Case based expert system for hypertension diagnosis
Santiago Cuadrado Rodríguez1, Emilio F. González Rodríguez2*, Haydee Curbelo Hernández3, Yaquelín Luna Carvajal4, Gladys Casas Cardoso5, Iliana Gutiérrez Martínez6
1facultad de Ingeniería Eléctrica, Universidad Central de Las Villas, Carretera Central No. 208 e/Jesús Menéndez y Danielito. Santa Clara, Cuba.
2*Facultad de Ingeniería Eléctrica, Universidad Central de Las Villas, Calle Caridad No.l (oeste) e/Cuba y Villuendas. Santa Clara, Cuba.
3Facultad de Medicina; Universidad Médica de Villa Clara; Santa Clara, Calle Delicias No.2 (altos) e/Síndico y Caridad. Santa Clara, Cuba.
4Vicedirección general Programa de Integración y Desarrollo; Salud, Calle D No. 20 e/ 1ra y Carretera de Camajuaní. Santa Clara, Cuba. ]]>
5Facultad de Matemática-Física-Computación, Universidad Central de Las Villas, Calle Martí No.80 (oeste) e/ Zayas y Esquerra. Santa Clara, Cuba.
6Facultad de Matemática-Física-Computación, Universidad Central de Las Villas, Calle Caridad No. 80 e/Colón y Maceo. Santa Clara, Cuba.
Resumen
El artículo describe un sistema experto basado en casos para el diagnóstico de la hipertensión arterial (HTA) en la ciudad de Santa Clara, Cuba, realizado en el marco de un estudio para conocer la incidencia de la enfermedad en esta población.
La muestra de la población estudiada estaba formada por 455 hombres y 394 mujeres, entre 18 y 78 años de edad. Los individuos fueron clasificados en normotensos (personas con presión arterial normal), prehipertensos (personas en riesgo de padecer HTA) e hipertensos.
]]>
Se realizó un procesamiento estadístico en el que se emplearon técnicas multivariadas como el Análisis Discriminante y la Regresión Logística cuyos resultados, junto a los del Método del Triángulo de Füller, fueron utilizados en el sistema para jerarquizar los factores de riesgo de la HTA y obtener el grado de importancia (peso) de estos. Por medio de la técnica de segmentación CHAID se pudo reducir las comparaciones entre los casos haciendo más eficiente este proceso. La obtención de las funciones de comparación por rasgos para las variables continuas se obtuvo de la aplicación conjunta de un análisis de varianza (ANOVA) y el método TwoStep Cluster Analysis.
Todo esto permitió construir la función de semejanza para la comparación entre el nuevo caso a diagnosticar y los casos de la base. La adaptación de la solución de los casos más semejantes se realizó con la aplicación del algoritmo de los k-vecinos más cercanos.
El sistema experto fue validado finalmente y se comprobó una efectividad en el diagnóstico del 96%.
Palabras clave: sistema experto basado en casos, hipertensión arterial, técnicas estadísticas.
Abstract
This paper describes a case based expert system for hypertension diagnosis in Santa Clara city, Cuba, carried out as part of an investigation to know the incidence of the disease in this population.
The studied population's sample was formed by 455 men and 394 women, with ages between 18 and 78 years. The cases were classified in three groups: normal (people with normal blood pressure), with prehypertension (people that has risk to suffer hypertension) and people with hypertension. ]]>
A statistical process was made with this sample in which multivariate techniques as Discriminant Analysis and Logistic Regression were used. The results of these techniques and the application of the Fuller's Triangle Method were used in the system for ranking the hypertension risk factors and for obtain their importance grade (weigh). CHAID technique allowed reduces the comparisons of the cases making more efficient this process. With the application of the analysis of variance (ANOVA) and TwoStep Cluster Analysis the features comparison function for continuous variables was obtained.
With all this information the likeness function was build to compare the new case with the rest of cases of the case base. The adaptation of the solution of the most similar cases was carried out with the application of nearest k-neighbors algorithm.
Finally the system was validated and was checked an effectiveness of 96%.
