Robot programming using the paradigm of learning by demonstration
Sandra Nope*, Humberto Loaiza, Eduardo Caicedo
Grupo en Percepción y Sistemas Inteligentes. Universidad del Valle. Calle 13 N.° 100-00. Santiago de Cali, Colombia.
Resumen
Se presenta la programación de un robot mediante el paradigma del aprendizaje por demostración, utilizando técnicas bio-inspiradas para extraer la información relevante que acompaña la acción del demostrador, y crear un mapa visuo-motor que relaciona las entradas visuales con comandos motrices necesarios para imitar un comportamiento o una tarea. El sistema se evaluó cualitativamente mediante una encuesta y cuantitativamente mediante métricas específicas para calificar la calidad de la imitación de un grupo de cuatro gestos. De esta manera, se pudieron corroborar las potencialidades del aprendizaje por demostración para la programación de robots, ya que el sistema fue capaz no solo de realizar sus propias interpretaciones de los gestos que se le enseñaron, sino de utilizar las habilidades aprendidas en la realización de gestos novedosos.
Palabras clave: Aprendizaje por demostración, visión artificial, mapa visuo-motor, imitación de gestos, robótica.
Abstract
This paper presents the application of the paradigm of learning by demonstration for robot programming. Algorithms use bio-inspired techniques to extract relevant information accompanying the demonstrator's action. A visuo-motor map relates visual inputs to motor commands necessary to imitate a behavior or a task. The system was evaluated qualitatively using a survey, and quantitatively by specific metrics to score the quality of the imitation of a group of four gestures. Thus, the learning by demonstration potential for robot programming is corroborated, since the system was able not only to make their own interpretations of the gestures to be taught, but to use the skills learned in conducting novel gestures.
]]> Keywords:Learning by demonstration, artificial vision, visuo-motor map, gesture imitation, robotic.Introducción
En los últimos años se ha venido explorando una metodología para la programación más amigable y sencilla de robots, en tareas de alta complejidad y que, no impliquen un alto nivel de experticia del programador, ni conocimiento de la plataforma robótica y las posibles condiciones de operación, y por tanto, que no demanden un excesivo período de puesta en funcionamiento. Una de estas metodologías es el "aprendizaje por demostración".
El aprendizaje por demostración inicialmente, fue abordado en trabajos de psicología y neurociencia, mostrándolo como la forma natural en la que los humanos [1] y algunos animales aprenden [2]. Es por tanto, una técnica poderosa en la adquisición de conocimiento que, aplicada en robótica, permitiría la programación de robots con la habilidad de aprender comportamientos complejos e interactuar inteligentemente con el ambiente. Así mismo, abre la posibilidad de que varios robots puedan ser programados simultáneamente, aún cuando los robots difieran morfológicamente del demostrador o maestro (que puede ser un humano u otro robot). Los trabajos previos abarcan aplicaciones que van desde la réplica exacta de la trayectoria seguida por un efector final [3,4], hasta la imitación de gestos faciales [5] o agarres con una o dos manos [6]. En [7] se desglosan los sub-problemas involucrados en la imitación: observación, reconocimiento y ejecución de la imitación.
La mayor parte de las investigaciones se centran en uno o más de estos sub-problemas, ninguna los cubre todos. Algunos de los sub-problemas abordados por todos son: la segmentación, el procesamiento de la información relevante que acompaña la acción demostrada y la elección de una representación apropiada. Dentro de los sub- problemas sin resolver se destacan la elección de un maestro apropiado, la selección automática del momento para realizar una acción aprendida y la evaluación cuantitativa de la imitación cuando está orientada a alcanzar una meta y no una réplica exacta de las acciones ejecutadas por el demostrador. Este último se aborda en el presente trabajo para evaluar las imitaciones realizadas por un brazo robótico simulado que realiza su propia interpretación del gesto observado guardando semejanza con la biología (bio-inspiración).
Seguidamente, se analiza el concepto de imitación, y luego se realiza una breve descripción del sistema implementado. Posteriormente, se presenta la metodología de evaluación, en la que se basan los resultados presentados a continuación. Por último, se plantean las conclusiones y el trabajo futuro.
