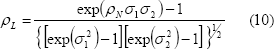
y luego se sacan exponenciales a cada uno de los tiempos normales bivariados.
Se consideran 24 escenarios con tiempos de falla lognormales, cada uno de los cuales corresponde a la llamada función de confiabilidad verdadera, S(t), para la cual se supone se conocen los parámetros verdaderos (i.e. no hay que estimarlos).
Los casos de tiempos lognormales son:
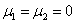 y
y 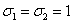 .
. 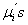 iguales y
iguales y 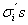 diferentes: ,
diferentes: , 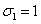 y
y 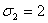 .
.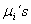 diferentes y
diferentes y 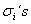 iguales:
iguales: 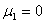 y
y 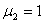 ,
,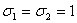 .
.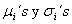 diferentes: y , y .
diferentes: y , y .Asociados a cada uno de estos casos hay 6 situaciones diferentes de acuerdo al parámetro de dependencia entre los tiempos de falla. Para tiempos de falla lognormales T1 y T2, el parámetro de dependencia es el coeficiente de correlación ρN entre log(T1) y log(T2), y éste toma los siguientes valores: ρN = 0.0, 0.2, 0.4, 0.6, 0.8, 1.0. Es decir para cada uno de los 4 casos de tiempos lognormales hay 6 situaciones distintas que van desde independencia hasta dependencia extrema. Lo que da un total de 24 escenarios, para los cuales estimaremos.
Como el objetivo primordial es medir el efecto de la dependencia, en la escogencia de los escenarios se tuvo en cuenta lo siguiente: Para el caso 1, las medias y varianzas son iguales, es decir los factores de posición y escala están controlados. En el caso 2, se analiza el efecto del factor de escala sobre el coeficiente de correlación. El caso 3, el efecto del factor de posición y en el caso 4 el efecto conjunto de los dos factores. En síntesis estos escenarios representan apropiadamente, las distintas alternativas de una lognormal bivariada, con relación al problema de interés, que en este caso es el coeficiente de correlación.
Caso Weibull
Para simular los tiempos de falla Weibull bivariados se usó el algoritmo cópula compuesta de la Gumbel-Hougaard (Frees y Valdez, 1997). La función de confiabilidad conjunta de la Weibull bivariada utilizada es (Lu y Bhattacharyya, 1990)
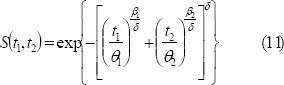
En este trabajo se usa como parámetro de dependencia entre tiempos de falla Weibull, T1 y T2,, a λ=1-δ, de manera que 0≤λ<1. Cuando λ es cero, entonces hay independencia entre T1 y T2. A medida que λ, aumenta, la dependencia entre T1 y T2, aumenta.
Se consideran 30 escenarios con tiempos de falla Weibull, cada uno de los cuales corresponde a la llamada función de confiabilidad verdadera, S(t).
Los parámetros de escala de la distribución Weibull bivariada se fijan en θ1 = θ2 = 1.0, ya que el parámetro de dependencia λ, no depende del parámetro de escala (Lu y Bhattacharyya, 1990). La elección de escenarios cubre una amplia gama de formas de la distribución Weibull bivariada, donde los modos de falla entran en competencia. Los escenarios presentan situaciones donde compiten distribuciones Weibull con tasas de falla decrecientes y crecientes. Cuando el parámetro β<1, la tasa de falla es decreciente, y cuando β>1, la tasa de falla es creciente. Esta flexibilidad de la distribución Weibull de adaptarse a diferentes tasas de falla, la hacen modelo adecuado en muchas aplicaciones prácticas. Por ello los escenarios toman como base las distintas combinaciones posibles de dicha tasa.
Los casos de tiempos Weibull a estudiar son:
En cada uno de los escenarios se toman valores del parámetro de dependencia: l=0.0, 0.2, 0.4, 0.6, 0.8, 0.9. De manera que en total se tiene 30 escenarios distintos para la distribución Weibull bivariada. En síntesis estos escenarios representan apropiadamente, las distintas alternativas de una Weibull bivariada, con relación al problema de interés, que en este caso es el parámetro de dependencia l.
4. ANÁLISIS DE RESULTADOS
Los resultados para modos de falla Weibull y lognormales son similares, por lo cual se reportan solo los resultados asociados a los casos Weibull.
