Evaluation of financial management using latent variables in stochastic frontier analysis
Evaluación de la gestión financiera usando variables latentes en modelos estocásticos de fronteras eficientes
Marisol Valencia-Cárdenas a & Jorge Anibal Restrepo-Morales b
a Institución Universitaria Tecnológico de Antioquia, Universidad Nacional de Colombia, Medellín, Colombia. mvalencia@unal.edu.co
b Institución Universitaria Tecnológico de Antioquia, Fundación Universitaria Autónoma de las Américas, Medellín, Colombia. gifatdea@gmail.com
Received: December 11th, 2015. Received in revised form: August 12th, 2016. Accepted: Agosto 20th, 2016
]]>This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Abstract
It is impossible to ascertain the quality of business Management through traditional financial indicators; these alone do not accurately infer about business states in such important aspects as the efficiency of business management. The concept of quality management is very abstract and such quantification underlies latent aspects of areas with no measure, within a structural financial classification. The process proposed in this paper, permits to identify, characterize and determine associations between areas related to the indicators of the CAMEL model (C, Capital Adequacy, A, Assets Quality, M, Management, E, Earnings, L, Liquidity) as latent variables, estimated from a Multivariate Data Analysis technique, the CFA. Using this result, it is estimated a Stochastic Frontier Analysis (SFA), and a model of Data Envelopment Analysis (DEA), whose comparison, analysis and contrast, permits the evaluation of the quality of the management of a Colombian financial sector.
Keywords: Financial Analysis, Latent Variables, Factor Analysis, Stochastic Frontier Analysis
Resumen
No es factible dimensionar la calidad del Management empresarial por medio de los indicadores tradicionales financieros, éstos, por sí solos no permiten inferir con precisión acerca de los estados empresariales, en aspectos tan importantes como la eficiencia de la gestión empresarial. El concepto de calidad del management, es muy abstracto y en su cuantificación subyacen aspectos de áreas latentes, pero no medidas, dentro de una clasificación financiera estructural. El proceso propuesto en este trabajo, permite identificar, caracterizar y determinar asociaciones entre áreas acordes con los indicadores del modelo CAMEL, (C, Capital Adequacy; A, Assets Quality; M, Management; E, Earnings; L, Liquidity), como variables latentes, estimadas a partir de una técnica del Análisis Multivariado de Datos, conocida como Análisis del Factor Confirmatorio. Con dicho resultado se realiza la estimación de un Modelo Estocástico de Fronteras Eficientes (SFA), y un modelo de Análisis de Datos Envolvente (DEA), cuya comparación, análisis y contraste permiten evaluar la calidad del Management de un sector financiero colombiano.
Palabras clave: Análisis Financiero, Variables Latentes, Análisis del Factor, Modelos Estocásticos de Fronteras Eficientes.
1. Introducción
]]> Existen algunos ratios financieros, que permiten describir un estado de gestión financiero, como el indicador de rotación: Ingresos/Activos, que refleja aproximadamente la eficiencia empresarial, pero sin tomar en cuenta otras variables que en conjunto son importantes para la toma de decisiones. En este sentido, el análisis centrado en los indicadores, algunas veces puede llevar a conclusiones erradas sobre el verdadero comportamiento de la empresa, porque son medidas puntuales y determinísticas que no permiten inferir, por ejemplo, sobre tendencias, por sí solos, o incluso, sobre estados relativos de las empresas en comparación con otras de su misma naturaleza.En este orden de ideas, los modelos Estocásticos de Fronteras Eficientes (Stochastic Frontier Analysis-SFA), pueden mejorar el análisis financiero [1-3]. Esta es una técnica econométrica basada en la estimación de máxima verosimilitud para encontrar una función de producción; la eficiencia se mide usando los residuales de la ecuación estimada y el error se divide en dos componentes: el término del error aleatorio y el error sistemático de la ineficiencia [4].
