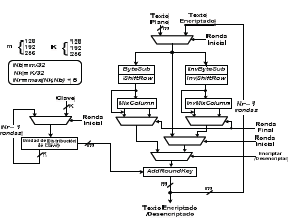
Figura 1. Diagrama de bloques de AES
Figure 1. AES Block diagram
ASYNCHRONOUS IMPLEMENTATION OF RIJNDAEL ALGORITHM´S MIXCOLUMN AND INVMIXCOLUMN FUNCTIONS
RUBÉN DARIO NIETO LONDOÑO
Escuela de Ingeniería Eléctrica y Electrónica, Facultad de Ingenierías, Universidad del Valle, rnieto@univalle.edu.co
ÁLVARO BERNAL NOREÑA
Escuela de Ingeniería Eléctrica y Electrónica, Facultad de Ingenierías, Universidad del Valle alvaro@univalle.edu.co
Recibido para revisar Diciembre 9 de 2008, aceptado Julio 17 de 2009, versión final Agosto 26 de 2009
PALABRAS CLAVE: AES, Balsa, circuitos asíncronos, criptografía, FPGAs, protocolo de sincronismo.
ABSTRACT: This article presents the results of an asynchronous implementation of Rijndael Algorithm MixColumn and InvMixColumn transformation functions in FPGA (Field Programmable Gate Array). The methodology used for implementing asynchronous circuits is provided by the tool known as Balsa, which allows description, synthesis, and asynchronous functional simulation of digital circuits. Results are presented by comparing area and performance of two different architectures, which execute both encryption and decryption processes. The first architecture deploys the functions without optimization, whereas the second one executes encryption and decryption processes utilizing shared hardware resources for the two functions. The codification protocols, dual-rail and 1-of-4, are implemented in all asynchronous transformations.
KEYWORDS: AES, Balsa, asynchronous circuits, cryptography, FPGAs, handshake.
1. INTRODUCCIÓN
En enero de 1997, el Instituto Nacional de Estándares y Tecnología de Estados Unidos, NIST (National Institute of Standards and Technology) [1], realizó una convocatoria con el fin de establecer un nuevo algoritmo para el estándar AES (Advanced Encryption Standard) del FIPS (Federal Information Processing Standard) [2], y reemplazar e l antiguo estándar de encriptación DES (Data Encrytion Standard).
En octubre del 2000 el NIST, después de dos rondas de evaluación a 15 algoritmos candidatos, seleccionó el algoritmo de Rijndael como el nuevo estándar AES.
Son muchas las arquitecturas de circuito propuestas para el algoritmo AES; se ha evaluado su desempeño usando librerías de Circuitos Integrados.
De Aplicación Específica (ASICs: Application Specific Integrated Circuits) y FPGAs (Field Programmable Gate Arrays). La mayoría de las propuestas se han focalizado en obtener ahorro de área y en obtener mayor velocidad, algunas están dirigidas a reducir el consumo de potencia. Desde el punto de vista de seguridad, con el desarrollo de los ataques del lado de canal [3], han sido pocas las propuestas de arquitecturas orientadas a mejorar la resistencia a tales ataques y a la vez disminuir el consumo de potencia. La metodología de diseño asíncrono constituye una alternativa importante para mejorar la seguridad del algoritmo contra los llamados ataques de Análisis de Potencia Diferencial (DPA: Differential Power Analysis) [4].