El concepto de imitación
]]> La imitación es un concepto difícil de definir, y no se ha adoptado una definición estándar. De hecho, parece adaptarse a la conveniencia de cada trabajo de ingeniería. De acuerdo con la Real Academia de la Lengua Española, imitar se define como: i. "Ejecutar algo a ejemplo o semejanza de otra cosa"; ii. "Dicho de una cosa: Parecerse, asemejarse a otra"; y, iii. "Hacer o esforzarse por hacer algo lo mismo que otro o según el estilo de otro".Por otro lado, identificar la correspondencia cuando se trata de la misma especie puede parecer relativamente simple. Sin embargo, copiar de forma exacta un gesto no es siempre posible.
Descripción del sistema
Para definir los bloques constitutivos del sistema robótico de aprendizaje por demostración utilizado para la validación experimental, se adopta la definición dada por [8]: "imitación es cuando un gesto es observado, reconocido y ejecutado", (Figura 1). La reproducción del gesto no debe ser necesariamente exacta.
]]>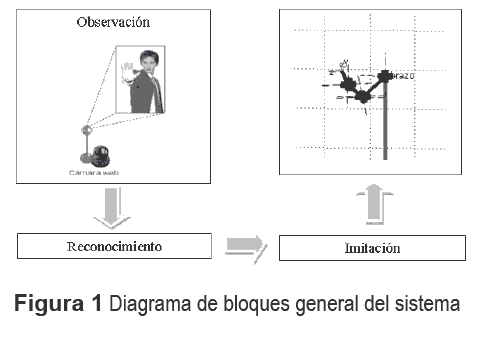
El bloque de "Observación" extrae la información visual (vídeos) del ambiente mediante una cámara Web con baja resolución y condiciones ambientales semi-controladas. El operario del sistema deberá indicar a cuál demostrador observar y cuándo hacerlo.
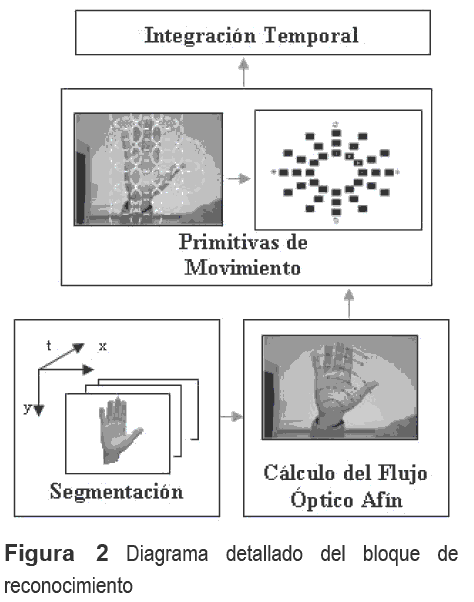
El bloque de "Reconocimiento" genera, a partir de los vídeos una representación que reúne la información de movimiento en el tiempo [9]. En este bloque, la codificación de la información de movimiento instantánea utiliza técnicas bio-inspiradas en la forma en la que se procesa la información de movimiento en el cerebro de macacos, similar al cerebro humano. Esta representación de la información facilita el proceso de reconocimiento del gesto efectuado por el demostrador y su posterior imitación.
El bloque de "Imitación" relaciona la representación de la información visual con el espacio motor, generando de esta manera un mapa visuo-motor. Gracias a este mapa, se dota al sistema de una transformación directa a variables articulares del robot, que permiten que el robot realice su propia interpretación de la escena observada. El mapa visuomotor se generó con una Red Neuronal de Regresión Generalizada -RNGD, por lo que las interpretaciones están influidas por las relaciones entre estos dos espacios realizadas durante la fase de entrenamiento y al igual que en el bloque de "Observación", al sistema se le indica el momento y lugar en el que debe realizar la ejecución de la acción. En [10], se describe la manera de obtener los valores articulares desde una imagen monocular tomada por una cámara Web sin calibrar, de tal forma que un brazo robótico con 6 grados de libertad (GDL) rotacionales pueda imitar la pose de un brazo humano durante la ejecución de un gesto.
Condiciones experimentales
Las condiciones de grabación de los vídeos, en cuanto a velocidad de ejecución y condiciones de iluminación no fueron controladas para que fuesen constantes. Sin embargo, se evitaron ejecuciones demasiado rápidas del gesto, grabaciones en horas nocturnas, y el solapamiento del objeto de interés con objetos similares de color.