Keywords: case based expert system, hypertension, statistics techniques.
Introducción
]]> La hipertensión arterial (HTA) es una enfermedad crónica caracterizada por un incremento continuo de la presión sanguínea en las arterias, también conocida como presión arterial.Sistema experto con razonamiento basado en casos
El uso de herramientas de Inteligencia Artificial (IA) para la toma de decisiones en el campo de la salud se encuentra muy generalizado actualmente. Esto se debe a que en este tipo de dominio del conocimiento la información que se maneja resulta difícil de formalizar por el alto grado de subjetividad asociado. Dentro de las herramientas de IA más utilizadas están las tecnologías basadas en el conocimiento y entre estas pueden mencionarse los Sistemas Basados en Reglas, las Redes Neuronales Artificiales, los Sistemas de Inferencia Borrosos y los Sistemas Basados en Casos [8-11].
Debido a las características del problema que se presenta y por el hecho de disponer de una base de casos diagnosticados por expertos médicos, es que se decide aplicar la técnica del razonamiento basado en casos pues esta apoya sus predicciones en ejemplos (casos) y en el que cada nuevo individuo a diagnosticar se compara con la base de referencia.
En el presente trabajo se muestran los fundamentos de un Sistema Experto Basado en Casos para el diagnóstico de la HTA, el cual se basa en el uso de técnicas estadísticas [12-14].
Experimentación
La muestra de casos estudiados por el comité de expertos estuvo formada por 455 hombres y 394 mujeres, entre 18 y 78 años de edad, de la ciudad de Santa Clara, Cuba. Dicho comité confeccionó y aplicó un cuestionario (historia clínica) a la muestra estudiada, el cual incluyó un grupo de variables que se describen en la tabla 2.
]]>

Análisis estadístico de la muestra
En el análisis de la muestra se utilizó el paquete estadístico SPSS 13. Entre los métodos de análisis de la estadística multivariada estuvo el Análisis Discriminante, la Regresión Logística y la técnica de segmentación CHAID. Las dos primeras permitieron validar el criterio de los expertos con respecto al grado de importancia o peso de cada variable para el diagnóstico, lo cual fue utilizado en la construcción del sistema experto; mientras que la técnica CHAID agrupó los sujetos de la base de casos, atendiendo a valores comunes en ciertas variables. En algunos casos esta agrupación clasificó directamente a los individuos, lo cual le aportó eficiencia y rapidez al programa. El criterio de comparación entre las variables continuas se obtuvo de la aplicación conjunta de un análisis de varianza (ANOVA) y el método TwoStep Cluster Analysis.
Sistema basado en casos para el diagnóstico de la HTA
Un Sistema Basado en Casos para la Toma de Decisiones es un Sistema de Decisión S como el que se presenta en (1), y se define en términos de un par (u,X U Y) donde u es un conjunto finito no vacío de objetos, eventos llamados casos, mientras X y Y son dos conjuntos finitos, no vacíos, de atributos ó propiedades llamados rasgos predictores y objetivos respectivamente.
]]>
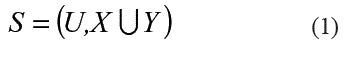
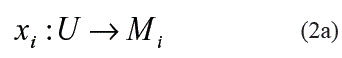
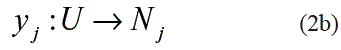
Base de casos
La base de casos contiene las experiencias o casos con los cuales el sistema realiza sus inferencias y puede ser representada a través de una tabla, cuyas columnas son etiquetadas por variables o atributos que representan los rasgos predictores y objetivos, mientras que sus filas representan los casos. En la tabla 3, la cual representa la estructura de la base de casos de nuestro problema, el conjunto u está formado por los casos O1, O2,..., Om, el conjunto X por los atributos {x1,... xn}, mientras que el conjunto Y lo integra el atributo y1. En nuestro problema, el conjunto u estaría integrado por los 849 sujetos de la muestra estudiada, el conjunto X lo integrarían los factores de riesgo (rasgos predictores) incluidos en la historia clínica y el conjunto Y estaría formado por el diagnóstico asignado a los casos, el cual, como se ha visto, puede ser normotenso, prehipertenso o hipertenso.
