











 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
PermalinkIntroduction
The Sun is the main responsible for the varying conditions of the interplanetary medium, particularly, in the space surrounding our planet, in what is commonly known as space weather. Multiple solar phenomena show up at many spatial and temporal scales, and are studied through observations, theoretical models and simulations. Among the most energetic phenomena in the solar system are the solar flares. These are transient events associated to the activity of the star in which certain regions of the solar atmosphere can emit a vast amount of energy up to 1025 Joules.
These zones in the solar atmosphere are associated with the presence of dark spots in the solar surface (photosphere) called sunspots. Sunspots are the manifestation of intense magnetic fields emerging from the solar interior and crossing the photosphere, inhibiting the normal convection of solar plasma and thus reducing the radiation emission.
For this reason the temperature values in sunspots drop approximately 2000 K compared to the temperature in the non-active photosphere, known as quiet sun. Sunspots are proxies of solar activity and their number on the solar disk was used to discover the solar cycle in 1843 [1] and are the main constituents of the so-called solar active regions.

Solar activity has become a very important research topic due to its connection with space weather and the possible impact of energetic phenomena on the normal development of the current technological society, based on satellites, which could be affected by intense solar emissions [2].
Depending on the amount of energy released (flux in Wm-2 ) during the intensity peak of flaring events, solar flares are classified in A, B, C, M or X, as listed in Table 1. The effect of the different types of flares is also different depending on the flare type [3].
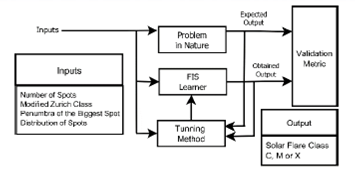
The main goal of this work is to choose the best Fuzzy Inference System (FIS), from among several FIS tuning methods used, through a validation index Starting from the solar flares characteristics and quantity of them in the solar disk (as inputs of the FIS), each FIS allows to obtain a classification of the solar flares (as output of the FIS).
The parameters of each system were tuned using five methods: Manual Tuning, Adaptive Neuro-Fuzzy Inference System (ANFIS) with random initialization [4], Compact Genetic Algorithm (CGA) [5], Differential Evolution (DE) [6] and Stochastic Hill Climbing (SHC) with random initialization [7].
The flow chart that describes the problem is shown in Figure 1, in which the "Problem in Nature" is the unknown way that makes the input values to be related with the output values, observed from Sun behavior. This behavior should be emulated by the FIS. The validation index is a function of the expected output, generated by the Problem in Nature, and from the output obtained by the FIS.
The sunspot features and their associated flares were obtained by generating a database according to [2], through a cross search in the sunspots and solar flares catalogs from the National Geophysical Data Center (NGDC). The parameters for the cross search allowed to obtain a total of 1391 individual values, using a time span of 6 hours, in the records from 1999 to 2002, to cover the activity peak of the Solar Cycle 23.
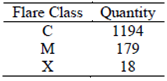
The quantities for each class with these parameters are recorded in Table 2.
Note that the generated data presents an imbalance: the number of type C (common) flares are big compared to the M (moderate) flares, data class. Similarly, the M class has more data than X (extreme) flares, as expected from displaying activity of the Sun during its cycle of approximately 11 years.
Aiming to abbreviate, the inputs of the database were numerated as follows:
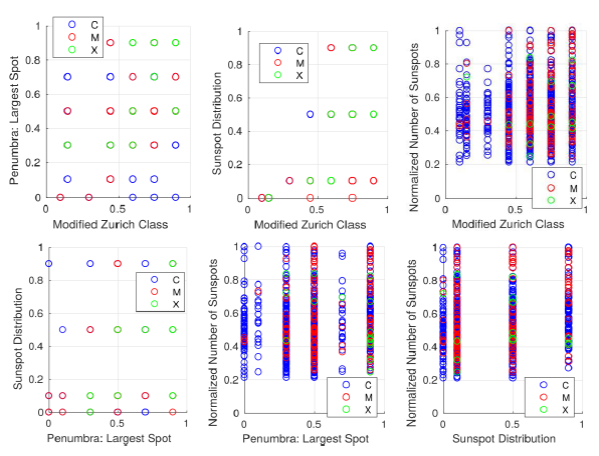
Creating scatter plots from pairs of inputs like in Figure 2, shows that it is not possible to plot a linear function that separates the classes.