4.1 Intervalos de Confianza para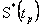
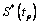 , con 10000 réplicas del estimador
, con 10000 réplicas del estimador 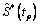 , para p=0.05, 0.25, 0.50, 0.75 y 0.95. De esta manera se obtienen bandas de confianza aproximadas del 95%.
, para p=0.05, 0.25, 0.50, 0.75 y 0.95. De esta manera se obtienen bandas de confianza aproximadas del 95%. Las figuras 3, 4 y 5, muestran los bandas de confianza para el caso Weibull β1=0.5 y β2=2, y parámetros de dependencia l=0.0, 0.6 y 0.9 respectivamente. En estos gráficos, para cada uno de los percentiles del tiempo mínimo, 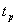 con p=0.05, 0.25, 0.5, 0.75 y 0.95 se tiene el valor verdadero de
con p=0.05, 0.25, 0.5, 0.75 y 0.95 se tiene el valor verdadero de 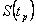 , el límite inferior de
, el límite inferior de  (denotado como LI. ) y el límite superior de (denotado como LS. ). La línea continua une los valores de , la línea discontinua que está por debajo de la línea continua, une los valores de los límites inferiores de la estimación de
(denotado como LI. ) y el límite superior de (denotado como LS. ). La línea continua une los valores de , la línea discontinua que está por debajo de la línea continua, une los valores de los límites inferiores de la estimación de 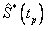 . Y la línea discontinua, que está por encima de la línea continua, une los valores de los límites superiores de la estimación de . De esta manera se obtienen las bandas de confianza aproximadas.
. Y la línea discontinua, que está por encima de la línea continua, une los valores de los límites superiores de la estimación de . De esta manera se obtienen las bandas de confianza aproximadas.
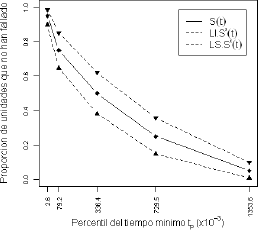
Figura 3. Intervalos de confianza bootstrap para el caso Weibull β1=0.5, β2=2 y l=0.0, en los percentiles tp con p=0.05, 0.25, 0.50, 0.75, y 0.95.
Figure 3. Confidence bounds for Weibull β1=0.5, β2=2 and l=0.0, in quantiles tp with p=0.5, 0.25, 0.50, 0.75 y 0.95.
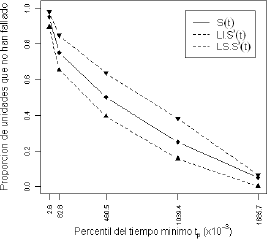
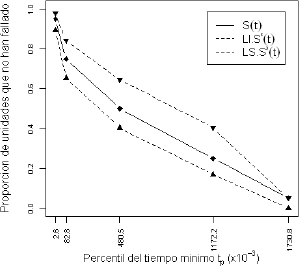
Figura 5. Intervalos de confianza bootstrap para el caso Weibull β1=0.5, β2=2 y l=0.9, en los percentiles tp con p=0.05, 0.25, 0.50, 0.75, y 0.95.
Figure 5. Confidence bounds for Weibull β1=0.5, β2=2 and l=0.9 in quantiles tp with p=0.5, 0.25, 0.50, 0.75 y 0.95.
Así por ejemplo, en la figura 4, para 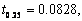
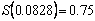 , LI.=0.6534 y LS. =0.8468. Observe que el valor verdadero de , cae dentro de las bandas de confianza, lo que permite afirmar que no hay diferencia significativa entre y .
, LI.=0.6534 y LS. =0.8468. Observe que el valor verdadero de , cae dentro de las bandas de confianza, lo que permite afirmar que no hay diferencia significativa entre y .
La figura 6 muestra el diagrama de box plot para el caso Weibull β1=0.5 y β2=2, y parámetro de dependencia l=0.6. Este gráfico muestra la variabilidad del estimador 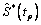 , y en él, para cada uno de los percentiles del tiempo mínimo, con p=0.05, 0.25, 0.5, 0.75 y 0.95 se tiene el valor verdadero de representado por una equis (x). Los casos l=0.0 y l=0.9 se comportan de manera similar.
, y en él, para cada uno de los percentiles del tiempo mínimo, con p=0.05, 0.25, 0.5, 0.75 y 0.95 se tiene el valor verdadero de representado por una equis (x). Los casos l=0.0 y l=0.9 se comportan de manera similar.