Módulo de recuperación
El proceso de recuperación consiste en determinar los casos de la base más semejantes a cada nuevo caso. Para escoger una medida de semejanza entre los casos, se han desarrollado varias técnicas. La más sencilla de ellas cuenta el número de rasgos predictores similares entre ambos. Otra técnica utiliza un conjunto de heurísticas que determinan las variables de mayor importancia (peso) en la determinación del rasgo objetivo y se formula una función que teniendo en cuenta esto considera la semejanza o diferencia entre cada uno de los rasgos predictores. ]]>
A continuación se describe el algoritmo del proceso de recuperación.
Entrada: O0, Ot (O0: nuevo problema y Ot: caso de la base)
Salida: β(O0, Ot) (Medida de semejanza o distancia entre O0 y Ot)
1. Para cada rasgo predictor xi se requiere:
i) Buscar los valores xi (O0) y xi (Ot) (valores del rasgo xi en los casos O0 y Ot) ]]>
ii) Calcular una medida de la semejanza δi(xi(O0), xi(Ot)) entre estos valores.
2. Tomar en consideración el peso Wi del rasgo predictor xi y δi(xi(O0),xi(Ot)) a través de una función f como la que se especifica en (3):
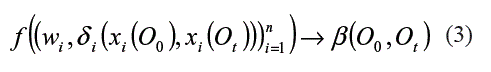
Para un rasgo predictor xi, δi establece la semejanza o distancia entre dos valores xii (O0) y xi(Ot, de ese rasgo. La función δi aparece definida en (4).
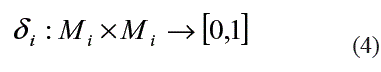

-Cuando la variable es discreta, como es el caso de la variable sexo, la función de comparación se define como aparece en (6):
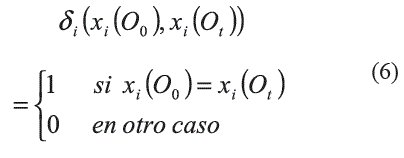
Módulo de adaptación
Después de la determinación de los casos más semejantes, las soluciones contenidas en ellos pueden usarse directamente como solución al nuevo problema, pero comúnmente necesitan ser modificadas. Este paso se conoce como proceso de adaptación. Existen diversas maneras de realizar este proceso. En el sistema se utiliza el algoritmo de los k-vecinos más cercanos considerando un solo rasgo objetivo y1, que en nuestro caso sería el diagnóstico. El algoritmo se describe a continuación.
Sean K = {R1,...,Rk} ⊆ u los k-vecinos más cercanos al nuevo problema O0, la probabilidad PO0,y1t de queO0tome el valor y1t en el rasgo objetivo y1 se define como aparece representado en (7): ]]>
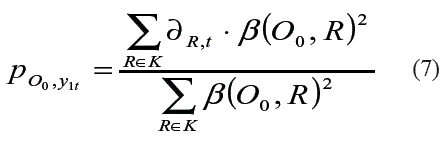

Resultados y discusión
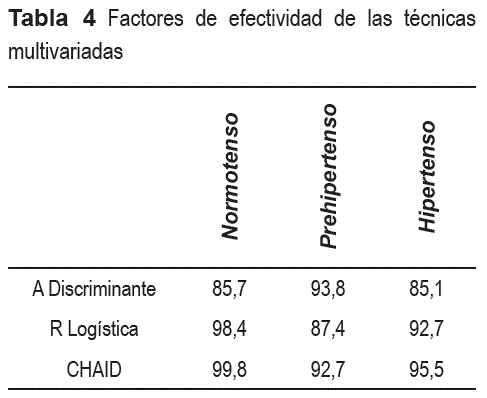
El Análisis Discriminante jerarquizó los factores de riesgo en el siguiente orden: PAM, PAS2, PAD2, PAS1, PAD1, PAS, PAD, IMC, alcohol, dislipidemia y raza. Para diferenciar los prehipertensos de los normotensos, la Regresión Logística consideró el siguiente orden: sexo, fuma, PAS1, PAD1, PAS2, PAD2 y PAM. Sin embargo, para distinguir los prehipertensos de los hipertensos el orden fue: sexo, raza, enfermedad renal, PAS, PAD, PAS1, PAD1, PAS2, PAD2, PAM, IMC, acido urico y ColHDL. La técnica de segmentación CHAID consideró la PAM y el IMC, como las variables más importantes para predecir la HTA.