Also, it is quite clear from the Figure 2 that class M seems to be "absorbed" by class C. Furthermore, class X, having the lower amount of data, is almost not recognizable from class M. Thereby, the attention is focused on classify the class X solar flares.
2.Methodological Considerations
2.1 Fuzzy Inference System
A FIS consists of five components: a base of fuzzy rules, a data base that defines the membership functions of the fuzzy sets used in fuzzy rules, the fuzzy inference engine, the fuzzifier and defuzzifier [4].
The FIS can be represented with a fuzzy basis function expansion in which an input vector x is related with a punctual y output, such that y=f(x). Thus, it is possible to represent in a compact manner the inference process of a FIS and the resulting function is a universal estimator [5]
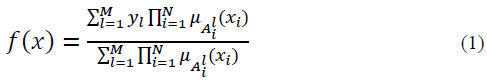
The FIS represented by [1] has the following characteristics:
Fuzzification: Singleton
Membership Functions: Gaussian.
Implication: Product
Defuzzification: Average of centers.
The 𝑙 index refers to the 𝑙 -th rule, being M the total number of rules. By its part, the i index refers to the i-th input and N are the total of them. The 𝜇𝐴 l i ( ) membership function (MF)
is then unique for each input in every rule. Similarly, the center of the consequent set y𝑙 is unique in every rule [5].
The 𝜇𝐴 l 𝑖 ( )are of Gaussian type, and can be written as [2].

Every MF in [2] has their c mean value and a σ standard deviation.
The total quantity of parameters that defines a FIS in the form [1] are given by [3], having in mind that, for each input and every rule there are two parameters due to the antecedent set (c and σ ), and an additional parameter being the center of the consequent.

2.2 Manual Tuning Method
Starting from the authors' perceptions about the data and the possible relations that may be present in it, it is possible to create an initial FIS with their fuzzy sets for each of the inputs, their punctual output values, and the rule base allowing to link the fuzzy sets of the inputs to the punctual outputs.
The purpose of this method is to deepen into the problem recognizing possible relationships among features as well as revealing preliminary classification rules.
Although a valid solution can be found, the most important result of this method is the knowledge derived from approaching the problem.
Initially the software used was GNU's Octave, loading the packages "io" and "fuzzy-logic-toolkit". The first allows that Pctave reads the generated CSV dataset, and the second to design, test and verify the manual tuned FIS.
Despite the fact that in the following algorithms the software used was MATLAB, the final FIS created with Pctave was migrated to MATLAB through the Fuzzy Logic Designer, a graphical tool part of the Fuzzy Logic Toolbox; with the mere purpose to use the same software tool at the final validation stage.
2.3. Adaptive Neuro-Fuzzy Inference System (ANFIS) with random initialization
ANFIS, a FIS based on adaptive networks, is a method based on a supervised learning model that, given a set of input/output pairs (x,y), related by an unknown function f, there is an apprentice and a supervisor of the learning process from f, with the use of a validation metric to evaluate the results of the apprentice and able to correct it. The algorithm uses a hybrid model that combines least squares method and the decreasing gradient or back-propagation method.
In this case the apprentice is a fuzzy system that can be written as the expansion of fuzzy based functions for a Sugeno type system shown in [1]. The parameters to be determined correspond to y , X 𝑖 l and σ 𝑖 l [4]. The validation metrics represents the root mean square error (RMSE) between the output value for the fuzzy apprentice system and the output value y of the data pairs [5]. The process aims at minimizing the error for the input values in a set comprising part of the complete available data, which is generally about 70% of them. Searching for an apprentice generalization, it is validated with the remaining 30% of the database.
