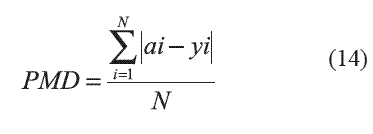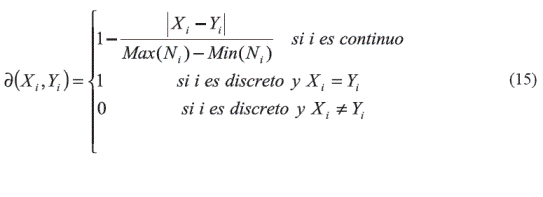0120-62300120-6230S0120-62302011000400014CubaCubaCuba000920110009201160141152Una medida de la teoría de los conjuntos aproximados para sistemas de decisión con rasgos de dominio continuo
A measure in the rough set theory to decision systems with continuo features
Yaima Filiberto1 , Rafael Bello2, Yailé Caballero*1, Rafael Larrua3
1Departamento de Computación. Universidad de Camagüey. Carretera Circunvalació Norte km 5 ½. Camagüey, Cuba.
2Departamento de Ciencia de la Computación. Universidad Central de Las Villas. Carretera a Camajuani km 5 Santa Clara, CP 54838, Cuba.
3Centro de Estudio de Estructuras. Universidad de Camagüey. Carretera Circunvalacióón Norte km 5 ½. Camagüey, Cuba.
Resumen
]]>
La Teoría de los conjuntos aproximados ofrece diversas medidas y técnicas para el análisis de datos, especialmente en el caso de problemas donde el rasgo de decisión tiene dominio discreto. En este artículo se propone una medida y métodos basados en ella que permiten extender la aplicabilidad de esta teoría para el caso de problemas donde los rasgos tienen dominio continuo, especialmente el rasgo de decisión. Los estudios experimentales realizados muestran su efectividad.
Palabras clave: Selección de rasgos, aproximación de funciones, teoría de los conjuntos aproximados.
Abstract
The Rough set theory provides several measures and techniques to data analysis, especially in the case of problems in which the decision feature has a discrete domain. In this paper a measure and methods are proposed which allow extending this theory to the case of problems in which the features have a continuo domain, especially the decision feature. The experimental studies show their affectivity.
Keywords:Feature selection, function approximation, rough set theory.
Introducción
La teoría de Los Conjuntos Aproximados (Rough Set Theory, RST) fue propuesta por Pawlak en 1982 [1]. La filosofía de los conjuntos aproximados se basa en la suposición que alguna información es asociada con cada objeto del universo de discurso [2]. Entre las ventajas de la RST para el análisis de datos está que esta solo se basa en los datos originales y no necesita cualquier información externa; no es necesaria ninguna suposición acerca de los datos; así, como que sirve para analizar tanto rasgos cualitativos como cuantitativos [3, 4].
El uso de reductos (conjunto mínimo de atributos que preserva la partición del universo) en la selección de rasgos ha sido estudiado por diversos autores como [5-13]. La selección de rasgos es útil en diferentes tareas computacionales, por ejemplo, en el proceso de aprendizaje automatizado. Una apropiada representación del espacio de aprendizaje por la selección de atributos relevantes es un asunto crucial en el aprendizaje [14-17]. Por lo general, no todos los rasgos que describen el ejemplo son relevantes en el proceso de clasificación y algunos de ellos son irrelevantes. Rasgos irrelevantes aumentan la complejidad de proceso de aprendizaje y disminuyen la calidad del conocimiento inducido [18-20]. ]]>
La selección de rasgos es un caso particular de un problema más general de selección de subconjuntos en el cual se maximiza algún criterio adoptado. Los métodos de selección de rasgos buscan entre los subconjuntos de rasgos y tratan de encontrar el mejor subconjunto entre los 2N-1 subconjuntos candidatos según alguna medida de evaluación, donde la N denota el número de rasgos. Cada estado representa un subconjunto de rasgos posibles en el espacio de búsqueda.
Todos los métodos de selección de rasgos contienen dos componentes importantes: una función de evaluación y un algoritmo de generación de subconjuntos. La función de evaluación da una medida de calidad (bondad) de un subconjunto producido por algún procedimiento de generación. Un subconjunto siempre es óptimo con respecto a una determinada función de evaluación. Hay varias categorías de funciones de evaluación, tales como medidas de distancia, las medidas de información (por ejemplo Entropía), las medidas de dependencia, las medidas de consistencia, y la medida porciento del error del clasificador [20]. El algoritmo de generación de subconjunto se basa en un método de búsqueda. Las estrategias de búsqueda son importantes porque el proceso de selección de rasgos puede consumir mucho tiempo y una búsqueda exhaustiva del subconjunto "óptimo" no es práctico, incluso para los problemas de tamaño moderado [21].