En la tabla 4 aparecen los factores de efectividad (cifras porcentuales) de estas técnicas.
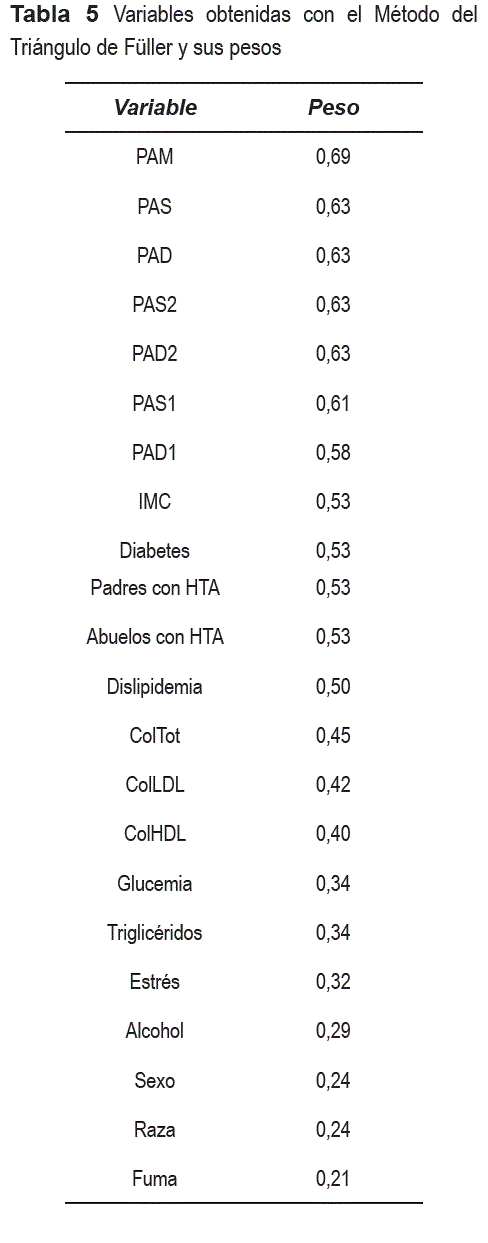
Con la aplicación del Método del Triángulo de Füller, un método de comparaciones por parejas para tomar decisiones multicriterio a partir de expertos, se pudo obtener la importancia o peso de los rasgos predictores en la determinación del rasgo objetivo [25]. La tabla 5 muestra este resultado en el que las variables han sido ordenadas de forma descendente según el valor de su peso. Estas variables fueron las que finalmente se tomaron en cuenta en la construcción del sistema basado en casos. ]]>
La técnica de CHAID agrupó a los casos de forma que cada nodo, en la estructura jerárquica de árbol, contiene los casos que comparten el mismo rango de valores para una misma variable o grupo de variables. En la figura 1 aparece una versión simplificada de la estructura del árbol obtenida.
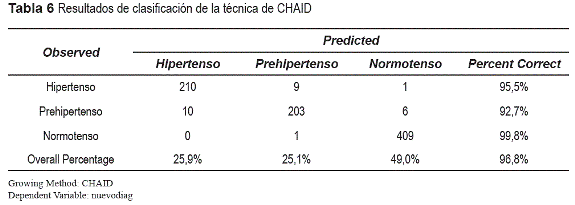
Este resultado se utilizó en la implementación del sistema, pues garantizaba que cada nuevo caso a diagnosticar, una vez ubicado en el nodo correspondiente del árbol, solo fuera comparado con los casos de ese nodo. Esto permitió reducir notablemente el número de comparaciones a realizar y aportó gran eficiencia al programa al optimizar el número de comparaciones. En la tabla 6, obtenida del fichero de salida del SPSS, se muestran los resultados de clasificación de la técnica CHAID.