]]> Muchas de las implementaciones del algoritmo de Rijndael realizan de manera separada las transformaciones MixColumn e InvMixColumn y sólo en algunas publicaciones, [5]-[9], se presentan resultados sobre implementaciones en las que estas funciones comparten recursos lógicos a diferentes niveles. Este trabajo tiene como objetivo presentar los resultados de la implementación asíncrona de las funciones MixColumn e InvMixColumn del estándar AES. Las implementaciones de las funciones se realizaron de manera independiente y también compartiendo recursos, para este caso se implementó la función EDMixColumn. En los diseños se utilizó el estilo de diseño asíncrono usando para ello la herramienta de síntesis asíncrona conocida como Balsa.La sección dos hace una introducción general del algoritmo de Rijndael y presenta la herramienta Balsa. En la sección tres se realiza un análisis detallado de la función de transformación de columnas para los procesos de encriptación/desencriptación del estándar AES; también se presentan distintas arquitecturas síncronas simplificadas para la implementación de la función EDMixColumn, en particular se hace énfasis en la arquitectura propuesta en [6] para su implementación asíncrona. También se presentan los resultados de la síntesis asíncrona de los circuitos en el sistema Balsa y su implementación en la FPGA Virtex XCV2P30-6ff896 de Xilinx. Finalmente, en la sección cuatro se consignan las conclusiones del trabajo.
2. ALGORITMO DE RIJNDAEL Y HERRAMIENTA DE DISEÑO ASÍNCRONO
El algoritmo de encriptación de Rijndael está compuesto por cuatro funciones de transformación llamadas ByteSub (substitución de byte), ShiftRow (desplazamiento circular de fila), MixColumn (transformación de columna) y AddRoundKey (adición de clave de ronda). El proceso de desencriptación consiste en sustituir las transformaciones utilizadas en la encriptación por sus inversas e invertir el orden de aplicación de dichas transformaciones o funciones matemáticas, en este caso las funciones inversas se denominan InvByteSub, InvShiftRow, InvMixColumn. El diagrama de bloques del algoritmo de Rijndael, mostrado en la figura 1, combina las propuestas realizadas en [10],[11] para su implementación en hardware. Una descripción detallada de estas transformaciones y del algoritmo en general es presentada por los autores del mismo en [12].
Figura 1. Diagrama de bloques de AES
Figure 1. AES Block diagram
En la implementación asíncrona de las funciones de transformación de columna del algoritmo de Rijndael se ha utilizado la herramienta de diseño llamada Balsa. Ésta cubre varias etapas del ciclo de diseño asíncrono y provee medios asíncronos de descripción y modelamiento junto con un medio de simulación funcional [13],[14]. Sin embargo, Balsa es primordialmente un sistema de síntesis, el cual requiere acceder a herramientas CAD (Computer Ayded Design) comerciales para producir una implementación real en silicio o en arreglos de compuertas. Para este propósito, Balsa sólo produce un archivo de tipo lista de nodos (netlist) en formato apropiado para un sistema CAD que soporte la tecnología.
Un circuito descrito en Balsa se puede compilar en una red de comunicación de sincronismo (handshake) compuesta de un conjunto de componentes específicos de la herramienta. Los componentes se conectan a través de canales sobre los cuales toma lugar la comunicación; los canales pueden tener asociados rutas de datos o pueden ser sólo de control.
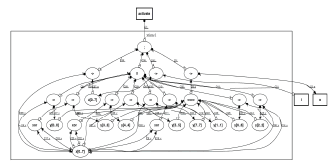