Usualmente, la medida llamada calidad de la clasificación se emplea cuando se usa la RST para construir la función de evaluación; esta medida permite calcular la consistencia de un sistema de decisión. Otras medidas útiles en los procesos de selección de rasgos definidas en RST son una para computar la dependencia entre rasgos y otra para computar el peso de los rasgos. Estas medidas muestran la aplicabilidad de la RST clásica en el análisis de datos; pero, todas ellas se definen en el caso de sistemas de decisión donde el dominio de los rasgos es discreto.
Con el fin de considerar los rasgos de predicción continuos se han desarrollado algunas extensiones de la RST clásica (llamada RST extendida), como la RST basada en las relaciones de similaridad. Pocas alternativas consideran el caso de rasgos de decisión con dominio continuo [2, 22].
En este artículo se propone una nueva medida para el caso de sistemas de decisión en el que el dominio de los rasgos, incluido el rasgo de decisión, no tiene que ser necesariamente discreto. Se analiza el uso de esta medida para construir la relación de semejanza en la RST extendida; el método propuesto también permite para calcular el peso de los rasgos. ]]>
En este artículo se presentan los conceptos y medidas fundamentales de la RST, se analiza la extensión de la misma para el caso de rasgos con dominios continuos, y se muestra cómo el empleo de relaciones de similaridad en la RST lleva a la necesidad de calcular los pesos de los rasgos involucrados en las funciones de similaridad. Se introduce además una nueva medida. En Se muestra el empleo de esta medida en un método para el cálculo de los pesos de los rasgos de un sistema de decisión continuo para el problema de aproximación de funciones, realizándose un estudio experimental del método.
La teoría de los conjuntos aproximados:fundamentos
En la Teoría de los Conjuntos Aproximados la información es representada por una tabla donde cada fila representa un objeto y cada columna representa un rasgo. Esta tabla se llamada Sistema de Información; más formalmente, es un par S = (U,A), donde U es un conjunto finito no vacío de objetos llamado Universo y A es un conjunto finito no vacío de atributos. Un Sistema de Decisión es cualquier sistema de información de la forma DS = (U,A⋃{d}), donde d∉Aes el atributo de decisión. Los componentes principales de la RST son el Sistema de Información (o el Sistema de Decisión) y una relación de inseparabilidad (indiscernibilityrelation). Los conceptos básicos de RST son los conceptos de aproximación inferior y superior. Una definición clásica de aproximación inferior y superior fue originalmente introducida con referencia a una relación de inseparabilidad la cual es una relación de equivalencia [1, 23].
Sea DS = (U, A⋃{d}) un sistema de decisión y B⊆Ay X⊆U. B define una relación de equivalencia y el subconjunto X es un concepto en el universo U. X se puede aproximar usando sólo la información contenida en B mediante la construcción de la aproximaciones B-inferior y B-superior, denotadas por B*X y B*X respectivamente, y definidas por las expresiones B*X={x∈U : [x]B⊆X} y B*X = {x∈U : [x]B⋂X≠ø} respectivamente.
Donde[x]B denota la clase de x de acuerdo a la relación de inseparabilidad B. Los objetos en B*X son con certeza miembros de X, mientras los ob-jetos en B*X son posiblemente miembros de X. Basada en las aproximaciones la RST ofrece la medida calidad de la clasificación, definida por la expresión (1). Sea una partición Y = {Y1,..., Yn}de U de acuerdo a los valores del rasgo de decisión d (clases), donde los subconjuntos Yi, son llamados clase de decisión.
El coeficiente γB(Y) expresa el porciento de objetos que pueden ser clasificados correctamente en las clases Yi, ..., Yn usando los rasgos en B solamente. Esta última medida puede ser usada para evaluar la consistencia de un sistema de decisión y mejorar la selección de rasgos. Un sistema de decisión es inconsistente si objetos inseparables pertenecen a clases de decisión diferentes. En el caso del problema de selección de rasgos, esta medida puede ser usada para evaluar la calidad de un subconjunto de rasgos, [5-13]. Un reducto es un conjunto minimal de atributos B⊆A tal que IND(B) = IND(A), es decir ambos generan la misma partición del universo U, lo cual es equivalente a γB(Y)=γA(Y). ]]>
Pero si el dominio del rasgo de decisión no es discreto, no se puede realizar una partición del universo en clases de decisión, de modo que no es posible usar la medida calidad de la clasifi-cación para medir la consistencia del sistema ni para realizar la selección de rasgos basado en el concepto de reducto. La medida que se propone en las secciones siguientes es una alternativa de solución para esta restricción.
La teoría de los conjuntos aproximados:extensiones
Las definiciones previas de conjuntos aproximados se basan en una relación R que define como inseparables a pares de objetos que tienen igual valor para un subconjunto de rasgos (B), es decir, los objetos (x,y) son inseparables según B si ai(x) =ai (y), para todo rasgo i en B, donde ai(x) denota el valor del rasgo i en el objeto x. Definida de esta forma, R es una relación de equivalencia.