Así por ejemplo, en la figura 6 para 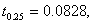 se observa que el valor verdadero de ,
se observa que el valor verdadero de , 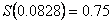 , denotado por una equis (x), se encuentra dentro de la caja y muy próximo a la mediana de .
, denotado por una equis (x), se encuentra dentro de la caja y muy próximo a la mediana de .
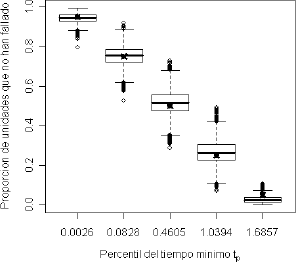 ]]>
Figura 6. Diagrama de caja y bigotes para el caso Weibull β1=0.5, β2=2 y l=0.6, en los percentiles tp con p=0.05, 0.25, 0.50, 0.75, y 0.95.
]]>
Figura 6. Diagrama de caja y bigotes para el caso Weibull β1=0.5, β2=2 y l=0.6, en los percentiles tp con p=0.05, 0.25, 0.50, 0.75, y 0.95.
Figure 6. Box plot for Weibull β1=0.5, β2=2 and l=0.6 in quantiles tp with p=0.5, 0.25, 0.50, 0.75 y 0.95.
Los demás escenarios se comportan de manera similar.
Esto muestra el buen comportamiento del estimador 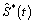 aún en presencia de valores altos del parámetro de dependencia l. Se puede entonces afirmar que no hay diferencia significativa entre S(t) y , que equivale a aceptar la hipótesis nula S(t)= para todo t.
aún en presencia de valores altos del parámetro de dependencia l. Se puede entonces afirmar que no hay diferencia significativa entre S(t) y , que equivale a aceptar la hipótesis nula S(t)= para todo t.
4.2 MTTF
Para cada uno de los escenarios de estudio, se obtuvieron 1000 estimaciones de la MTTF para la función de confiabilidad estimada asumiendo independencia entre los tiempos de falla, y se promediaron para comparar con la MTTF de la función de confiabilidad verdadera. Se obtuvieron también los intervalos de confianza bootstrap percentil para el promedio de la MTTF estimada.
La tabla 3 muestra los resultados para el caso Weibull con β1=0.5 y β2=2. Esta tabla presenta para cada uno de los valores del parámetro de dependencia λ=0.0, 0.2, 0.4, 0.6, 0.8 y 0.9, los valores de la MTTF estimada promedio, la MTTF real y el límite inferior (denotado LI.MTTF) y límite superior (denotado LS.MTTF) del intervalo de confianza bootstrap percentil del 95% para la MTTF estimada promedio.
Tabla 3. MTTF Real, MTTF Estimada Promedio e Intervalos de Confianza para MTTF Estimada.
Table 3. Actual MTTF, Average Estimated MTTF and Confidence Intervals for Average Estimated MTTF. ]]>
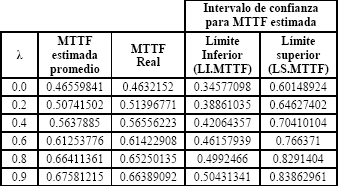
No se observa diferencia significativa entre la MTTF estimada promedio y la MTTF real. Por ejemplo para 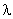 =0.4, las MTTF se confunden pues sus valores son: la MTTF estimada promedio es 0.5637885 y la MTTF real es 0.56556223. El límite inferior del intervalo de confianza para la MTTF estimada es
=0.4, las MTTF se confunden pues sus valores son: la MTTF estimada promedio es 0.5637885 y la MTTF real es 0.56556223. El límite inferior del intervalo de confianza para la MTTF estimada es 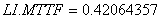 y el límite superior es
y el límite superior es 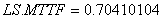 . Observe que el valor de la MTTF real cae dentro de los intervalos de confianza.
. Observe que el valor de la MTTF real cae dentro de los intervalos de confianza.
Los resultados de la tabla 3 son ilustrados en la figura 7. En este gráfico, para cada uno de los valores del parámetro de dependencia λ=0.0, 0.2, 0.4, 0.6, 0.8 y 0.9, se tiene el valor verdadero de la MTTF (MTTF.Real), el valor de la MTTF estimada promedio (MTTF.Mean), el límite inferior de la MTTF estimada promedio (denotado como LI.MTTF) y el límite superior de la MTTF estimada promedio (denotado como LS.MTTF). La línea continua une los valores de la MTTF.Mean, la línea discontinua que está por debajo de la línea continua, une los valores de los límites inferiores de la estimación de la MTTF.Mean, y la línea discontinua, que está por encima de la línea continua, une los valores de los límites superiores de la estimación de la MTTF.Mean. El valor de la MTTF.Real está representado por una cruz (+). De esta manera se obtienen las bandas de confianza aproximadas para la MTTF.Mean.