La propuesta para este artículo inicia con la cuantificación de variables latentes, que no se pueden medir de forma directa, pero que es factible valorar usando variables medibles, cuantitativas, que se relacionen con su definición. Para la estimación de las variables latentes, se propone usar la clasificación del modelo CAMEL: C, Capital Adequacy; A, Assets Quality; M, Management; E, Earnings; L, Liquidity; así, cada categoría se asume como una variable latente, y se estiman sus valores, usando una técnica del Análisis Multivariante [5,6]: Análisis de Ecuaciones Estructurales (SEM), que comprende el Análisis del Factor Confirmatorio (CFA). SEM es una técnica útil para identificar asociaciones estadísticas importantes entre las variables observables y las latentes [6,7] que no son observadas directamente. Con lo anterior, se utiliza el output 'Management' para estimar la eficiencia financiera; usando un modelo de fronteras estocásticas (SFA) [1,4,8], cuyos inputs son los demás factores latentes del modelo CAMEL. Sus resultados se comparan con los del modelo DEA, con el mismo output que el utilizado para el SFA; por medios gráficos y de la clasificación clúster para las empresas.
2. Metodología
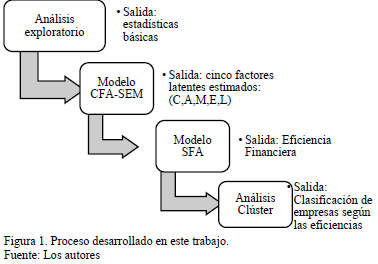
La base informativa está conformada por un conjunto de 109 empresas del sector financiero colombiano, obtenida de la base de datos Benchmark, que proporciona variables financieras por empresa, como las ventas, activos, rentabilidad, con las cuales se pueden construir indicadores como ROA=Utilidad/Activos, etc. Luego de un análisis descriptivo y de eliminar puntos extremos para los indicadores como el ROA, se encuentran 4 empresas con valores inusuales, y se deja una base de 105 empresas. El proceso propuesto se resume en la Fig. 1.
Para todo el análisis se recurre a 48 variables asociadas con la gestión financiera, con las cuales se obtienen también indicadores, tales como: Ingresos/Activos, Utilidad/Activos, Ingresos/Patrimonio, Crecimiento de ingresos, de ventas, Rentabilidades, entre otras.
El paso siguiente es elaborar un diagrama causal sobre las relaciones entre las variables observables cuantitativas, derivadas de la base de datos, y las variables latentes, en este caso, dada la relevancia frente al tema de gestión financiera y sus campos de aplicación, corresponden a las cinco que conforman el modelo CAMEL: Capital Assets, Management, Earnings y Liquidity; con lo cual, se establece la estructura multivariada que permite estimar dichos factores latentes, usando la técnica de SEM. En este proceso, el Análisis del Factor Confirmatorio (CFA), estima los indicadores usando las variables observables, y seguido a esto, se relacionan usando análisis de Regresión, que permite realizar una interpretación de la significancia entre las variables y determinar así, cuáles tienen mayor asociación estadística. De éstos indicadores, la variable latente 'Management' es empleada para realizar una clasificación Clúster, que permite diferenciar empresas según la calidad financiera medida, y a su vez, se usa como respuesta para calcular la eficiencia con el modelo SFA.
Dicha eficiencia se utiliza como insumo de un segundo análisis de clúster [9], donde se agrupan las variables de acuerdo con sus similaridades. Se comparan ambas clasificaciones con el fin de determinar la adecuada segmentación.