Cuando el dominio de los rasgos en B no es discreto, una relación de inseparabilidad definida de esta forma no es aplicable. La relación de equivalencia es muy estricta en caso de dominios continuos pues ligeras diferencia entre los valores de los objetos para un rasgo pueden no ser significativas al analizar su inseparabilidad; por ejemplo, una temperatura de 37,8 grados puede ser considerada igual a otra de 37,9 grados, al medir la temperatura corporal de dos personas. Esto es especialmente importante en el caso de rasgos numéricos en los cuales pequeños errores en la medición de los mismos pueden generar estas diferencias. Es necesario usar otros tipos de relaciones de inseparabilidad entre los objetos del universo U. Emplear una relación de semejanza en lugar de una relación de equivalencia es más adecuado en estos casos. Remplazando la relación de equivalencia por una relación binaria más débil, se obtiene una extensión del enfoque clásico de la RST. Algunas extensiones se estudian en [23-29].
Esto se logra extendiendo el concepto de inseparabilidad entre objetos de modo que se agrupen en la misma clase los objetos similares, no idénticos, según una relación de semejanza R. Las relaciones de semejanza no inducen una partición del universo U, sino generan clases de semejanza para cualquier objeto x ∈ U. La clase de semejanza de x, de acuerdo a la relación de semejanza R se denota por R(x) y se define como R(x) = {y∈U :yRX}. Esta se lee como "el conjunto de objetos del universo U que son similares al objeto x de acuerdo a la relación R". Un ejemplo es el caso de las relaciones de tolerancia (tolerancerelation) [5-30], donde la relación R⊆XxU es reflexiva (xRx) para cualquier x∈ U y simétrica (xRy⇒yRx) para cualquier par x, y∈ U.
Mientras que las relaciones de equivalencias inducen una partición del universo, las relaciones de semejanza inducen un cubrimiento del universo. Un cubrimiento del universo U es una familia de subconjuntos no vacíos cuya unión es igual al universo. Una partición de U es un cubrimiento, de modo que el concepto de cubrimiento es una extensión del concepto de partición. Distintos investigadores han desarrollado estudios sobre la RST en el caso de espacios de aproximación que son cubrimientos, tales como [29, 31-33]; algunos de ellos orientados a construir una generalización de la RST basada en cubrimientos. Por eso, es muy interesante e importante encontrar una adecuada relación de semejanza para un sistema de decisión dado. ]]>
Un ejemplo de una extensión de la RST basada en relaciones de semejanza fue presentada por R. Slowinski y D. Vanderpooten [24]. Ellos definen las aproximaciones inferior y superior de un conjunto X de la forma siguiente. Sean x⊆ U y R una relación binaria y reflexiva sobre U. Entonces la aproximación inferior y superior se definen como R*(X) = {x ∈U: R-1 (x) ⊆X }y R*(X) = {x ∈U: R-1 (x) ⋂x ≠ ø }donde R-1 denota la relación inversa de R.
Resumiendo el orden actuación para trabajar con la RST. En el caso de datos continuos se puede elegir entre dos alternativas, discretizar los datos o usar una extensión de la teoría. En el primer caso, el sistema de información original se transforma en otro donde es aplicable el enfoque clásico [34, 35]. En la otra alternativa se emplea una relación de semejanza, definida como xRy<=> F(x, y) ≥ε, x, y∈ U, F(x, y) es una función de semejanza (la cual podría ser definida como en la expresión 8), y ε es un umbral (threshold). La inseparabilidad entre dos objetos depende del conjunto de pesos wi, como se analiza más adelante. Esta es una de las posibles aplicaciones de la nueva medida que se propone en este artículo, calcular el mejor conjunto de pesos para construir la relación de semejanza.
Medida calidad de la similaridad
Sea un sistema de decisión DS = (U, A ⋃ {d})donde el dominio de los rasgos en A ⋃ {d}pueden ser valores discretos o continuos, y relaciones de semejanza R1 y R2 entre los objetos definidas de la forma siguiente. Para todo par de objetos (x, y) en U:
Donde F1 y F2 son funciones de semejanza para calcular el grado de similaridad entre pares de objetos en el universo U, F1 considera los rasgos en A y F2 calcula la similaridad entre dos objetos de acuerdo al valor del rasgo d; e1 y e2 son umbrales de semejanza.
Usando las relaciones R1 y R2 se definen los conjuntos de objetos N1 y N2 para cualquier objeto x en el universo U según las expresiones (4) y (5), donde N1(x) y N2(x) son los conjuntos de objetos similares a x se acuerdo a las relaciones R1 y R2 respectivamente: ]]>
Entonces el problema de encontrar una relación de semejanza adecuada para la RST extendida consiste en encontrar las relaciones R1 y R2 que logran la mayor semejanzaposible entre los conjuntos N1 y N2,N1(x)≈N2(x), donde el símbolo (≈) denota la mayor similaridad posible entre los conjuntos N1(x) y N2(x) dado los umbrales e1 y e2. El grado de similaridad entre estos conjuntos se define por la expresión (6):
A partir de la expresión (6) la medida calidad de la similaridad del sistema de decisión DS = (U, A + {d}) se define por la expresión (7):
La medida θ(DS) representa el grado en el cual la similaridad entre los objetos usando los rasgos en A es equivalente a la similaridad que se obtiene de acuerdo al rasgo de decisión d. Entonces el problema es encontrar las relaciones R1 y R2 que maximizan la medida calidad de la similaridad.