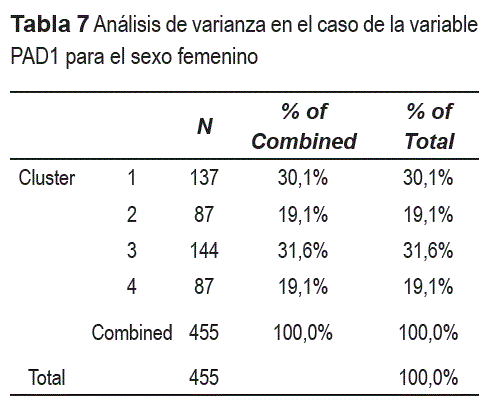
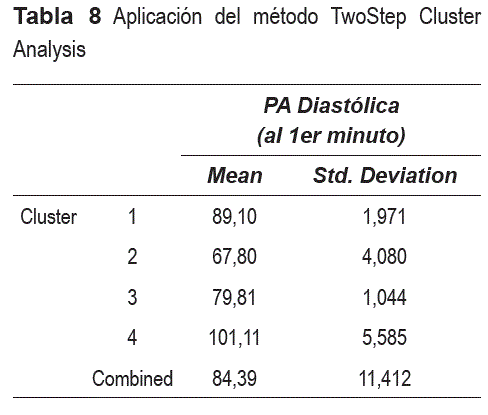
Como ya se mencionó anteriormente, las funciones de comparación por rasgos δi para las variables continuas, se construyeron con ayuda del paquete estadístico. Por ejemplo, en el caso de la variable PAD1 (PA diastólica 1er min) para el sexo femenino, el análisis de varianza (ANOVA) sugirió la formación de 4 grupos homogéneos. Esto aparece reflejado en la tabla 7 (salida del SPSS).
Con este resultado se aplicó el método TwoStep Cluster Analysis, cuyo resultado se puede observar en la tabla 8 (salida del SPSS) en el que se comprueba efectivamente la formación de 4 clusters.
De esta manera los dos valores a comparar se ubicaron en el clúster correspondiente siguiendo el criterio de la menor distancia de estos a la media de cada clúster. Luego se utilizó la siguiente función de comparación que aparece en (9) [26-30]. ]]>
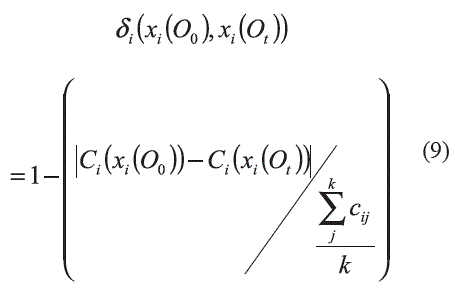
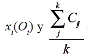 el promedio de las medias de los clústers obtenidos de esa variable xi .
el promedio de las medias de los clústers obtenidos de esa variable xi .
De forma análoga se construyeron las restantes funciones de comparación por rasgos para finalmente aplicar la función de semejanza β representada en 5.
El primer paso para realizar el diagnóstico consistió en ubicar el nuevo caso en el nodo terminal correspondiente del árbol (ver figura 1). Esta ubicación, en ocasiones, permitió clasificar al caso directamente, dependiendo del nodo del árbol del que se tratase. Por ejemplo, los casos ubicados en el nodo 1 (aquellos con PAM menor o igual a 102,67), fueron diagnosticados directamente como normotensos, mientras que los casos ubicados en el nodo 7 (aquellos con PAM mayor a 123,33) fueron clasificados como hipertensos. Cuando el caso quedó ubicado en otro nodo, se utilizó el algoritmo de recuperación ya descrito anteriormente pero comparando el nuevo caso sólo con los que se encuentran en el nodo donde fue ubicado. Por ejemplo, si el caso fue ubicado en el nodo 8, la comparación se realizaría con los 60 casos que la técnica de CHAID ubicó en ese nodo.