]]> La figura 2 ilustra un ejemplo de un diagrama de circuito conformado por componentes de handshake. Aquí se muestra un componente fetch (u operador de transferencia) denotado por '®' y un componente Case denotado por '@' conectados por medio de un canal orientado a datos. La acción del circuito es activada por un evento de solicitud (request) al componente fetch el cual a su vez establece un request a su entorno (al lado izquierdo del diagrama). El entorno provee el dato solicitado e indica su validez con una señal de reconocimiento (acknowledge). El componente fetch presenta el dato y una señal de request al componente Case usando un puerto activo (mostrado como un círculo negro), estos son recibidos en el puerto pasivo de Case (mostrado como círculo en blanco). Dependiendo del valor del dato, el componente Case establece un handshake en su entorno sobre el puerto inferior y superior del lado derecho. Finalmente, la señal de acknowledge es recibida por el componente Case, se retorna otro acknowledge a lo largo del canal original terminando así el handshake. Los protocolos de handshake utilizados en la comunicación entre módulos hacen que los circuitos asíncronos tengan la propiedad de ser insensibles a los retardos. Gracias a ello, han aparecido metodologías de diseño asíncrono como la que utiliza circuitos Casi Insensibles a los Retardos, QDI (Quasy Delay Insensitive). Esta metodología permite disminuir el consumo de potencia dinámica y hace que la implementación sea resistente a los ataques del lado de canal como por ejemplo el análisis de potencia diferencial DPA (Differential Power Analisys), tal como se reporta en [4],[15]. Los circuitos QDI controlan en forma precisa el número de transiciones eléctricas involucradas en una operación particular logrando, de esta manera, mejorar la seguridad del hardware contra los ataques DPA.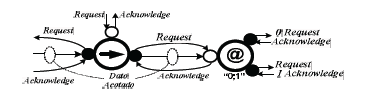
Figura 2. Conexión de componentes de handshake, Ref. [13],[14]
Figure 2. Connected handshake components, Ref. [13],[14]
3. TRANSFORMACIONES DE COLUMNA
3.1 Transformación MixColumn
Esta transformación opera columna por columna sobre el bloque de datos de entrada (llamado matriz de estado), tratando cada columna como un polinomio de cuatro términos. Las columnas son consideradas como polinomios sobre GF(28) (Galois Fields) y multiplicados módulo x4 +1 con un polinomio fijo c(x), dado por:
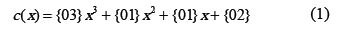
La anterior ecuación se puede escribir como la multiplicación de matrices siguiente:
]]>
Los bytes de cada columna se pueden reemplazar por el resultado obtenido de la multiplicación de acuerdo con las siguientes expresiones:
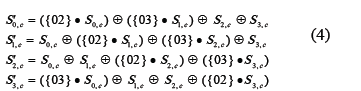
Las ecuaciones (4) muestran multiplicaciones de polinomios por potencias de x en GF(28). Estas operaciones corresponden a multiplicaciones módulo un polinomio binario irreducible de grado 8 llamado m(x) [12] dado por:
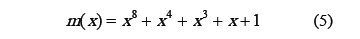
Para facilitar la implementación de la transformación MixColumn en hardware, los autores del algoritmo definieron la función llamada xtime, la cual simplifica la operación de un polinomio por potencias de x. Esta función consiste en aplicar un desplazamiento a la izquierda al valor que representa el polinomio además de una operación XOR con 1B16 (000110112) cuando el resultado de la multiplicación deba ser reducido módulo m(x). Sea el polinomio definido por:
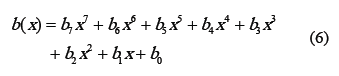
Al realizar la operación modular de (6) con m(x) se obtiene una expresión que permite implementar el circuito para xtime a nivel de bits de la siguiente manera:
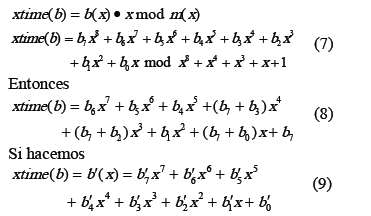
De (8) y (9) se deduce que:
]]>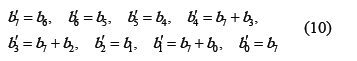
La figura 3 representa el circuito combinatorio de la función xtime a nivel de bits implementado de acuerdo con los términos deducidos.
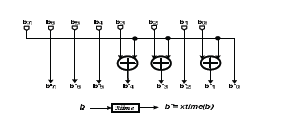
Figura 3. Circuito de función xtime, Ref. [8],[16]
Figure 3. Xtime function circuit, Ref. [8],[16]
Se pueden realizar multiplicaciones por potencias mayores de x mediante la aplicación repetida de xtime.
La figura 4 muestra el código para la especificación asíncrona del circuito que implementa la función xtime en Balsa. Al realizar la síntesis del código se genera el circuito de handshake mostrado en la figura 5. Los diagramas de handshake generados son muy densos en detalles y de difícil comprensión, sin embargo se han incluido en este artículo para ofrecer al lector una idea general de su función.