Bio-inspiración en el bloque "Reconocimiento"
]]> Aunque el sistema visual humano es aparentemente el más desarrollado, ha sido más estudiado el cerebro de animales, en especial el cerebro de macacos debido a la similitud de sus capacidades visuales con las humanas [11], en el que han encontrado áreas equivalentes al cerebro humano y algunas codificadas bajo el mismo nombre.Bloque "Imitación"
El mapa visuo-motor fue construido mediante redes neuronales de regresión generalizada con un valor de uno del parámetro de suavizado. Para su entrenamiento, se usaron 48 de los 140 vídeos disponibles. Sin embargo, el número de ejemplos es mucho mayor, pues los datos de entrenamiento dependen de la duración de la ejecución completa del gesto, en cada uno de los vídeos. Específicamente, los datos visuales de entrada corresponden a los histogramas calculados sobre la Imagen de la Historia del Movimiento IHM con memoria de 5 tramas [15]. Las IHMs tienen la ventaja de eliminar información redundante y reducir el espacio de entrada a la red neuronal a un vector de 1x36.
Metodología de evaluación
La funcionalidad del sistema se evaluó mediante un grupo de cuatro gestos, que deben ser reconocidos e imitados a través de simulaciones de un brazo robótico. Los tres primeros gestos ya fueron usados por [16] para evaluar su sistema de imitación de gestos. Sin embargo, los movimientos que se requieren en sus respectivas ejecuciones sólo involucran 2 de sus 6 GDL, por lo que se adicionó el gesto 4, que involucra a todos los GDL disponibles. Los gestos corresponden a: Gesto 1: rotar la mano en sentido contrario a las manecillas del reloj y devolverse, como cuando se saluda. Gesto 2: bajar y subir la mano, como abanicando o como cuando se llama a alguien. Gesto 3: rotar la mano en sentido inverso a las manecillas del reloj, gesto que puede asociarse a limpiar una superficie. Gesto 4: acercar y alejar la mano respecto a la cámara, gesto que puede asociarse a un rechazo o acercamiento.
Se grabaron 140 vídeos, con diferentes demostradores realizando uno de los cuatro gestos posibles, es decir, 35 interpretaciones (vídeos) de cada gesto. De éstos, 48 (12 de cada gesto) fueron usados en la fase inicial de entrenamiento de la red neuronal y 92 (23 de cada gesto) para evaluación del sistema. ]]>
Para evaluar la ejecución de los gestos imitados se realizó un análisis tanto cualitativo como cuantitativo. El primero da cuenta del carácter subjetivo del juicio del observador y se obtiene mediante una encuesta a un grupo de ocho personas. El segundo involucra métricas para cada gesto que brindan una medida cuantitativa porcentual del éxito.
Encuesta
El grupo de encuestados se conformó por 4 personas afines a la Ingeniería y 4 personas completamente ajenas a ellas. Inicialmente se explicó que el objetivo de la encuesta era evaluar la calidad de la imitación de un robot con respecto al gesto ejecutado por un demostrador. Para facilitar la identificación se realizó una ejecución de los gestos a calificar asociándolos con uno de los siguientes nombres: gesto 1-saludar, gesto2-abanicar, gesto3- rotar y gesto4-acercar y alejar. Posteriormente, se le presentaron al encuestado dos visualizaciones con diferentes puntos de vista de la ejecución realizada por el robot, una frontal y una lateral.
La primera parte solicita identificar el gesto que a juicio del encuestado fue ejecutado por el robot. Las opciones de respuesta fueron: Saludar, Abanicar, Rotar, Acercar y alejar, Otro. A continuación, se le presentaron al encuestado las ejecuciones simultáneas del demostrador y el robot, seguidas de la pregunta: ¿Considera usted que el robot imitó el gesto realizado por el demostrador? Las respuestas posibles son: SI, NO.
El proceso descrito anteriormente se repitió para cada uno de los vídeos de prueba (92), 23 para cada gesto.
Con el objeto de evaluar si la percepción de los encuestados varía de acuerdo con la familiarización de éstos a la visualización de los resultados hecha por el robot, pasados unos días se le realizó a los encuestados las mismas preguntas sobre 20 vídeos escogidos al azar de los 92 iniciales. De esta manera, a través de la primera encuesta se habitúan con la visualización.
A pesar de la naturaleza subjetiva en el juicio sobre la imitación, en trabajos de ingeniería es importante tener medidas cuantitativas que describan la calidad de la imitación o medida de la correspondencia, en particular, cuando la imitación está dirigida a la meta de la acción y no a la ejecución de una réplica exacta de las acciones del demostrador.