Una vez determinados los casos más semejantes se aplicó el Algoritmo de los k-vecinos más cercanos para determinar el diagnóstico del nuevo caso.
El sistema, que se construyó bajo el nombre de Tensoft III v2.0, fue validado finalmente y alcanzó una efectividad del 96% la cual puede mejorar a medida que la base de casos crezca y se enriquezca.
Conclusiones
]]> En este artículo se muestran los resultados de aplicar técnicas de inteligencia artificial, como el razonamiento basado en casos, para el diagnóstico de la HTA. Se comprobó la gran utilidad del empleo de técnicas estadísticas en la construcción del sistema experto pues estas contribuyeron a determinar las variables a considerar, así como las funciones de comparación entre los rasgos.Referencias
1. http://es.wikipedia.org/wiki/Hipertensi%C3%B3n_arterial. Consultado el 23 de septiembre de 2010. [ Links ]
2. M. D. P. Caballero, A. D. Herrera, J. A. Guerra, A. V. Vigoa. Hipertensión Arterial. Guía para la prevención, diagnóstico y tratamiento. J. Quesada (editor). 1a ed. Ed. Ciencias Médicas. La Habana, Cuba. 2008. pp. 9-22. [ Links ]
]]>
3. http://www.drscope.com/cardiologia/pac/arterial.htm. Consultado el 13 de Septiembre de 2010. [ Links ]
4. R. D. Feldman, G. Y. Zou, M. K. Vandervoort. "A simplified approach to the treatment of uncomplicated hypertension. A cluster randomized controlled trial". Hypertension. Vol. 53. 2009. pp. 646-653. [ Links ]
5. D. L. Clement, M. L. De Buyzere, D. A. De Bacquer. "Prognostic value of ambulatory blood-pressure recordings in patients with treated hypertension". J Med. Vol. 348. 2003. pp. 2407-2415. [ Links ]
6. K. Bjorklund, L. Lind, B. Zethelius. "Prognostic significance of 24-h ambulatory blood pressure characteristics for cardiovascular morbidity in a population of elderly men". Hypertension. Vol. 22. 2004. pp. 1691-1697. [ Links ]
7. http://scielo.sld.cu/scielo.php?pid=S0864-21251996000200007&script=sci_arttext. Consultado el 13 de septiembre de 2010. [ Links ]
]]>
8. J. L. Kolodner. "An Introduction to Case-Based Reasoning". Artificial Intelligence Review. Vol. 6. 1992. pp. 3-34. [ Links ]
9. F. Mariiel. "CBR: A categorized bibliography". The Knowledge Engineering Review. Vol. 9. 1994. pp. 1-36. [ Links ]
10. A. Aamodt, E. Plaza. "CBR: foundational issues, methodological variations and systems approach". AI Communications. Vol. 7. 1996. pp. 1-22. [ Links ]
11. W. Dubitzky. Knowledge Integration in Case-Based Reasoning: A Concept-Centred Approach. Thesis submitted in application for the degree of Doctor of Philosophy. Faculty of Informatics, University of Ulster, The United Kingdom. 1997. pp. 226-231. [ Links ]
12. I. G. Martínez, R. E. Bello, Y. C. Bergolla. URS-HTA: Sistema de Razonamiento en condiciones de Incertidumbre para el diagnóstico de la HTA. II Simposio Internacional de Hipertensión Arterial. Ed. Feijoo. Villa Clara (Cuba). 2004. pp. 2-4. [ Links ]
]]>
13. S. C. Rodríguez, G. C. Cardoso. Diagnóstico y detección de factores de riesgo de la HTA usando técnicas estadísticas. III Simposio Internacional de Hipertensión Arterial y I Taller sobre Riesgo Vascular. Ed. Feijoo. Villa Clara, Cuba. 2006. pp. 6-8. [ Links ]