Figura 4. Código de función xtime
Figure 4. Xtime function code
Las ecuaciones (4) muestran multiplicaciones de polinomios por potencias de x (representadas por los coeficientes 0216 y 0316). Como en GF(28) la multiplicación es distributiva respecto de la adición, se puede reescribir la multiplicación de dos elementos como una combinación lineal de productos, por ejemplo:
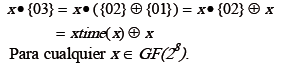
La anterior distribución permite implementar fácilmente el circuito que realiza la transformación MixColumn a partir de (4) tal como se aprecia en la figura 6. Las figuras 7 y 8 muestran, respectivamente, el código Balsa y el diagrama de handshake correspondiente.
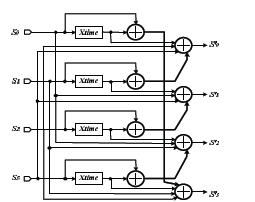
Figura 6. Circuito para la transformación MixColumn, Ref. [10].
Figure 6. Circuit for MixColumn transformation, Ref. [10].
 ]]>
Figura 7. Código de MixColumn
]]>
Figura 7. Código de MixColumn
Figure 7. MixColumn Code
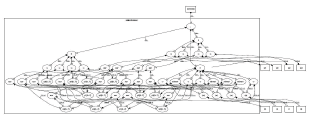
Figure 8. Handshake de MixColumn
Figure 8. MixColumn handshake
3.2 Transformación InvMixColumn
InvMixColumn es la inversa de la transformación MixColumn, y opera sobre la matriz de estado columna por columna, tratando cada columna como un polinomio de cuatro términos. Las columnas son consideradas como polinomios sobre GF(28) multiplicados módulo x+1 con un polinomio fijo c-1(x), en adelante llamado d(x), dado por:
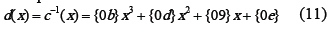
La ecuación (11) se puede escribir como una multiplicación de matrices de la siguiente forma:
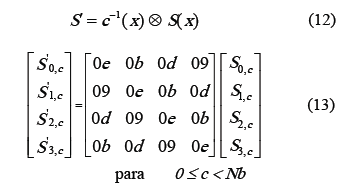
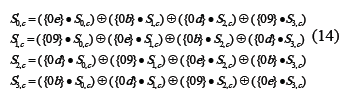
Nuevamente, basados en el hecho que en GF(28) la multiplicación es distributiva respecto de la adición, el coeficiente 0b16 multiplicado por x, por ejemplo, se puede descomponer así:
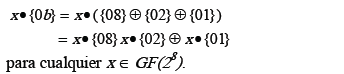
Teniendo en cuenta el ejemplo anterior, los coeficientes 0916,0b16,0d16,0e16 en (14) se pueden expresar como sumas de elementos en potencias de dos, lo cual facilita la implementación del circuito que genera tales coeficientes a partir de la apropiada interconexión de circuitos xtime. El circuito mostrado en la figura 9 es un multiplicador que genera los coeficientes requeridos y constituye la base de la implementación del circuito para InvMixColumn.
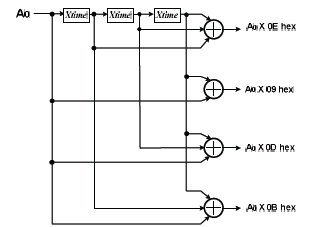
Figura 9. Multiplicador para InvMixColumn. Ref. [10]
Figure 9. Multiplier for InvMixColumn. Ref. [10]
La especificación en Balsa del multiplicador y el diagrama de handshake resultante se observan en las figuras 10 y 11 respectivamente.