Additional to the individual (apprentice system with its parameters and rules) to be adjusted, ANFIS requires initial conditions such as the number of rules, number of inputs and the rate of initial learning. For the case mentioned above, the inputs stay constant and the other two parameters are tuned up. Because ANFIS fits the parameters of an existing individual, thus implying a local search, it executes several times and, prior to this, it generates the individual with initialized parameters in random values, aiming at (depending on randomization) perform a global search in a whole universe of possible solutions.
Algorithm 1 Pseudo code for the MATLAB implementation using the ANFIS function.

2.4 Compact Genetic Algorithm (CGA)
This belongs to a series of algorithms known as Probabilistic Model Building Genetic Algorithm (PMBGA) [8], which are characterized by discriminating the significant contribution attributes in the construction of an optimal individual. The validation indexes for determining the performance of an individual is the "Fitness" function, which in turn depends on the problem to be solved. The implementation considers an individual with the best performance when the value of this function is minimized.
Because in this work we are dealing with a classification problem, besides using the RMSE, we decided to also consider the use of classification error and correlation. With that in mind, we can assemble an initial brief of a fitness function [4].
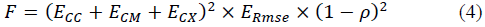
And

Where:

Every 𝐸𝐶𝑥 classification error has its respective w x weight. As the database is inherently imbalanced, every weight w x was assigned to be greater than the proportion of data belonging to class C, to the quantity of data from the other classes:
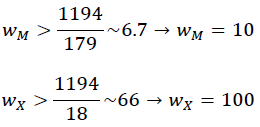
Therefore, the weight associated to the class X of solar flares, for which the number of data is lower, has the highest value. By doing this, a badly classified data that belongs to this class produces a more significant increase in the first factor of (4) that one not incorrectly classified in class C, in the final fitness function factors (6)
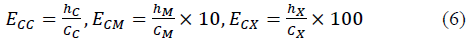
To explain the ERmse Root Mean Square Error in (4), suppose that the problem is not a classification problem, but a prediction problem instead. For a conceptual brief, the ERmse gives an idea on how the individual are not "following" the expected sequence from the training data [5].
Then, a bad predictor will have a greater ERmse value, than other that gets closer to the output values of the database, and considering that the data also depends on some time unit. The root mean square error is mathematically described as:

Where
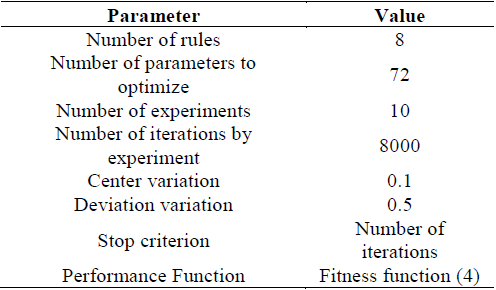
The number of rules was taken from the obtained result with the ANFIS algorithm, R=8 rules. For developing the algorithm, the parameter for adjusting the converging speed of the probability vector n is tuned. Since the optimal value is unknown, it is randomly designated based on [5], and implemented in MATLAB. The process of randomly varying n and developing the algorithm, is repeated several times (w = number of experiments). Finally, among the best solutions the value generating the lowest number in (4) with (6) is found.
Algorithm 2 Pseudo code for CGA. Based on (5).
The parameters describing every FIS (individual) are then converted from real to binary data, due to the method adjusting every bit.
2.5 Differential Evolution
This is an algorithm based on the evolution of a population of vectors (individuals) with real parameters, which represent solutions in the searching space.
The algorithm of differential evolution is basically composed by 4 steps, as follows:
Initialization: Every vector (individual) of the population is randomly initialized.