]]> 2.1. Modelo CamelUna de las formas de realizar una medición del riesgo de una organización y utilizar dicha medida como proxy de la calidad de la gestión empresarial, es recurrir a la definición del denominado índice CAMEL: C, Capital Adequacy; A, Assets Quality; M, Management; E, Earnings; L, Liquidity. Este modelo es útil en la identificación de crisis financieras o fragilidad, especialmente en bancos [10], cuyo origen es producto de fallas en la gestión de los factores microeconómicos que afectan la organización. Una clasificación CAMEL, entre los valores 3 y 5, considera la organización en problemas o con alto riesgo de quiebra. Los modelos son importantes para monitorear estados financieros y evitar crisis financieras, en especial en el sector bancario [10,11]. Dentro de los principales indicadores del modelo CAMEL se encuentran ratios relativos a los procesos de entradas y salidas en estados financieros, los que se consideran en este trabajo: Crecimientos en diversos indicadores como Activos, ventas, utilidades y patrimonio; rentabilidades, e indicadores de eficiencia tradicional como Ingresos/Activos, Utilidades/Activos, Ingresos/Costos, como lo proponen los autores citados.
2.2. Análisis Clúster
Con esta técnica se calculan las distancias [9,12] entre observaciones: la euclidiana o la de Manhattan. Las euclidianas son la raíz de la suma de cuadrados de diferencias entre puntos, la de Manhattan es la suma de diferencias absolutas, con respecto a unas componentes o vectores elegidos de los datos (medoids). El método pam tiene una función objetivo que es minimizar la suma de las dissimilaridades [9]. En el proceso se renueva la cantidad de elementos por clúster elegido (k), estos se recalculan acorde con el algoritmo, quedando al final una cantidad (ni) de elementos por cada grupo. Elige además un vector en los datos, por clúster que es el referente para estimar las distancias (medoid).
2.3. Análisis de Ecuaciones Estructurales
La técnica de Análisis del Factor Confirmatorio hace parte de los Modelos de Ecuaciones Estructurales (SEM) [6], útil para reducir dimensionalidad en un conjunto de variables, y que permite ajustar dicho conjunto explicando cierto porcentaje de variabilidad conjunto (CFI). Los componentes de estos modelos SEM se resumen así:
Los modelos de Ecuaciones Estructurales (Structural Equation Modeling-SEM) son una familia de modelos estadísticos multivariantes que permiten estimar efectos entre variables observables sobre factores latentes, usando la matriz de covarianzas o de correlaciones [6] y análisis de regresión multivariable.
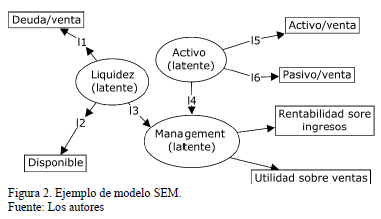
Estos modelos se basan en estructuras gráficas denominadas diagramas causales. Los diagramas representan una posible estructura de asociación entre variables cuantitativas, de forma multivariante. Las variables observables se representan en rectángulos, y las no medibles o latentes, en círculos o elipses (ver ejemplo en Fig. 2).
Las flechas muestran cómo una variable puede ser afectada por otras si la flecha es hacia ella, o puede afectar a otras si la flecha va en otra dirección a ésta. Cuando no se traza tal línea, no se visualiza relación alguna. Algunas de las variables latentes se podrían afectar unas a otras. Las flechas bidireccionales involucran covarianzas entre dos variables.
Estos diagramas facilitan la previsualización de la posible asociación de un modelo multivariante, entre las variables observables y las latentes.
En estos modelos SEM, se consideran en primer lugar, hipótesis de los investigadores para crear dichas asociaciones, y es posible extraer los valores de factores estimados de Management para posteriores estadísticas, como en este caso, el modelo DEA y el modelo SFA.
2.3. Modelos de Fronteras Eficientes
El modelo (DEA), puede definirse como un método que permite estimar las mejores fronteras prácticas de producción y evaluar la eficiencia relativa de diferentes entidades (García, 2009). Pero por su naturaleza determinística, el DEA puede no capturar adecuadamente la medida de dicha eficiencia, por ello, surgen los Modelos Estocásticos de Fronteras Eficientes cuya ecuación general de un está dada por (1):
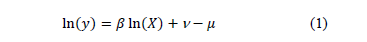
 y con estos, encontrar µ. La estimación se basa en máxima verosmilitud, y es desarrollada en [1].
y con estos, encontrar µ. La estimación se basa en máxima verosmilitud, y es desarrollada en [1].