 ]]>
Figura 10. Código del multiplicador
]]>
Figura 10. Código del multiplicador
Figure 10. Multiplier code
Figura 11. Handshake de multiplicador
Figure 11. Multiplier handshake
Como la transformación InvMixColumn opera sobre una columna a la vez, se requieren cuatro circuitos multiplicadores para realizar la transformación en paralelo de los cuatro bytes de la columna. Otra opción de diseño para InvMixColumn consiste en implementarla de manera secuencial pero, como se verá en la sección 3.3, a pesar que tal opción permite el ahorro de puertas la velocidad será menor que la implementación en paralelo.
El código en Balsa para InvMixColumn, mostrado en la figura 12, hace uso de cuatro multiplicadores (mult_GF), cuyas salidas se conectan como entradas a las diferentes puertas XOR de salida, tal como lo expresan las ecuaciones en (14). La figura 13 muestra el diagrama de handshake correspondiente. En este diagrama se observa al operador paralelo '||' conectando los cuatro procesos asociados con los multiplicadores y sus conexiones de handshake con las variables internas. Las variables a su vez indican las conexiones hacia las puertas XOR y las salidas respectivas.

Figura 12. Código de InvMixColumn
Figure 12. InvMixColumn Code
El circuito para realizar la transformación InvMixColumn (mostrado en la figura 14) se deduce de la ecuación (14) teniendo como base las salidas del multiplicador.
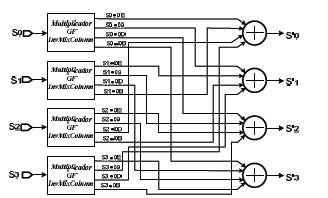
Figura 14. Circuito para transformación InvMixColumn. Ref. [10]
Figure 14. Circuit for InvMixColumn transformation. Ref. [10]
3.3 Transformación de columna para encriptación/desencriptación
De las ecuaciones (4) y (14) se puede ver que los coeficientes de d(x) son más complejos que los de c(x), por lo que la implementación hardware de la transformación InvMixColumn es más compleja, más lenta y ocupa mayor área que la transformación MixColumn. Al Implementar un circuito para encriptar/desencriptar, como se ilustra en la figura 15, el costo en hardware es alto si se utilizan ambas transformaciones por separado.
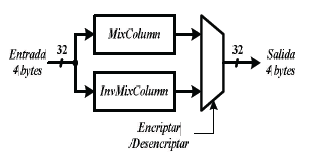 ]]>
Figura 15. Circuito para transformación de columna sin optimización.
]]>
Figura 15. Circuito para transformación de columna sin optimización.
Figure 15. Circuit for column transformation without optimization
Para reducir el costo del hardware, la transformación InvMixColumn se puede descomponer en forma serial para que comparta recursos lógicos con MixColumn a nivel de palabras de 32 bits. Esta idea se ha planteado en varias publicaciones [6],[8],[9].
En [6] se analiza, además, una descomposición paralela de InvMixColumn.
3.3.1 Descomposición paralela de InvMixColumn, EDMixColumn_paralelo
Esta idea, propuesta por [17], se basa en el hecho que d(x) se puede expresar usando c(x) de la siguiente manera:
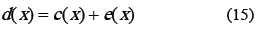
Donde e(x) es una extensión polinomial definida como:
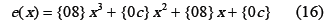
3.3.2. Descomposición serial de InvMixColumn, EDMixColumn_serie ]]> Propuesta en [6], esta idea se sustenta en el hecho que el inverso d(x) está dado por la fórmula:
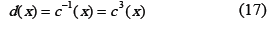
Esta ecuación sugiere que la operación InvMixColumn se puede realizar repitiendo tres veces MixColumn. La ecuación (17) se puede expresar como:
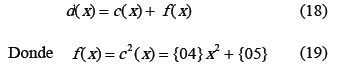
De esta ecuación se deduce que la transformación InvMixColumn puede implementarse usando la función MixColumn y el polinomio f(x). Al comparar f(x) con c(x), dada en (1), se puede ver que f(x) es más simple por cuanto dos de sus coeficientes son cero. La ecuación (19) también se obtuvo en [18] de la siguiente forma:
Ya que

Si se multiplica a ambos lados de (20) por d(x) se obtiene:
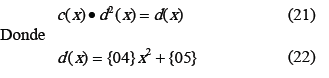
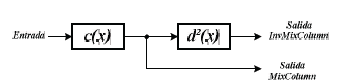
La ecuación (22) se puede implementar en hardware como se muestra en la figura 16.