Mutation: A mutation is applied in order to create a testing population of individual.
Crossing: Every vector is used as a mutant vector.
Selection: The testing vector previously obtained is used to do the crossing procedure, which compete with the target vector by the evaluation of the Fitness function [6].
Algorithm 3 Pseudo code for DE. Source: Based on [6].

2.6 Stochastic Hill Climbing (SHC) with random initialization.
The Stochastic Hill Climbing, consist on taking a FIS (1) and keep evaluating the solutions in the vicinity of it [7] [9] in a maximum number of iterations. The parameters of the input FIS are randomly initialized.
Algorithm 4 Pseudo code for Stochastic Hill Climbing [10].

Here:
Imax: Maximum number of iterations 𝑆 : Some particular solution (like 𝐶𝑢𝑟𝑟𝑒𝑛𝑡 or 𝐶𝑎𝑛𝑑𝑖??𝑎𝑡𝑒) Cost(𝑆𝑜𝑙) : Fitness function, obeys (2)
RandomNeighbor(Current) in Algorithm 3 also requires the center and deviation variations, that refers to the allowed absolute value variations of the related parameters when searching for a neighbor. As example, if some of the parameters has the value 0.6, and the specified variation of this parameter is 0.1, then the neighbor will have some uniformly distributed random value between 0.5 and 0.7.
Every separate experiment consist on a single run of a program that implements the Algorithm 4, to obtain a final single individual, but n individuals can be obtained by running n experiments. Afterwards, the individuals can be evaluated with (4) and the validation base, in order to choose the best individual of the n individuals.
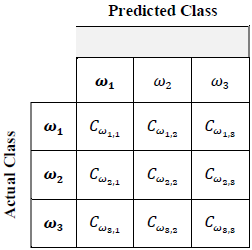
2.7 Confusion Matrixes
The classifier output consists on C values, corresponding to the 𝜔1, 𝜔2, … , 𝜔𝑐 classes. Due to the erroneous classifications occasionally occurring, the multiclass sorter is evaluated through a (C x C) - dimensional confusion rate matrix showing the respective classification errors between classes (off diagonal) and correct classifications (diagonal elements) [11].
Table 3 shows an example of a confusion matrix for a total of C = 3 classes. The 𝐶𝜔𝑖, elements correspond to the data quantity from the 𝜔𝑖 class that was classified as elements of the 𝜔j class.
3. Parameters for the Algorithms
Excluding the manual tuned FIS, and in order to allow the replicability of similar results, we expose briefly the parameters used for the algorithms. For the CGA, DE and SHC algorithms, the number of rules was taken from the best ANFIS result, as shown in Table 3.
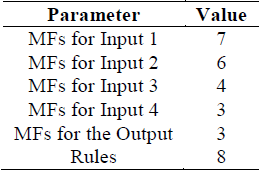
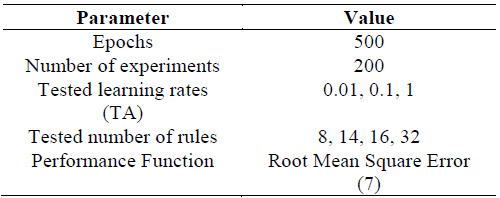
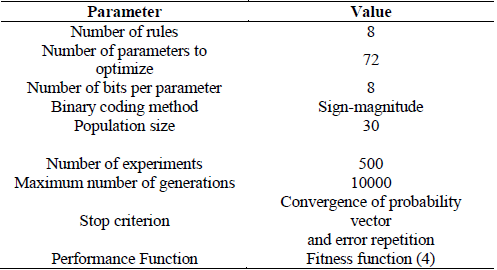
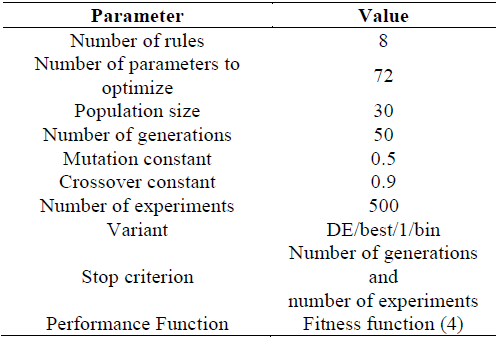
3.1 Manual Tuning
As the parameters for this method obey to human perceptions of the problem, only the main features are shown in Table 4, for this reason this method was applied only as an exercise of comparison between the human performance and machine performance, in building a FIS that solves the classification problem. These values are not normative by the same fact that the parameters were based from human perceptions of the authors, are then allowed to test other values, but the manual tuning method takes too much time to get a single FIS.