En el caso de sistemas de decisión en los cuales el dominio del rasgo de decisión es discreto, como es el caso de los problemas de clasificación, la relación R2 se define como xR2y <=> d(x)=d(y). En este caso, el problema es encontrar la relación R1 tal que las clases de semejanza de un objeto se corresponden con su clase de decisión. El costo computacional de calcular esta medida es O(m2*(c1+c2)), donde c1 y c2 representan el costo computacional de evaluar las funciones F1(x,y) y F2(x,y); lo cual es ligeramente superior al costo de calcular la calidad de la clasificación según (1), el cual es O(k*l*m2), considerando que el costo de calcular la aproximación inferior de un conjunto es O(l*m2) de acuerdo a [Bel 98], donde l es la cantidad de rasgos, m la cantidad de objetos del universo y k la cantidad de clases.
Un método para calcular los pesos de los rasgos usando la medida calidad de la similaridad
La asignación de pesos a los rasgos puede ser vista como una generalización del problema de selección de rasgos. La noción de selección de rasgos ha evolucionado en el tiempo, según un enfoque clásico el resultado de un selector de rasgos es binario indicando si el rasgo debe ser considerado o no. Este enfoque se puede generalizar mediante la introducción de un concepto de "grado de relevancia", llamado también peso o importancia del rasgo, usualmente definido en el intervalo [0, 1]. ]]>
La RST clásica ofrece una medida para calcular la relevancia de un rasgo en un sistema de decisión (U, A ⋃ {d}). Primero se define una medida σ(A,d) para calcular el grado de dependencia del rasgo de decisión d respecto al conjunto de rasgos A. Si σ(A,d) = 1 entonces se dice que d depende completamente de A; si σ(A,d) = 0 entonces el rasgo de decisión es totalmente independiente de A, en otro caso d depende de A en grado k (0<k<1). Cuando el conjunto A se modifica, este grado de dependencia también se puede modificar; por eso, la diferencia numérica entres(A,d) y σ(A-{a}, d) se puede interpretar como una medida del grado de influencia que tiene el atributo a en σ(A, d).
A continuación se propone una alternativa para el caso de la importancia de los rasgos para el caso de la RST extendida, la cual es particularmente útil en el caso de que el dominio del rasgo decisión sea continuo. El cálculo del peso de los rasgos permite construir la relación de semejanza R1, definida por la expresión (2), y considerando la función F1 como una medida de semejanza que considera tres componentes principales: (i) Una medida de similaridad local usada para comparar los valores de un rasgo (llamada función de comparación del rasgo); (ii) El conjunto de pesos que representa la importancia relativa de cada atributo; (iii) Una medida de similaridad global responsable de computar el grado de similaridad entre dos objetos basada en las medidas de similaridad locales y el conjunto de pesos (llamada función de semejanza, y que se define por la expresión (8)).
Una expresión clásica para calcular el grado de similaridad entre dos objetos (X,Y) de un universo es:
donde: n es la cantidad de rasgos; wi es el peso del rasgo i; Xi, Yi son los valores del rasgo i en los objetos X, Y respectivamente; δies la función de comparación para el rasgo i.
Ejemplos de funciones de comparación de rasgos son la expresiones (9) y (10), la primera más usada en el caso de rasgos con dominio discreto y la segunda para rasgos de valores reales: ]]>
Definido de esta forma, el problema de construir la relación de semejanza R1 definida por la expresión (2), a partir de la función de semejanza F1 definida por la expresión (8), consiste en encontrar el conjunto de pesos W={w1, w2,...,wn}, donde n es la cantidad de rasgos en el conjunto A. El método que se propone para encontrar W, busca el conjunto de pesos que maximiza la expresión (7); en este caso, la relación de semejanza R2 definida por la expresión (3) utiliza como función de semejanza la expresión F2(X,Y) = ∂(d(X),d(Y)), donde ∂ es una función de comparación para el rasgo de decisión d. Como se planteó antes, en casos de problemas de clasificación donde el dominio del rasgo de decisión d es discreto basta con usar la expresión (9) como función de comparación de rasgos al construir F2.
Para encontrar el conjunto W que maximiza la expresión (7) se propone usar un método de búsqueda heurística tal como las meta heurísticas Optimización basada en partículas (ParticleSwarmOptimization, PSO) [36], o Algoritmos genéticos (GeneticsAlgorithms, GA), en cuyo caso se han hecho estudios particulares para considerar rasgos continuos [37, 38]. En este artículo el estudio experimental se realizó usando PSO, pues esta metaheurística ha mostrado un buen desempeño en los problemas de optimización continua [39, 40]. Además, el empleo de PSO en procesos de selección de rasgos junto a los conjuntos aproximados ya se ha estudiado por otros autores con buenos resultados como se muestra en [9, 10].