]]>
Los circuitos para descomposición serial y descomposición paralela de InvMixColumn [6], se aprecian en las figuras 17 y 18 respectivamente, en ambos casos se observa la implementación de la función MixColumn encerrada en líneas punteadas.
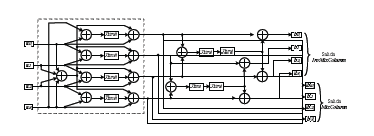
Figura 17. EDMixColumn basada en descomposición serial de InvMixColumn, Ref. [6].
Figure 17. EDMixColumn based on InvMixColumn serial decomposition. Ref. [6].
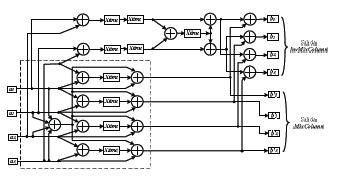
Figura 18. EDMixColumn basada en descomposición paralela de InvMixColumn, Ref. [6].
Figure 18. EDMixColumn based on InvMixColumn parallel decomposition. Ref. [6].
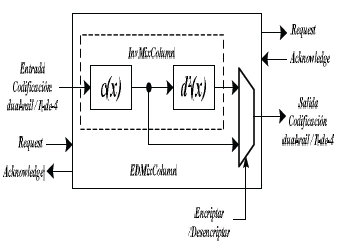
Figura 19. Arquitectura de EDMixColumn
Figure 19. EDMixColumn architecture
Los diagramas de handshake generados en Balsa para EDMixColumn_serie y EDMixColumn_paralelo, son más densos en detalles que los diagramas mostrados en secciones anteriores, por lo cual se omiten en este trabajo. Sin embargo, para el lector interesado en realizar un análisis más detallado, estos diagramas junto con otros aspectos importantes pueden ser consultados en [13].
3.5 Resultados
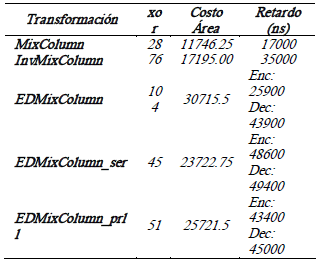
La tabla 1 muestra los resultados obtenidos de las implementaciones asíncronas tanto para las arquitecturas tradicionales MixColumn e InvMixColumn de 128 bits, como para las implementaciones basadas en las arquitecturas serial y paralela desarrolladas en [6].
Tabla 1: Costo de área y retardo de simulación funcional para MixColumn, InvMixColumn y EDMixColumn asíncronas.
Table 1: Area cost and functional simulation delay for asynchronous MixColumn, InvMixColumn and EDMixColumn. ]]>
La utilidad breeze-cost de Balsa, se ha usado para estimar el área ocupada por cada circuito de handshake en los diseños realizados. Las unidades retornadas por breeze-cost son micrómetros (µm) lineales de celdas estándar sobre un viejo proceso 2LM CMOS de 1µm; la precisión de los valores es relativa al tamaño de las celdas usadas por breeze-cost, no a la precisión de estimación de breeze-cost. Las celdas primarias de esta librería básica presentan una grilla (pitch) de 45µm, adicionando un 50% de espacio de ruteo extra (el cual es típicamente requerido en los procesos 2LM) [19].
La implementación de la transformación EDMixColumn se hizo integrando las funciones MixColumn e InvMixColumn mediante un multiplexor y sin compartir recursos, por lo cual el número de puertas usadas, respecto de las transformaciones EDMixColumn serie y paralela, es mayor. Sin embargo, como se observa en la tabla 1, también presenta menor retardo en los procesos de encriptación/desencriptación.