Investigaciones de neurociencia, indican que los observadores suelen fijar su atención en la trayectoria seguida por el efector final [17], así, se emplearon las formas geométricas que se generan durante la ejecución de los gestos como mecanismo para evaluar la calidad de la imitación cuando el imitador realiza su propia interpretación del gesto, incluyendo variaciones de velocidad y escala. Estas consideraciones cobran importancia cuando el demostrador y el imitador no comparten las mismas características antropomórficas o condiciones de tarea, y en donde una réplica exacta puede no corresponder a la respuesta óptima, ni ser físicamente posible.
La figura 3 presenta un ejemplo para los gestos del 1 al 3, de las formas geométricas que se forman durante la trayectoria seguida por el dedo corazón, proyectada en un plano de imagen. En el caso del gesto 1 (saludar), dicha forma corresponde aproximadamente a dos parábolas, en donde la variable dependiente corresponde al eje de las abscisas; una de las parábolas corresponde al recorrido de la mano durante la rotación en el sentido inverso a las manecillas del reloj (desde la perspectiva del observador) y la otra al recorrido durante el regreso de la mano. Aunque se habla de parábolas diferentes, pueden coincidir. En el gesto 2 (abanicar), la forma corresponde aproximadamente a dos parábolas pero, en este caso, la variable dependiente corresponde al eje de las ordenadas. Al igual que en el caso anterior, las parábolas pueden coincidir. En el gesto 3 (rotar la mano), la forma corresponde aproximadamente a una elipse.
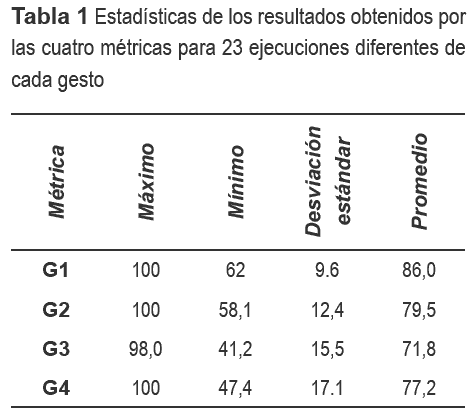
El gesto 4 no tiene una forma particular en la trayectoria del efector final que se preservara durante las diferentes ejecuciones; variando con cambios en la orientación del demostrador hacia la cámara. Sin embargo, se encontró que el cambio del tamaño de la mano en el tiempo se puede aproximar a una Gausiana. Un ejemplo aparece en la figura 4.
]]>
Las formas son aproximadas y rara vez se ajustan en un 100%, incluso cuando se usan los datos reales obtenidos durante las ejecuciones realizadas por el demostrador; sin embargo, se consideran una buena aproximación para identificar el éxito en la imitación.
Resultados
Resultados métricas
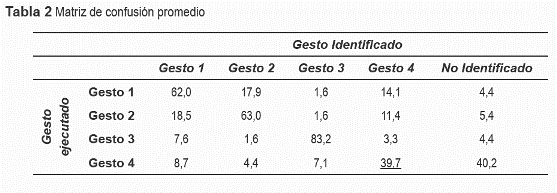
La tabla 1 resume los resultados obtenidos por las cuatro métricas para cada una de las ejecuciones del gesto para el que se crearon. Con la métrica para evaluar el gesto 1 (saludar), el menor porcentaje obtenido fue de 62 y el mayor de 100, mientras que el promedio fue de 86%. Con la métrica para evaluar el gesto 2 (abanicar), el menor porcentaje fue de 58.1, el mayor de 100, y el promedio fue de 79.5%. Con la métrica para evaluar el gesto 3 (rotar la mano), el menor porcentaje fue de 41,2, y el mayor de 98, y l promedio fue de 71,8%. Con la métrica para evaluar el gesto 4 (acercar y alejar la mano), el menor porcentaje fue de 47,4, el mayor de 100, y el promedio fue de 77,2%.
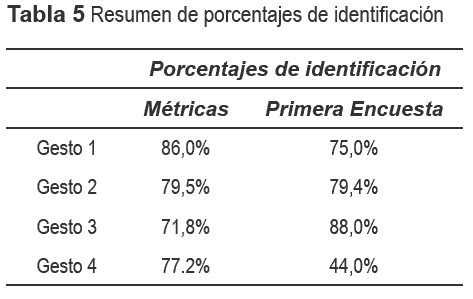
Los resultados obtenidos con las métricas propuestas, permiten concluir que, en general, se obtuvieron buenas ejecuciones de los diferentes gestos, las mejores ejecuciones ocurren en su orden: gesto 1 (86%), gesto 2 (79,5%), gesto 4 (77,2%) y gesto 3 (71,8%).