En este caso las partículas, que representan el vector W, tienen n componentes (una por cada rasgo en A). La calidad de las partículas se calcula usando la expresión (7). Al final del proceso de búsqueda desarrollado por el método PSO, la mejor partícula constituye el vector de pesos W a usar en la función de semejanza F1 (definida por la expresión 8), y con esta queda construida la relación de semejanza R1 (definida por la expresión 2).
El método propuesto constituye un nuevo procedimiento de aprendizaje de pesos cuyaaplicación no está limitada a problemas de clasificación. Ejemplos de algoritmos de aprendizaje de pesos para problemas diferentes a la clasificación son los basados en ordenamiento (ranking, score) de casos en el contexto del razonamiento basado en casos (Case-based Reasoning), en los cuales se retroalimenta al algoritmo con el orden deseado de los casos [41, 42]; en este caso, el objetivo del algoritmo de aprendizaje es optimizar una medida de similaridad de una manera tal que el orden dado a los casos recuperados sea igual al orden indicado por un tutor. Por otra parte, Hall presentó un algoritmo de selección de rasgos el cual se puede aplicar a problemas con rasgo de decisión con dominio continuo aplicando adecuadas medidas de correlación [43, 44].
Estudio del método para el problema de aproximación de funciones
En los problemas de clasificación el dominio del rasgo de decisión es discreto, de modo que un clasificador se puede considerar como una función cuya imagen es un conjunto de valores discretos. Mientras en el problema de aproximación de funciones es diferente, pues la imagen de la función es un conjunto continuo. Aunque la RST se ha desarrollado fundamentalmente para problemas de clasificación, también se han desarrollado extensiones de la misma para la aproximación de funciones, como el enfoque denominado "rough real functions" [2]. En [22], los autores discuten el problema de aproximación de funciones usando los conjuntos aproximados. ]]>
Dado el sistema de decisión DS = (U, A⋃{d})donde el dominio del rasgo d son los números reales se desea construir la función F tal que F(0):U →[a,b] donde [a,b]⊆ℜ. En este caso, usualmente los rasgos en A también tienen como dominio los números reales.
En el estudio que se presenta aquí, como aproximador de funciones se utiliza el método K-NearestNeighbours (k-NN). La idea básica el método k-NN es que valores de entradas similares tienen salidas similares [45]. Las salidas de un objeto son computadas promediando las salidas de los vecinos más similares a el. Sea el objeto Xh y el conjunto de objetos más similares denotado por N (Xh), la salida de Xh, denotada por dh, se calcula a partir de N(Xh) usando la expresión (11):
Donde k es la cardinalidad del conjunto N (Xh). Para construir el conjunto N (Xh) es necesario usar una función que permita calcular el grado de similaridad entre dos objetos, en este caso se usa la función definida por la expresión (8). Los resultados presentados en [46] muestran que un aspecto importante en los métodos basados en grados de similaridad, como el método k-NN, es el peso asignado a los rasgos, pues esto mejora significativamente el desempeño del método; allí también se muestra que el empleo de métodos de búsqueda para el calculo de los pesos de los rasgos, obtienen mejores resultados que usar procedimientos de minimización de funciones.
De modo que el método propuesto en este artículo para el cálculo de pesos, también constituye una vía para mejorar el desempeño del método K-NN usado como aproximador de funciones, pues el mismo permite encontrar el conjunto de pesos W usado en la función de semejanza que mejora la recuperación de objetos similares. La importancia de construir la medida de similaridad más adecuada en los sistemas basados en casos, particularmente para resolver problemas de aproximación de funciones, se estudia en [42]. Los resultados experimentales que se presentan seguidamente muestran este desempeño. ]]>
Se utilizan conjuntamente el método K-NN y el método propuesto en la sección 5 para encontrar el conjunto de pesos de los rasgos, al cual se denomina PSO+RST, para resolver el problema de aproximación de funciones en varios ejemplos de sistemas de decisión. El resultado alcanzado por el aproximador de funciones que usa el conjunto de pesos calculado basado en la medida calidad de la semejanza, el método PSO+RST,se compara con otras dos alternativas para el cálculo de los pesos, una consiste en asignar elmismo valor de peso a todos los rasgosllamada método Standard y la otra es el método de cálculo k-NNVSM [47].
Para evaluar la precisión de los resultados alcanzados por ambos métodos se utilizaron tres medidas: (i) Porciento del error medio absoluto (Mean AbsolutePercentage Error, MAPE), (ii) Raíz del error cuadrático medio (Root Mean Square Error, RMSE), y (iii) Promedio de las diferencias entre el valor deseado y el producido por el método (PMD). Estas medidas se definen por las expresiones (12)-(14): Ecua 12 Ecua 13
donde: ai es el valor de salida deseado; yi es el valor producido por el método y N es el número de objetos.