Aunque las funciones EDMixColumn_serie y EDMixColumn_paralelo requieren de menos compuertas que la función EDMixColumn, éstas presentan mayores retardos debido a que las señales deben recorrer un número mayor de niveles de puertas. Además, debido a que la comunicación se realiza por medio de protocolos de handshake, la diferencia de retardos se hace más significativa.
Balsa soporta las tecnologías AMS de 350nm y SGS-ST de 180nm, las cuales generan formatos del tipo 'netlist' para producir implementaciones en Silicio. Balsa también soporta la tecnología apropiada para producir formatos utilizados en FPGAs de Xilinx. Los resultados de la implementación en FPGA usando los protocolos asíncronos de codificación dual-rail de dos fases y 1-de-4, se observan en la tabla 2.
Tabla 2: Resultados de implementación en Virtex XCV2P30-6ff896 de Xilinx
Table 2: Implementation results in Xilinx`s Virtex XCV2P30-6ff896

Los retardos en ambos tipos de codificación se distribuyen entre las rutas de interconexión y las puertas lógicas que conforman cada circuito. Se puede observar que alrededor del 58% de los retardos en los circuitos son introducidos por las rutas de interconexión de la FPGA, lo cual refleja un enorme esfuerzo por parte de las herramientas de ruteo al tratar de equilibrar los tiempos de retardo sobre rutas de igual longitud y garantizar así la ausencia de riegos estáticos. Lo anterior es una evidencia de que los recursos de interconexión de las FPGAs comerciales están concebidos para aplicaciones que usan el tradicional estilo de diseño síncrono y no el estilo asíncrono.
En la literatura no hemos encontrado reportes de resultados de implementaciones asíncronas del estándar AES sobre FPGAs. Hasta el momento sólo se han reportado dos implementaciones asíncronas del algoritmo basadas en ASICs las cuales solo reportan resultados para el proceso de encriptación y cuyos retardos, como es de esperarse, son mucho menores, que los obtenidos en este trabajo:
]]> en [4] se reporta una arquitectura QDI balanceada con codificación 1-de-N y un retardo máximo de 850ns; en [15] se reporta una arquitectura pipeline con codificación dual-rail con un retardo máximo de 800ns. Estos reportes no mencionan resultados de rendimientos de bloques individuales del algoritmo.
4. CONCLUSIÓN
El trabajo realizado constituye el primer esfuerzo para lograr la implementación asíncrona de las funciones de transformación de columna del algoritmo de Rijndael usando para ello herramientas de síntesis automática de circuitos sobre FPGAs de Xilinx. A pesar de la buena integración ofrecida por el sistema Balsa con el paquete ISE de Xilinx para lograr la implementación circuitos asíncronos, dichas implementaciones presentaron retardos elevados debido a que el mayor porcentaje de retardo lo introducen las rutas de interconexión de las FPGAs comerciales utilizadas.
Es claro que, dadas las condiciones de avance de las herramientas de diseño asíncrono, parte del trabajo futuro debe orientarse en el corto plazo a estudiar estrategias que permitan adecuar eficientemente las plataformas comerciales a las metodologías asíncronas existentes.