Tables 5-8 show the initialization parameters for each implementation.
4. Results
In this section we show first the best results for every method and their analysis. This analysis includes a comparison of their performance.
4.1 Confusion Matrices
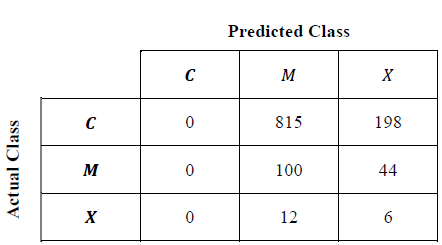
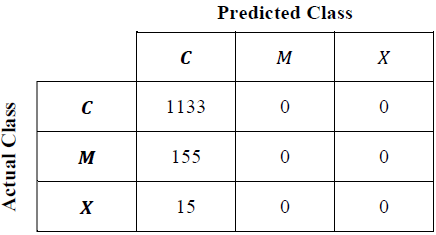
The best FIS obtained by each algorithm was evaluated using the whole database. With the evaluated output values and the expected output values a confusion matrix can be filled as shown in Table 3 to obtain the matrices shown in Tables 9, 11, 12, 13 and 14.
In the case of ANFIS, the individual with the lowest validation error was selected for each of the different combinations of number of rules and initial learning rate (LR) as shown in Table 10.
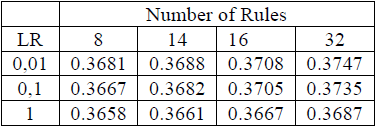
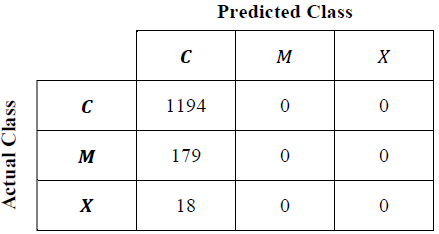
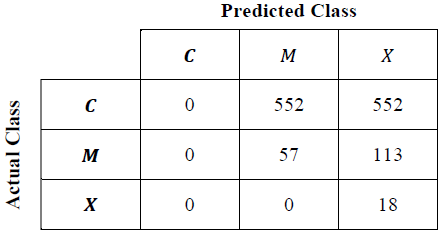
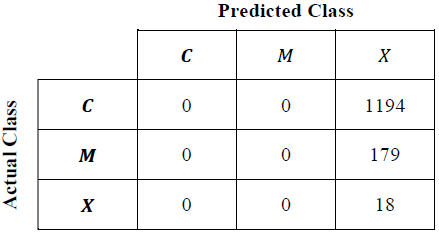
From Table 10 the best individual are chosen to make the confusion matrix shown in Table 11. In order to compare the results with the same metric, this individual was evaluated with (4) and its results are part of Table 15. The chosen individual was obtained with the following parameters:
The best FIS obtained by the CGA occurred on experiment 𝑤 = 175 and for a value 𝑛 = 41 of the probability adjustment parameter.