3. Resultados
3.1. Análisis descriptivo
La base de datos financiera posee en total 109 empresas. Se estiman estadísticas generales, como media, desviación estándar, asimetría, curtosis, entre otras para los ratios como: Ingresos/Activos, Disponible/gasto, entre otros. Se detectan outliers, usando el criterio de puntos extremos izquierda: x<Q1-3*RIQ, derecha: x>Q3+3*RIQ, RIQ es el Rango Intercuartil (Q3-Q1). Luego de depurar la base de datos, queda finalmente con 105 empresas. La estimación del modelo SEM produce los resultados vistos en la Tabla 1.
En las líneas 2 a 5 de la Tabla 1, se muestran los índices que miden qué tan adecuado es el modelo. La estructura de covarianza estimada significativa (P-value (Chi-square) ~0.058*), y la línea de base del modelo también (P-value 0*). Además, la explicación de variabilidad del modelo de CFA es del 95.5% (CFI**) y la desviación del error es de 0.086 (RMSEA***), la cual es muy baja y adecuada. Con esto se afirma que la asociación encontrada entre latentes y observadas, explica de forma adecuada el conjunto completo de datos.
La estructura del modelo, que tiene una asociación significativa, permite ver cómo son los efectos de las covariables en las regresiones estimadas entre Capital con Activos y Management con activos y ganancias. Así, con el análisis CFA, se estiman los valores por cada una de las empresas, para las variables latentes: Capital, Assets, Management, Earnings y Liquidity, para ser usadas en el posterior análisis de SFA. En la Tabla 1 se analizan las significancias y los efectos encontrados por variable latente, mostrando las que son significativas si su valor p es menor del 5%, sin embargo, si los índices de ajuste generales del modelo son adecuados, no hay razones para descartar variables que puedan dar un efecto pequeño en el modelo, o cuya significancia no se refleje, pero, ayudan a identificar un buen resultado conjunto. En la Tabla 2 se interpretan los efectos encontrados.
De los modelos de regresión, se prueban dos hipótesis para el modelo CAMEL: las ganancias (Earnings) hacen incrementar el Management, pero los activos lo disminuyen, y todo el modelo en conjunto es significativo al 10%. La salida principal de dicho proceso es el Management, respuesta que es usada para estimar un modelo estocástico de fronteras eficientes (SFA), a continuación.
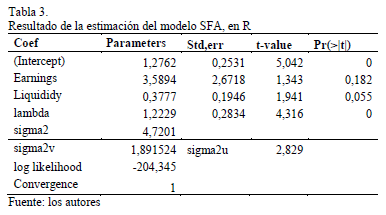
]]> 3.2. Análisis de Fronteras EficientesEl modelo SFA analizado contempla las variables explicativas: Ganancias (Earnings) y Liquidez (Liquidity). Variable respuesta: Management. Los resultados de la estimación se ven en la Tabla 3.
En la Tabla 3 puede observarse que las variables Ganancias (Earnings) y Liquidez (Liquidity) son adecuadas, para explicar el Management, siendo el efecto de ganancias el más alto, aunque tenga un error estándar más alto que la liquidez. Con esto se estiman las eficiencias financieras, que servirán para clasificar el estado de las empresas evaluadas en la muestra.
3.3. Modelos de eficiencia DEA y SFA
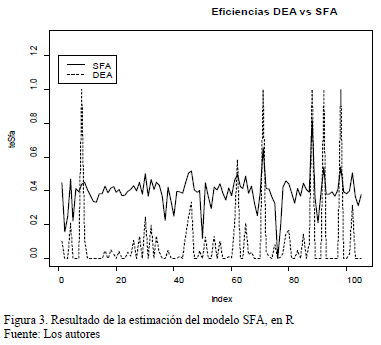
La Fig. 3 muestra el comparativo de los valores de eficiencia estimados con los modelos de Datos Envolventes (DEA) y de fronteras estocásticas (SFA).