Resultados encuestas
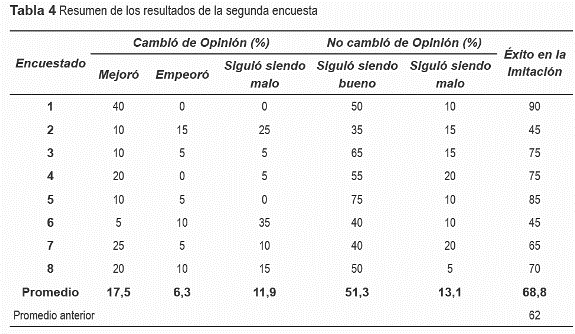
Los resultados de la primera pregunta se resumen en la matriz de confusión (tabla 2). Los datos de la diagonal principal indican el porcentaje de veces que cada gesto se identificó correctamente. Los valores por fuera de la diagonal se interpretan como una identificación errónea entre los gestos de la fila y columna de la casilla respectiva. Una identificación exacta arrojaría una diagonal con 100% y 0% fuera de ella. ]]>
Se observa que el gesto mejor identificado fue el 3, seguido por el 2 y el 1. Por otro lado, el gesto peor identificado fue el 4, y la mayoría de las veces fue asociado a la opción No identificado. El porcentaje de reconocimiento correcto varío entre el 39,8% y el 83,2%, con un promedio de reconocimiento del 62%.
Los resultados a la segunda pregunta se sintetizan en la tabla 3, en la que aparece el porcentaje de casos en los que los encuestados consideraron que efectivamente hubo imitación.
Los encuestados consideraron que hubo una buena imitación en el caso de los gestos 1 (saludar), 2 (abanicar) y 3 (rotar) con porcentajes promedios superiores al 75%. El gesto con menor dispersión en los datos (gesto 3 -rotar la mano con 8,3), y el de mayor dispersión (gesto 4 - acercar y alejar la mano con 33,9) el que presentó mayor dificultad en la identificación. En el caso de los gestos 1 y 2 el valor de las dispersiones se encuentra en el rango intermedio y tuvieron un buen reconocimiento.
Para responder a esta pregunta, se permitió a los observadores que vieran simultáneamente las ejecuciones del demostrador y del imitador, produciendo una modificación del juicio inicial en un alto número de encuestados sobre la calidad de la imitación, debida posiblemente a la poca familiaridad con la visualización.
Discusión
En la tabla 5 se presenta el resumen de los resultados en la identificación, obtenidos a través de las métricas y el resultado de la primera encuesta. Se observa que, si se usan las métricas la mejor imitación se presenta para el gesto 1, en cambio con las encuestas este gesto ocupa la tercera posición. El gesto 2 ocupa el segundo puesto en los dos casos de análisis. Aunque el gesto 3, a la luz de las métricas se obtiene el peor de los resultados, los encuestados consideraron que el gesto 3 tiene las mejores ejecuciones durante la imitación por parte del robot. Esto probablemente ocurre porque para los encuestados, una buena imitación del gesto 3 incluye un rango de trayectorias más variado que el de una elipse rigurosa. Lo contrario ocurre con el gesto 4 que, basándose en el indicador 4, parece tener un buen desempeño; y sin embargo, subjetivamente fue calificado en forma bastante deficiente (44,02%).
Se observa por tanto una mejor correspondencia entre los resultados de las métricas para los gestos 1, 2 y 3 con los resultados de la primera encuesta.
El trabajo que guarda mayor similitud con el expuesto es [12], que también es bio-inspirado y emplea 3 de los 4 gestos usados aquí. En nuestro trabajo se incluyen emulaciones de más áreas cerebrales que mejoran la percepción de los movimientos del demostrador. Esto permitió reconocer movimientos de expansión, compresión o de rotación, así como la dirección y velocidad con la que se realizan. Adicionalmente, el robot es capaz de realizar su propia imitación y no pre-definida, incluyendo la imitación del gesto 4 - acercar y alejar la mano, que implica el movimiento simultáneo de todas las articulaciones del brazo robótico.