Los sistemas de decisión utilizados se describen en la tabla 1. En todos los casos son datos reales sobre variables meteorológicas provenientes de varias regiones de Cuba localizadas en las provincias de Camaguey y Las Tunas, y el objetivo es pronosticar el valor de la variable cuyo nombre aparece en el nombre del sistema de decisión. ]]>
Para todos los rasgos se utiliza como función de comparación de rasgos la expresión (15):
Para el estudio se utiliza el método k-fold cross-validation, el cual divide el sistema de decisión original en k subsistemas de igual tamaño, y se usa uno como conjunto de prueba y el resto como conjunto de entrenamiento, calculándose la precisión del aproximador como el promedio obtenido en los k conjuntos de prueba; esta técnica elimina diferentes limitaciones de los procesos de aprendizaje [47]. El valor de k utilizado es 10, como se recomienda en [48].
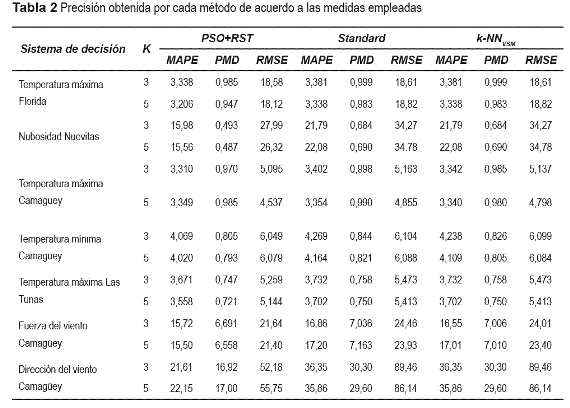
Para el método k-NN se analizaron dos alternativas para k (3 y 5). Los resultados de las medidas MAPE, RMSE y PMD para cada alternativa se presentan en la tabla 2.
Seguidamente se aplicaron pruebas estadísticas no paramétricas para evaluar la comparación.
El Test de Wilcoxon fue usado para evaluar si las diferencias representaban mejoras estadísticamente significativas. El método de Monte Carlo fue aplicado con un intervalo de confianza de 99%, se consideraron los siguientes valores para el valor de p: ]]>
i) significativo → significación menor que 0,05 y mayor que 0,01;
ii) altamente significativo → una significación menor que 0,01;
iii) poco significativo → un resultado menor que 0,1 y mayor que 0,05;
No significativo → un resultado mayor que 0,1.
La tabla 3 muestra los resultados del Test Wilcoxon para cada sistema de decisión. Este análisis estadístico sostiene que el método PSO+RST supera significativamente las otras alternativas.
]]>
Conclusiones
La Teoría de los conjuntos aproximados ofrece diferentes técnicas para el análisis de los datos, en este contexto se propone en este artículo la medida calidad de la similaridad, la cual está diseñada para el caso de que los sistemas de decisión incluyen rasgos continuos, especialmente si el rasgo de decisión tiene dominio continuo. Su aplicabilidad fue analizada para los casos de construir relaciones de similaridad cuando se trabaja con extensiones de la RST y realizar el cálculo de los pesos de los rasgos en procesos de selección de rasgos.
Se analizó experimentalmente como el empleo del método para el cálculo de los pesos basado en la medida calidad de la similaridad permite mejorar el desempeño del método k-NN en el problema de aproximación de funciones.
Referencias
1. Z. Pawlak. "Rough Sets". International journal of Computer and Information Sciences. Vol. 11. 1982. pp. 341-356. [ Links ]
2. Z. Pawlak. "Rough sets, Rough function and Rough calculus". Rough Fuzzy Hybridization: a new trend in decision-making. Ed. Springer-Verlasg. Berlin. 1999. pp. 235-246. [ Links ]
3. Z. B. Xu. "Inclusion degree: a perspective on measures for rough set data analysis." Information Sciences. Vol. 141. 2002. pp. 227-236. [ Links ]
4. F. E. Tay, L. Shen. "Economic and financial prediction using rough set model." European Journal of Operational Research. Vol. 141. 2002. pp. 641-659. [ Links ]
5. S. K. Pal, A. Skowron. Rough Fuzzy Hybridization: A New Trend in Decision-Making. Ed. Springer-Verlag. Singapore. 1999. pp. 389. [ Links ]
6. N. Zhong, J. Dong, S. Ohsuga, "Using Rough sets with heuristics for feature selection." Journal of Intelligent Information System. Vol. 16. 2001. pp. 199-214. [ Links ]
7. R. Jensen, S. Qiang. Finding rough sets reducts with Ant colony optimization. in UK Workshop on Computational Intelligence. Edinburgh (UK). 2003. pp. 15-22. [ Links ]
8. P. R. Bello, Y. Gomez, Y. Caballero, A. Nowe. "Using ACO and Rough set theory to feature selection". WSEAS Transactions on Information Science and Applications. Vol. 2. 2005. pp. 512-517. [ Links ]