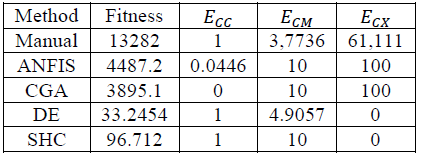
Final Result by the validation Metric
Table 15 lists the more relevant metrics for the individuals in every scheme. The final individual was the one with the lowest value of the Fitness function (4), using the validation database.
4.3 Statistical Analysis
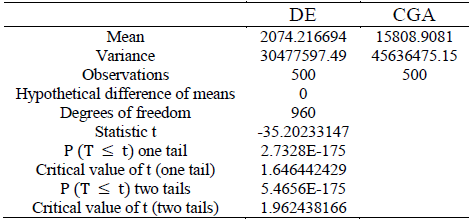
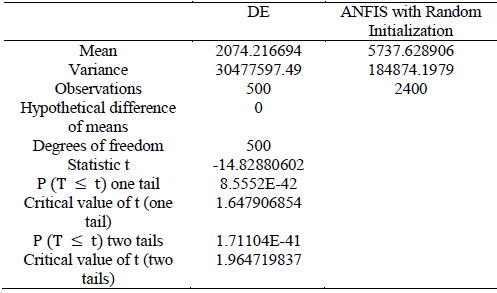
To perform a statistical analysis of the algorithms implemented, the Welch's t-test was used for two-samples, assuming unequal variances to confirm or reject the null hypothesis whether both methods provide similar analytical results or not [12].
Comparing the results of the test between DE with the CGA and ANFIS algorithms as shown in Tables 16 and 17 respectively, it is possible to reject the null hypothesis and conclude that the methods provide different analytical results with a 99% confidence level.
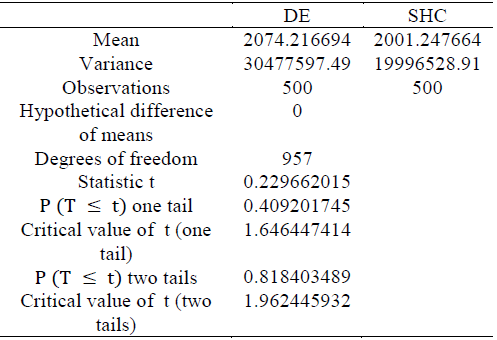
On the other hand, from Table 18 it can be evidenced that, although the best solution was achieved with the DE algorithm, the average and the variance of the fitness of the individuals obtained with SHC are better than those obtained with DE. This result makes sense in the light of the non-free lunch theorems [13], which state that optimization methods perform similarly in average over the entire set of possible optimization problems.
The result of the Welch's t-test shows that the null hypothesis should not be rejected because in the case of two tails the confidence level to reject is less than 20% and in the case of one tail it is less than 60%. Therefore, both methods provide the same average results and the observed differences are purely due to random errors.
Conclusions
In this section we summarize the obtained results and discuss on the different aspects of their performance.
Due to the imbalance in the database, systems and algorithms used in the present work have limited options to learn from class M, and much lower ones from class X.
Additionally for ANFIS, because of the fact mentioned before, the validation metrics for RMSE is not adequate for solving the problem since it ignores the classification error, from which it is evidenced that the best individual obtained in this method is an optimal class C classifier, but not so for the rest of classes.
Despite the Compact Genetic Algorithm has a simple description with little memory, it sufficiently restricts the space of solutions since it works with parameters represented in fixed point, having a more reduced universe as compared to the representation in floating points.
From the items listed above, and from Table 4, it cannot be discarded different problems in which either class C are distinguished from being or not solar flares (modifying the generation parameters of the database), or type M or X solar flares are distinguished. As a future work, the problem can be addressed by using neural network algorithms, e.g. Cascade-Correlation Neural Networks (CCNNs), Support Vector Machines (SVMs) and Radial Basis Function Networks (RBFNs) (2) instead of FISs, in order to determine if it is feasible to obtain a best classifier and therefore extend the problem of estimating the occurrence of solar flares.