El enfoque del Mapa visuo-motor permite que los movimientos aprendidos puedan ser empleados durante la imitación de gestos desconocidos, lo que es imposible de lograr mediante la propuesta de Kuniyoshi y sus colegas. ]]>
Finalmente, se mejoró la evaluación sobre el éxito en la imitación, al calificar tanto cualitativa como cuantitativamente las ejecuciones del robot, en donde se propuso un conjunto de métricas orientadas a la meta y casi no consideran los detalles irrelevantes de la ejecución.
Conclusiones
Se presentó un sistema que utiliza el paradigma del aprendizaje por demostración para programar un robot, de tal forma que aprenda a imitar un grupo de gestos, usando algoritmos computacionales que integran aspectos de neurociencia, neurofisiología y psicología.
El Mapa visuo-motor permite que los movimientos aprendidos puedan ser empleados en gestos desconocidos, lo que es imposible usando la propuesta de Kuniyoshi y sus colegas. Además, permite imitar un gesto como el de acercar y alejar la mano, que implica el movimiento simultáneo de todas las articulaciones del brazo robótico.
Para evaluar la imitación se planteó una evaluación cualitativa y cuantitativa. La primera se obtuvo a través de una encuesta y explora el papel subjetivo del juicio del observador. La segunda determina porcentajes de similitud o de éxito en la imitación, basándose en la forma geométrica de la trayectoria seguida por el efector final para los gestos 1, 2 y 3, mientras que el gesto 4 usa el cambio en el tiempo del tamaño de la mano. Sin embargo, las formas usadas por los indicadores son aproximadas, y rara vez se ajustan en un 100%; aún cuando se usan los datos reales, obtenidos durante las demostraciones realizadas.
El análisis simultáneo de los resultados obtenidos indican que los gestos 1 y 2 tienen una buena evaluación tanto en las métricas como en las encuestas. Por el contrario, el gesto 3 aunque no tuvo un buena evaluación con la métrica fue el mejor en la encuesta, esto probablemente ocurre porque para los encuestados, una buena imitación del gesto 3 incluye un rango de trayectorias más variado que el de una elipse rigurosa. De forma análoga, el gesto 4 parece tener un buen desempeño en la métrica y, deficiente en la encuesta. Lo anterior se puede explicar en los problemas de perspectiva necesaria de la visualización del gesto. Se observó que la familiarización de las personas con la visualización mejora su percepción de la imitación. ]]>
El aprendizaje por imitación es promisorio en la programación de robots; aunque los desarrollos hasta ahora corresponden a tareas relativamente simples. Una de las ventajas es que el demostrador y el robot pueden tener diferencias antropomórficas, y el robot se adapta su ejecución a sus características físicas. Las limitaciones del sistema propuesto están relacionadas con los algoritmos elegidos, y no con los principios del aprendizaje por imitación.
Trabajo futuro
A corto plazo, es conveniente analizar la posibilidad de simplificar la extracción de las primitivas de movimiento con el propósito de disminuir los tiempos de cómputo. A largo plazo, se plantea probar los algoritmos creados en un robot real y/o mejorar la interfaz gráfica del sistema para facilitar la visualización.
Aunque el sistema propuesto presenta un buen desempeño con la mayoría de los gestos seleccionados, disminuye en la medida en la que aumentan el número de articulaciones y grados de libertad necesarios para realizarlos. Por esta razón, se plantea usar primitivas motoras que se asocien a las partes del cuerpo involucradas aumentando la información durante el movimiento. En este caso, deben tenerse en cuenta las oclusiones entre las partes del cuerpo involucradas.
Agradecimientos
Agradecemos al Programa de apoyo a doctorados de Colciencias, a la Universidad del Valle y al Instituto Técnico Superior (IST) - de Portugal. Un reconocimiento especial al profesor José Santos- Victor del IST - Portugal por su orientación, consejo y apoyo.