9. X. Wang. "Rough set feature selection and rule induction for prediction of malignancy degree in brain glioma." Computer methods and programs in biomedicine. Vol. 83. 2006. pp. 147-156. [ Links ]
10. X. Wang. "Feature selection based on rough sets and particle swarm optimizatio ". Pattern Recognition Letters. Vol. 28. 2007. pp. 459-471. [ Links ]
11. Y. Caballero, R. Bello. Feature selection algorithms using Rough set theory.in Seventh Int. Conf. on Intelligence Systems Design and Applications ISDA07. IEEE Computer Society. Rio de Janeiro. 2007. pp. 407-411 [ Links ]
12. P. R. Bello, Y. Gomez, A. Puris, R. Falcon. Feature selection through Dynamic Mesh Optimization. Lecture Notes on Computer Science. 2008. pp. 348-355. [ Links ]
13. Y. Gomez, R. Bello, A. Puris. "Two step Swarm intelligence to solve the feature selection problem". Journal of Universal Computer Science. Vol. 14. 2008. pp. 2582-2596. [ Links ]
14. G. H. John. Relevant features and the subset selection problem. in Proceedings of the Eleventh International Conference on Machine Learning. Ed. Morgan Kaufmann. 1994. pp. 121-129. [ Links ]
15. I. Inza. "Feature subset selection by bayesian networks based optimization." Artificial intelligence. Vol. 123. 2000. pp. 157-184. [ Links ]
16. H. Xing, L. Xu. "Feature space theory -a mathematical foundation for data mining." Knowledge-based systems. Vol. 14. 2001. pp. 253-257. [ Links ]
17. J. Stefanowski. "An experimental evaluation of improving rule based classifiers with two approaches that change representations of learning examples." Engineering Applications of Artificial Intelligence. Vol.17. 2004. pp. 439-445. [ Links ]
18. P. Somol, P. Pudil. "Feature selection toolbox." Pattern Recognition. Vol. 35. 2002. pp. 2749-2759. [ Links ]
19. M. Dong, R. Kothari. "Feature subset selection using a new definition of classifiability." Patter Recognition Letter. Vol. 24. 2003. pp. 1215-1225. [ Links ]
20. M. Kudo, J. Sklansky. "Comparison of algorithms that select features for pattern classifiers." Pattern Recognition. Vol. 33. 2000. pp. 25-41. [ Links ]
21. H. Zhang, G. Sun. "Feature selection using tabu search method." Pattern Recognition. Vol. 35. 2002. pp. 710-711. [ Links ]
22. Z. Pawlak. Approximating functions using rough sets. in Proceedings of 2004 Annual Meeting of the North American Fuzzy Information Processing Society NAFIPS. 2004. pp. 785-790 [ Links ]
23. Z. Pawlak,A. Skowron. "Rough sets: Some extensions." Information Sciences. Vol. 177. 2007. pp. 28-40. [ Links ]
24. R. Slowinski, D. Vanderpooten. "Similarity relation as a basis for rough approximations." Advances in Machine Intelligence & Soft-Computing. P. P. Wang, (editor) Ed. Duke University Press. Vol. 4. Durham. 1997. pp. 17-33. [ Links ]
25. Y. Yao. "Relational interpretations of neighborhood operators and rough set approximations operators". Information Sciences. Vol. 101. 1998. pp. 239-259. [ Links ]
26. R. Slowinski, D. Vanderpooten. "A generalized definition of rough approximations based on similarity". IEEE Transactions on Data and Knowledge Engineering. Vol. 12. 2000. pp. 331-336. [ Links ]
27. S. Greco. "Rough sets theory for multicriteria decision analysis. " European Journal of Operational Research. Vol. 129. 2001. pp. 1-47. [ Links ]
28. A. Skowron, R. Swiniarski, P. Synak. "Approximation Spaces and Information Granulation". Transactions on Rough Sets III. Lecture Notes in Computer Science. J. F. Peters and A. Skowron, (editors). Ed. Springer-Verlag GmbH. 2005. pp. 175-189. [ Links ]
29. K. Qin, Y. Gao, Z. Pei. "On Covering Rough Sets." Lectures Notes on Artificial Intelligence.Vol 4481. 2007. pp. 34-41. [ Links ]
30. A. Skowron, J. Stepaniuk. "Tolerance approximation spaces."Fundamenta Informaticae. Vol. 27. 1996. pp. 245-253. [ Links ]
31. Y. Yao. "On generalizing Rough set theory." Lectures Notes on Artificial Intelligence. Vol. 2639. 2003. pp. 44-51. [ Links ]
32. W. Zhu, F. Wang. Relations among three types of covering rough sets.in IEEE GrC. Atlanta, USA. 2006. pp. 43-48. [ Links ]