Si bien aparentan menores los valores de eficiencia del Modelo DEA, la escala de valores del SFA es también baja, y su varianza no es tan alta como la primera. Sin embargo, hay empresas que aparentan coincidir en los picos de más alta eficiencia entre ambos modelos. Esto refleja que la elección de variables observables fue adecuada para la representación del Management, y por lo tanto, de la eficiencia medida. Todo esto, para determinar que el nivel general de eficiencia financiera no es muy adecuado y el sector debe entonces, encontrar estrategias de mejoramiento para el incremento de sus utilidades. Lo anterior se corrobora con el siguiente Análisis Clúster.
3.4. Análisis de Clúster
Con la eficiencia estimada con el modelo SFA, se clasifican las empresas, usando análisis Clúster. Al comparar los grupos con los del Management, se observan muchas similaridades en ambos casos, y por ello, se muestra la clasificación final basada en la eficiencia de SFA, que se presenta en la Tabla 4. En la última columna se presenta el porcentaje de empresas por grupo.
]]>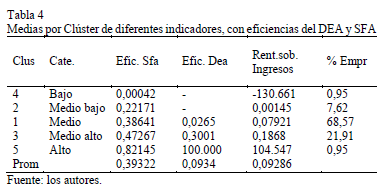
La clasificación tiene una clara diferenciación de los grupos empresariales, que van en niveles de bajo a alto en relación a la eficiencia estimada, con similaridades en los niveles promedio de los dos tipos de eficiencia mostrados: SFA y DEA. Estos niveles muestran una relación directa con las rentabilidades, activos, ROE y ROA, los crecimientos en activos, entre otras (Tabla 1 de asociaciones). Es claro además que la mayoría de las empresas no se encuentran en niveles bajo o alto, muchas se agrupan en nivel medio (68.5%) indicando que hay una alta probabilidad de requerir mejoramientos de eficiencia para el sector.
4. Discusión
La clasificación empresarial realizada permite evaluar la calidad de la eficiencia medida, al agrupar las empresas en una escala ordinal, y comparar con otros indicadores como rentabilidad sobre ingresos. Para lograr dicho resultado, previamente se encontró una adecuada asociación entre variables observables, entre estas, activos, ganancias, capital. La definición teórica del modelo CAMEL facilita la aplicación y asociación mediante los modelos de Análisis del Factor Confirmatorio (CFA) y de Análisis de Ecuaciones Estructurales (SEM), como una herramienta para que quienes se encuentren interesados, evalúen la calidad de la gestión empresarial, no obstante, se evidencia que no siempre será necesario usar todas las variables para un sólo modelo, en otras palabras, pueden existir variables redundantes para explicar la eficiencia empresarial. Este resultado permite a una empresa usar una base de datos observados para encontrar respuesta a diferentes hipótesis que conduzcan al desarrollo de posibles estrategias de mejoramiento de su gestión financiera.
5. Conclusiones
Usando el análisis de ecuaciones estructurales, se obtiene una adecuada asociación de las variables del modelo Camel: crecimiento en activos y utilidades, pero también, de la rentabilidad sobre ingresos, para la respuesta Management, permitiendo una clasificación de las empresas usando análisis clúster. De los modelos de regresión, se prueban dos hipótesis para el modelo CAMEL: las ganancias (Earnings) hacen incrementar el Management, pero los activos lo disminuyen, y todo el modelo en conjunto es significativo al 10%. Lo anterior, corrobora la teoría económica de la racionalidad financiera sustentaba en el concepto de eficiencia, que promulga obtener más con menos. Se deduce que las variables crecimiento en Activos, Patrimonio y Utilidades son las más importantes para la determinación de la calidad del Management con variables latentes. La eficiencia encontrada, logra clasificar las empresas en grupos claramente diferenciados, permitiendo diagnósticos convenientes sobre la gestión financiera.