Referencias
1. A. N. Meltzoff. "Born to Learn: What infants learn from watching us". The Role of Early Experience in Infant Development. L. A. L. N. A. Fox, and J. G. Warhol (Eds.), Ed. Skillman. Pediatric Institute Publications. New Jersey (USA). 1999. pp. 145-164. [ Links ]
2. B. G. Galef. "Imitation in animals: History, definition and interpretation of data from the psychological laboratory". Social learning: Psychological and Biological Perspectives. T.R. Zentall & B. G. Galef, Jr. (editores.), Ed. Hillsdale. Lawrence Erlbaum. New Jersey (USA). 1988. pp. 3-28. [ Links ]
3. A. Billard, Y. Epars, S. Calinon, S. Schaal, G. Cheng. "Discovering optimal imitation strategies". Robotics and Autonomous Systems. Special Issue: Robot Learning from Demonstration. Vol. 47. 2004. 69-77. [ Links ]
4. M. Cabido, J. V. Santos. "Visual Transformations in Gesture Imitation: what you see is what you do". Proceedings IEEE International Conference on Robotics & Automation. Vol. 2. 2003. pp. 2375-2381. [ Links ]
5. D. H. Kim, H. S. Lee, M. J. Chung. "Biologically Inspired Models and Hardware for Emotive Facial Expressions". International Workshop Robot and Human Interactive Communication. Agosto 13-15. 2005. pp. 679-685. [ Links ]
6. J. Zhang, B. Rössler. "Self-valuing learning and generalization of visual guided grasping". Robotics and Autonomous Systems. Special Issue: Robot Learning from Demonstration. Vol. 47. 2004. pp. 117-127. [ Links ]
7. P. Bakker, Y. Kuniyoshi. "Robot See, Robot Do: An overview of robot imitation". Workshop on Learning in Robots and Animals. Abril 1-2. 1996. pp. 3-11. [ Links ]
8. E. L. Thorndike. "Animal Intelligence". B. G. Galef (editor) Imitation in animals: History, definition and interpretation of data from psychological laboratory. Ed. Macmillan. New York (USA). 1988. pp. 3-28. [ Links ]
9. S. Nope, H. Loaiza E. Caicedo. "Modelo Bio-inspirado para el reconocimiento de gestos usando primitivas de movimiento en visión". Revista Iberoamericana de Automática e Informática Industrial (RIAI). Vol. 5. 2008. pp. 69-76. [ Links ]
10. S. Nope, H. Loaiza E. Caicedo. "Reconstrucción 3D- 2D de Gestos usando Información de Vídeo Monocular Aplicada a un Brazo Robótico". Rev. Fac. Ing Univ. Antioquia. Vol. 53. 2010. pp. 145-154. [ Links ]
11. R. L. DeVanois, M. C. Morgan, D. M. "Snodderly. Psychophysical studies of monkey vision. III. Spatial luminance contrast sensitivity test of macaque and human observers." Vision Research. Vol. 14. 1974. pp. 53-67. [ Links ]
12. V. Bruce, P. R. Green, M. A. Georgeson. Visual Perception: Physiology, Psychology and Ecology. Cuarta Edición. Ed. Psycology Press, an imprint of Erlbaum (UK) Taylor & Francis Ltd. 2003. pp. 171-204. [ Links ]
13. M. Pomplun, J. Martinez Trujillo, E. Simine, Y. Liu, S. Treue, J. K. Tsotsos. "A Neurally-Inspired Model for Detecting and Localizing Simple Motion Patterns in Image Sequences". Workshop on Dynamic Perception. Bochum (Alemania). Nov. 22-24. 2002. pp. 45-52. [ Links ]
14. A. F. Bobick, J. W. Davis. "The Recognition of Human Movement using Temporal Templates". IEEE Transactions on Pattern Analysis and Machine Intelligence. Vol. 23. 2001. pp. 257-267. [ Links ]
15. S. Nope. Sistema Bio-inspirado de Reconocimiento e Imitación de Gestos Aplicado en Robótica. Tesis de doctorado. Facultad de Ingeniería. Universidad del Valle. 2008. pp. 45-66. [ Links ]
16. Y. Kuniyoshi, Y. Yorozu, M. Inaba, H. Inoue. "From visuo-motor self learning to early imitation - a neural architecture for humanoid learning". International Conference on Robotics & Automation. Taipei (Taiwan). 2003. Vol. 3. pp. 3:3132-3139. [ Links ]
17. M. J. Mataric, M. Pomplun. "Fixation behavior in observation and imitation of human movement". Cognitive Brain Research. Vol. 7. 1998. pp. 191-202. [ Links ]
(Recibido el 3 de marzo de 2010. Aceptado el 14 de septiembre de 2010)
*Autor de correspondencia: teléfono: + 57 + 2 + 330 34 36, fax: + 57 + 2 + 339 21 40 Ext. 112, correo electrónico: sandra.nope@correouni-valle.edu.co (S. Nope)
]]>