33. D. Bianucci, G. Cattaneo, D. Ciucci. "Entropies and Co- entropies of coverings with applications to incomplete information systems."Fundamenta Informaticae. Vol. 75. 2007. pp. 77-105. [ Links ]
34. N. H. Son, N. S. Hoa. "Discretization of real value attributes for control problems." Workshop on Robotics, Intelligent Control and Decision Support Systems, PJWSTK.Ed. Warsaw. Varsovia (Poland). 1999. pp. 47-52. [ Links ]
35. N. H. Son, N. S. Hoa. "An application of discretization methods in control." Proc. Of the Workshop on Robotics, Intelligent Control and Decision Support Systems. Polish-Japanese Institute of Information Technology. Ed. Warsaw. Poland. 1999. pp. 47-52. [ Links ]
36. J. Kennedy, R. C. Eberhart.Particle swarm optimization. in In Proceedings of the 1995 IEEE International Conference on Neural Networks. Piscataway. IEEE Service Center. New Jersey. 1995. pp. 1942-1948. [ Links ]
37. F. Herrera, M. Lozano, A. Sanchez. "A Taxonomy for the Crossover Operator for Real Coded Genetic Algorithms: An Experimental Study." International Journal of Intelligent Systems. Vol. 18. 2003. pp. 309-338. [ Links ]
38. M. García Martínez, F. Herrera. "Global and local real-coded genetic algorithms based on parent-centric crossover operators."European Journal of Operational Research.Vol. 185. 2008. pp. 1088-1113. [ Links ]
39. K. E. Parsopoulos, M. N. Vrahatis. "Recent approaches to global optimization problems through Particle Swarm Optimization." Natural Computing. Vol. 1. 2002. pp. 235-306. [ Links ]
40. M. Reyes Sierra, C. C. Coello. "Multi-objective Particle Swarm Optimizers: A survey of the State-of-the-Art." International Journal of Computational Intelligence Research. Vol. 2. 2006. pp. 287-308. [ Links ]
41. Z. Zhang, Q. Yang. Dynamic refinement of feature weights using quantitative introspective learning. in In Proceedings of the 16th International Joint Conference on Artificial Intelligence (IJCAI99). 1999. pp.57-71 [ Links ]
42. A. Stahl. "Learning Feature Weights from Case Order Feedback." Lecture Notes in Computer Science Springer. Vol. 2080. 2001. pp. 502-516. [ Links ]
43. M. A. Hall. Correlation-based feature selection for machine learning, inDeparment of Computer Science. University of Waikato: Hamilton. New Zealand. 1998. pp. 145. [ Links ]
44. M. A. Hall. Feature selection for discrete and numeric class machine learning. University of Waikato: Hamilton. New Zealand. 1999. [ Links ]
45. R. L. López, E. Armengol. "Machine learning from examples: Inductive and Lazy methods." Data & Knowlege Engineering. Vol. 25. 1998. pp. 99-123. [ Links ]
46. W. Duch, K. Grudzinski. Weighting and selection features. Intelligent Information System VIII.in Proceedings of the Workshop held in Ustron. Ustron, Poland. 1999. pp.32-36 [ Links ]
47. T. Mitchell. Machine Learning. Ed. McGraw Hill. Portland, OR, USA. 1997. pp. 414. [ Links ]
48. J. Demsar. "Statistical comparisons of classifiers over multiple data sets.". Journal of Machine Learning Research. Vol. 7. 2006. pp. 1-30. [ Links ]
(Recibido el 23 de Agosto de 2010. Aceptado el 20 de junio de 2011)
]]>198211341-3561999235-2462002141227-2362002141641-6591999389200116199-214200315-2220052512-517200728459-4712007407-4112008348-3552008142582-25961994121-1292000123157-184200114253-257200417439-4452002352749-27592003241215-122520003325-41200235710-7112004785-790200717728-401997417-331998101239-259200012331-33620011291-472005175-1892007448134-41199627245-2532003263944-51200643-4820077577-105199947-52199947-521995New Jersey 1942-1948200318309-33820081851088-111320021235-30620062287-308199957-7120012080502-5161998145199919982599-123199932-361997414200671-30
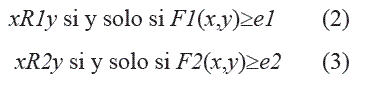
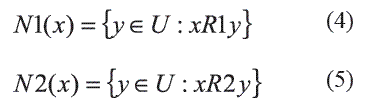
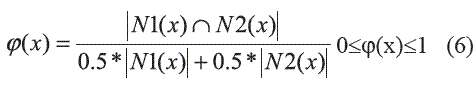
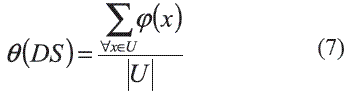
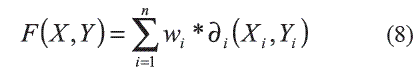
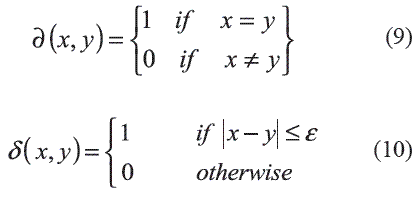

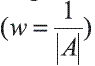 llamada método Standard y la otra es el método de cálculo k-NNVSM [47].
llamada método Standard y la otra es el método de cálculo k-NNVSM [47].