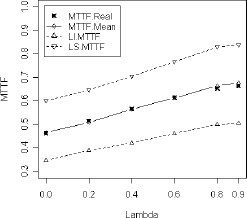
Figura 7. MTTF para el caso Weibull β1=0.5 β2=2, contra distintos valores del parámetro de dependencia l.
Figure 7. Mean time to failure for Weibull β1=0.5 β2=2 vs diferents dependence parameter values l.
Observe que la MTTF real cae dentro del intervalo de confianza. Esto permite afirmar que no hay diferencia significativa entre la MTTF estimada promedio y la MTTF real, y es equivalente a aceptar la hipótesis nula MTTF.Real = MTTF.Mean.
Similares resultados se tienen en los otros escenarios de simulación.
4.3 Ilustración. Luego como en la subsección 4.2 se compararon la MTTF verdadera con la MTTF estimada. Los resultados son ilustrados en la figura 8.
]]>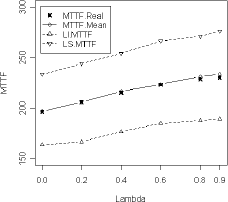
Observe que la MTTF real cae dentro del intervalo de confianza, lo cual reafirma el resultado de igualdad entre la MTTF estimada y la MTTF real.
5. CONCLUSIONES
Para los casos estudiados se puede afirmar que es un estimador relativamente robusto de S(t), respecto al supuesto de independencia. Así, a pesar de la dependencia entre los dos modos de falla, se tiene que el supuesto clásico de independencia de la metodología tradicional no genera errores significativos en la estimación de la función de confiabilidad del tiempo mínimo.
En la literatura reciente se ha reportado (Bedford, 2005; Denuit et al, 2005) que el supuesto de independencia en riesgos concurrentes (competing risks) generalmente da una visión pesimista del comportamiento del sistema, en la medida que el tiempo de supervivencia tiende a ser más pequeño que cuando hay dependencia. En este artículo, para los casos lognormal y Weibull de gran importancia práctica, se mostró que tal comportamiento no aplica, lo cual amerita a futuro la exploración de las propiedades del estimador .
6. AGRADECIMIENTOS
]]> Los autores agradecen a los evaluadores por sus observaciones y valiosas sugerencias.De manera muy especial agradecen al Profesor Luis Alberto Escobar, de Louisiana State University, por su asesoría, apoyo y colaboración en este trabajo.
REFERENCIAS
[1] BARLOW, R.E, Y PROSCHAN, F. Statistical Theory of Reliability and Life Testing. New York: Holt, Richard Winston, 1975. [ Links ]
[2] BEDFORD, T. Competing Risk Modeling in Reliability. Chapter 1. Modern Statistical and Mathematical Methods in Reliability. Singapore: World Scientific Publishing Co, 2005. [ Links ]
[3] CROWDER, M. Classical Competing Risks. Chapman Hall/CRC. 2001. [ Links ]
[4] DENUIT, M. DHAENE, J. GOOVAERTS, M and KAAS, R. Actuarial Theory for Dependent Risks. Measures, Orders and Models. Great Britain : John Wiley & Sons, 2005. [ Links ]
[5] FREES, E AND VALDES, E. Understanding Relationships Using Copulas. North America Actuarial Journal, Volume 2, Number 1, 1997. [ Links ]
[6] LU, JYE-CHYI and BHATTACHARYYA, G., Some New Constructions Of Bivariate Weibull Models. Ann. Inst. Statist. Math. Vol 42, No. 3, p: 543-559. 1993. [ Links ]
[7] MEEKER, W. Y ESCOBAR, L.A. Statistical Methods for Reliability Data. John Wiley & Sons, 1998. [ Links ]
[8] NELSEN, R. B. An Introduction to Copulas. New York: Springer, 2006. [ Links ]
[9] RAUSAND, M. AND HOYLAND, A. System Reliability Theory. John Wiley & Sons, 2004. [ Links ]
[10] TSIATIS, A. A nonidentifiability aspect of the problem of competing risks. Proc. Natl. Acad. Sci. USA. 72, 20-22. 1975. [ Links ] ]]>