14. A. P. de Armas, O. G. Blanco, H. C. Hernández, E. G. Rodríguez, Y. L. Carvajal, S. C. Rodríguez. Nuevos métodos para el pesquisaje y el diagnóstico precoz de la hipertensión arterial esencial. III Simposio Internacional de Hipertensión Arterial y I Taller sobre Riesgo Vascular. Ed. Feijoo. Villa Clara, Cuba. 2006. pp. 2-4. [ Links ]
15. P. Armario, R. Hernández del Rey, M. Martín. "Estrés, enfermedad cardiovascular e hipertensión arterial". Medicina Clínica. Vol. 119. 2002. pp. 23-29. [ Links ]
16. R. S. Vasan, M. G. Larson, E. P. Leip, J. C. Evans, Ch. J. O'Donell, W. B. Kannel, D. Levy. "Impact of High-Normal blood pressure on the risk of cardiovascular disease". J Med. Vol. 345. 2001. pp. 1291-1297. [ Links ]
17. M. Benet, A. J. Yanes, L. J. González, J. J. Apolinaire, J. García del Pozo. "Criterios diagnósticos de la prueba del peso sostenido en la detección de pacientes con hipertensión arterial". Medicina Clínica. Vol. 116. 2001. pp. 645-649. [ Links ]
]]>
18. W. Wilke, R. Bergmann. Considering Decision Cost During Learning of Features Weights. Ed. SpringerLink. University of Kaiserslautern, Germany. 1996. pp. 460-472 [ Links ]
19. S. Cuadrado, G. Casas. Tensoft: Sistema informativo para el diagnóstico de la HTA sobre bases estadísticas. Tesis presentada en opción al título de Master of Science. Universidad Central de Las Villas. Santa Clara, Cuba. 2006. pp. 26-44. [ Links ]
20. I. Watson, F. Marir. "Case-Based Reasoning:A review". The Knowledge Engineering Review. Vol. 9. 1994. pp. 355-381. [ Links ]
21. J. S. Breese, D. Heckerman. Decision-theoretic case- based reasoning. Fifth International Workshop on Artificial Intelligence and Statistics. Fort Lauderdale, Florida. January. 1995. pp. 56-63. [ Links ]
22. I. Gutiérrez, R. Bello. "A Decision Case-Based System, that reasons in Uncertainty Conditions". Lecture Notes in Artificial Intelligence (LNAI 2504). Berlín. Ed. Springer Link. 2002. pp. 54-63. [ Links ]
]]>
23. L. Ceccaroni. "Introducción a los sistemas basados en el conocimiento". Inteligencia Artificial. Vol. 12. 2008. pp. 25-45. [ Links ]
24. I. Watson, F. Marir. Case-Based Reasoning: A Review. University of Auckland. New Zealand. Vol. 3. 2000. pp. 355-381. [ Links ]
25. M.Tabucanon. Multiple criteria decision making in industry. Ed. Elsevier. Amsterdam. 1988. pp. 233-299. [ Links ]
26. S. Milton. "Statistical Methods in the Biological and Health Sciences". Statistics. 3rd ed. Ed. McGraw-Hill. New York. Vol. 1. 1999. pp. 586. [ Links ]
27. J. Jacqueline, Meulman, W. J. Heiser. Manual de SPSS. Ed. Oxford: Oxford University Press. 2004. pp. 49-90. [ Links ]
]]>
28. S. Glantz. Primer of biostatistics. 5th ed. Ed. McGraw- Hill. Vol. 1. 2002. pp. 468. [ Links ]
29. A. Field. Discovering Statistics Using SPSS for Windows. Advanced Techniques for the Beginner. Ed. U.o.S. Daniel B. Wright. Vol. 1. 2003. pp. 496. [ Links ]
30. A. Aron, E. Aron. Statistics for the Behavioral and Social Sciences. A Brief Course. 2nd ed. Ed Prentice Hall. Vol. 1. 2002. pp. 330. [ Links ]
(Recibido el l5 de octubre de 20l0. Aceptado el l4 de julio de 2011)
]]> *Autor de correspondencia: teléfono: + 53 + 42 + 281351 ó 209227 correo electrónico: eglez@uclv.edu.cu. (E. González) ]]>