REREFENCIAS
[1] NIST, National Institute of Standards and Technology. 2000. Disponible en: http://csrc.nist.gov/CryptoToolkit/aes/rijndael [ Links ]
[2] FIPS, Federal Information Processing Standards, Specification for the ADVANCED ENCRYPTION STANDARD (AES). Publication 197, November 26, 2001. [ Links ]
[3] KURLD and SCARD Consortium. Intermediate report, Side Channel Analysis Resistant Design Flow. SCARD, Information Society, Project Number: IST-2002-507270, 15 January 2005. [ Links ]
[4] BOUESSE, RENAUDIN, F. M. and GERMAIN, F. Asynchronous AES Crypto-Processor Including Secured and Optimized Blocks. TIMA Laboratory, Grenoble, France ; SGDN/DCISS, Paris, France . Journal of Integrated Circuits and Systems, Vol 1, No 1, pp 5-13. March 2004. [ Links ]
[5] SATOH, A., MORIOKA, S., TAKANO, K., and MUNETOH, S. A Compact Rijndael Hardware Architecture with S-Box Optimization. Advances in Cryptology - ASIACRYPT 2001, LNCS Vol. 2248, pp. 239-254, 2001. [ Links ]
[6] FISCHER, V., DRUTAROVSKÝ, M., CHODOWIEC, P. and GRAMAIN, F. InvMixColumn Decomposition and Multilevel Resource Sharing in AES Implementations. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, Vol. 13, No 8, August 2005. [ Links ]
[7] CHODOWIEC, P., and GAJ, K. Very Compact FPGA Implementation of the AES Algorithm. CHES 2003. [ Links ]
[8] HUANG, Y.H., LIN, Y.S., HUNG, K.Y., and LIN, K.C. Efficient Implementation of AES IP. IEEE, Asia Pacific, Conference on Circuits and Systems APCCAS-2006, pp 1418-1421. Dec 2006 [ Links ]
[9] HSIAO, S.F., CHEN, M.C., and TU, C.H. Memory-Free Low-Cost Designs of Advanced Encryption Standard Using Common Subexpression Elimination for Subfunctions in Transformations. IEEE Trans. on circuits and systems-I: Regular papers, vol. 53, No. 3, pp. 615-626, March 2006. [ Links ]
[10] CORDERO, V., and SILVA, C.. Design of an ASIC CORE for data encryption and decryption Using the NIST Advanced Encryption standard. Microelectronics Group - Pontificia Universidad Católica del Perú. IX Workshop de Iberchip, La Habana, Cuba. 2003. [ Links ]
[11] VERBAUWHEDE, I., SCHAUMONT, P., and KUO, H. Design and performance testing of a 2.29-GB/s Rijndael processor. IEEE Journal of Solid-State Circuits, Volume: 38 Issue:3, March 2003. [ Links ]
[12] DAEMEN, J., and RIJMEN, V. AES Proposal: Rijndael. Proton Worl Int. I, Zweefvliegtuigstraat, Brussel, Belgium ; Katholieke Universiteit Leuven, ESAT-COSIC, Belgium . Document V. 2. 1999. [ Links ]
[13] NIETO, R. Diseño e implementación de un cripto-procesador asíncrono de bajo consumo basado en el algoritmo de Rijndael [Tesis Doctoral]. Cali, Universidad del Valle, 2009. [ Links ]
[14] EDWARDS, D., BARDSLEY, L., Janin, L., and TOMS, W. Balsa: a Tutorial Guide. Version 3.5.The Advanced Processor Technologies Group, APT Group. Manchester University . Manchester, England . 2006. [ Links ]
[15] SHANG, D., et al. High-security asynchronous circuit implementation of AES. IEE Proceedings online no. 20050088, doi:10.1049/ip-cdt: 20050088. IEE Proc.-Comput. Digit. Tech., Vol. 153, No. 2, March 2006. [ Links ]
[16] Li, H., and FRIGGSTAD, Z. An Efficient Architecture for the AES MixColumns Operation. IEEE International Symposium on Circuits and Systems, 2005, ISCAS. Vol. 5, pp. 4637-4640. May 2005. [ Links ]
[17] WOLKERSTORFER, J. An ASIC implementation of the AES MixColumn operation. Proceedings Austrochip 2001, pp. 129-132. Vienna, Austria , Oct. 12, 2001, [ Links ]
[18] CHODOWIEC, P. and GAJ, K. Very Compact FPGA Implementation of the AES Algorithm. CHES 2003, LCNS 2779, pp. 319-333, Springer-Verlag Berlin Heidelberg 2003. [ Links ]
[19] BARDSLEY, A. Implementing Balsa handshake Circuits. [PhD Thesis], University of Manchester, 2000. [ Links ] ]]>