Referencias
]]>[1] Bogetoft, P. and Otto, L., Benchmarking with DEA, SFA, and R. New York. Springer; 2010. DOI: 10.1007/978-1-4419-7961-2 [ Links ]
[2] Cullinane, K., Wang, T.F., Song, D.W. and Ji, P., The technical efficiency of container ports: Comparing data envelopment analysis and stochastic frontier analysis. Transportation Research Part A: Policy Pract, 40(4), pp. 354-374, 2006. DOI: 10.1016/j.tra.2005.07.003 [ Links ]
[3] Coelli, A.T., Henningsen., A. and Henningsen., MA., Package 'frontier' 2013. [ Links ]
[4] Greene, W., Distinguishing between heterogeneity and inefficiency: stochastic frontier analysis of the World Health Organization's panel data on national health care systems. Health economics. 13(10), pp. 959-980, 2004. DOI: 10.1002/hec.938 [ Links ]
[5] Härdle, W. and Simar, L., Applied multivariate statistical analysis. New York. Springer, 2007. DOI: 10.1007/978-3-540-72244-1 [ Links ]
[6] Rosseel, Y., lavaan: An R package for structural equation modeling. Journal of Statistical Software. 48(2), pp. 1-36, 2012. DOI: 10.18637/jss.v048.i0. [ Links ]
[7] Riedl, D.F., Kaufmann, L., Zimmermann, C. and Perols, J.L., Reducing uncertainty in supplier selection decisions: Antecedents and outcomes of procedural rationality. Journal of Operations Management, 31(1-2), pp. 24-36, 2013. DOI: 10.1016/j.jom.2012.10.003 [ Links ]
[8] Kraft, E. and Tırtıroğlu, D., Bank efficiency in Croatia: A stochastic-frontier analysis. Journal of Comparative Economics, 26(2). pp. 282-300, 1998. DOI: 10.1006/jcec.1998.1517 [ Links ]
[9] Kaufman, L. and Rousseeuw, P.J., Finding groups in data: An introduction to cluster analysis. Vol. 344. John Wiley and Sons, 2009. [ Links ]
[10] Serra, C. y Zúñiga, Z., Identificando bancos en problemas. ¿Cómo debe medir la autoridad bancaria la fragilidad financiera? [en línea], Estudios Económicos. Banco Central de Reserva del Perú. pp. 1-2. 2002. [consulta, junio de 2015]. Disponible en: http://www.bcrp.gob.pe/docs/Publicaciones/Documentos-de-Trabajo/2002/Documento-Trabajo-04-2002.pdf [ Links ]
[11] Gómez-González, J.E. y Orozco-Hinojosa, I.P., Un modelo de alerta temprana para el sistema financiero colombiano. Borradores Economía, Banco la República, 62(565), pp. 123-147, 2009. [ Links ]
[12] López-Bazo, E., Definición de la metodología de detección e identificación de clusters industriales en España. Dirección General de la Pequeña y Mediana Empresa, (DGPYME), Madrid, 2006. [ Links ]
M. Valencia-Cárdenas, es Ing,Industrial, Esp. en Estadística, MSc. en Ciencias-Estadística. PhD en Ingeniería-Industria y organizaciones de la Universidad Nacional de Colombia, Sede Medellín. Docente de Institución Universitaria Tecnológico de Antioquia. Áreas de interés: métodos estadísticos, optimización con aplicaciones a la industria. ORDIC: 0000-0003-3135-3012
J Restrepo-Morales, es Ing. Administrador; Universidad Nacional de Colombia. MSc. en Administración; Universidad EAFIT. PhD. Internacionalización de la Empresa de la Universidad San Pablo CEU - Madrid, España. Docente titular de la Institución Universitaria Tecnológico de Antioquia. Diploma de Estudios Avanzados de la Universidad San Pablo CEU y Tecnólogo en Sistematización de Datos del Politécnico Jaime Isaza Cadavid. Áreas de interés: Finanzas, Análisis de Riesgo empresarial. ORCID: 0000-0001-9764-6622
]]>