











 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
Permalink1. Introduction
Complexity in computing systems has been growing in an exponential fashion, as predicted by Moore's Law. According to with such law, the performance of computational systems doubles, and their prices fall by half, every eighteen months [1]. Along recent years, improvements in performance have been a consequence of the use of several processing units, or cores, which are able to execute concurrent tasks. Such implementations are often referred as multicore, depending on a number of cores which compose the computing system [2]. Multicore systems are present in almost every computer applications, such as mobile phones, ultra-high performance computers, as well as desktop and laptop computers [3]. Multicore systems are also widely used for embedded applications, which exhibit several constraints related to objectives such as performance or real-time deadlines, as well as an increased complexity. Such bunch of conditions cannot be met without the use of several processing cores [4]. It is expected that the number of processing units shall grow in an exponential way, in a similar fashion as the formulation of Moore's Law. Such feature imposes several new challenges to the designers of these systems, which need to guarantee optimality of the application execution and resources usage, whilst coping with design constraints.
Another important issue in multicore systems is related to the communications among the processing cores. Network on Chip (NoC) systems have been proposed as a solution for such a problem. NoC systems might be viewed as a special case of multicore systems, in which both the set of processors and a communication network among such processors have been integrated into the system chip. Such features make NoCs very suitable for high-performance embedded applications [5], since requirements such as concurrency can be easily fulfilled [6]. But these advantages also imply some new challenges and add optimization objectives to the design process, such as bandwidth and link delay.
For high-speed computing systems, performance is a key measurement, since it assesses the system efficiency for executing a set of concurrent tasks. Performance may also serve as comparison criterion for multicore systems and communication networks [7]. However, in the presence of several processing cores, modeling system performance is not an easy task. In single-core systems, performance has been easily calculated as the inverse of execution time. Such appraisal is not suitable for multicore systems, since concurrency and resources usage should be taken into account. That's why for multicore systems, speedup measurements are used instead. A speedup measurement compares the performance of a given system with respect to a reference implementation [8].
A NoC system may then be defined as an integrated circuit which contains a set of processing cores and the corresponding communication network. If the number of cores grows, the communication network becomes more complex, and latency increases, so it is necessary to improve system throughput, as well as its connectivity. Though several proposals have been reported in this issue, such as 3D NoC, Photonic NoC, and RF NoC, the routing problem is still a complex challenge for connecting cores which are far away in the chip [9]. A new paradigm has been proposed for solving this problem, referred as Wireless Network on Chip (WNoC or WiNoC). A WNoC is a NoC with usually wired interconnection resources, as well as wireless routers and links, which allow a more effective communication among faraway cores. WNoC systems may be viewed as a hierarchy of two communication levels: The first level is composed of wired links and is used for local or nearby connections among the cores. Communications through this level are cheaper since several wired paths and resources are available. The second level corresponds to the wireless links and is used for distant connections. Wireless resources are scarcer, which implies higher communication costs. Such organization is the reason why such systems are also referred as hybrid or hierarchical systems [9-11].
WNoCs appeared as an attempt to reduce latency in the communication network whilst the system size grows. However, implementation of such systems imposes problems, such as the optimal mapping of executable applications to the set of cores, whilst coping with several objectives (performance, latency, bandwidth, and so on). Concerning the specific problem of task mapping, several proposals have been reported, ranging from deterministic and exact methods, such as Integer Linear Programming (ILP) and Brute-Force, to heuristic solutions. Nonetheless, almost all such reported solutions deal with wired NoCs and don't take into consideration the two-level behavior of a WNoC.
This paper describes an approach for static task mapping to WiNoC or hierarchical NoC systems for embedded systems. The target architectures are heterogeneous by nature, which means that each core into the system may be different from each other. For the first level of the WiNoC, a mesh topology has been used. The second level is composed of wireless links with a star topology. Three objectives were considered in the optimization process: Speedup, power consumption, and bandwidth in the communication links. For the mesh wired level, a simple X-Y routing algorithm was used. The rest of the document is organized as follows. Section 2 describes the more relevant reported works concerning WiNoCs and task mapping proposals for this kind of architectures. Section 3 introduces the hardware model used in the mapping process, as well as the optimization algorithm used for task mapping. Section 4 presents obtained results and its related analysis, and finally, conclusions are presented
2. Related works
WNoCs have emerged as a promising approach for solving NoC problems such as scalability, latency, bandwidth, and power consumption, as the amount of processing cores increases. Some previous works aimed at such objectives were focused on the exploration of wired mixed topologies [12-15]. Such systems combine well-known network topologies, in order to improve the network throughput, but don't take into account wireless links. 3D NoCs are a special instance of such systems. Another approach consists of using a different link media instead of wired ones. Optical and RF links have proposed and studied [16]. Both 3D NoCs [17-19] and Optical NoCs [20-22], are expected to improve power consumption drastically in the future, since nowadays heat dissipation is quite high [23,24]. Similarly, in optical networks, there is an issue related to the optical link reliability, and to the cost of the optical interfaces inside the chip [25]. RF-based NoCs are more suitable for reducing power consumption and link latency but are limited by the availability of accurate filters and oscillators inside the chip [26,27]. WNoC is aimed at the reduction of latency for faraway nodes in the network [28]. Nearby cores may use regular wired connections, without a sensible reduction in the throughput.
Three kinds of WNoCs have been proposed in the literature. Ultra-Wide Band (UWB) NoCs are based in transmitters, receivers and antennas, developed at the CMOS scale. Such systems operate at a central frequency of 3.6 GHz and a bandwidth around 1.6 Gbps. The spatial scope of this technology is about 1mm, which makes it suitable for communications inside the chip [10, 29]. In the second place, WNoCs based on millimetric wavelengths are able to reach bandwidths up to tens of GHz [30], and some implementations have been able to reach a bandwidth of 500 GHz [31]. The third kind of WNoC is based on antennas constructed with carbon nanotubes [32]. Such systems can reach high transfer rates, with bandwidths around 500 GHz [9,10]. However, such technology is nowadays considered as immature.
It seems that the best trade-off concerning links inside a NoC system is the use of a hybrid approach. The slow and cheap links may be used for short range connections, whilst high-speed links, which are more costly, are used for large range connections among the cores [16]. Such approach allows to simultaneously increasing the bandwidth (by using short range wired connections) and improving the power consumption (by using large range wireless links) [33].
Mapping is one of the most critical stages in NoC-based embedded systems design and refers to the allocation of a set of executable tasks (an application) to the available resources inside the network. Mapping is considered an NP problem [34]. In order to solve the problem of mapping a set of tasks into a NoC system, the following elements must be taken into account [35]:
Figures of merit: They represent the set of optimization criteria which are going to be taken into account in the mapping process.
Common-domain semantic: It relates to the form in which the input information is represented, for the sake of combining the high-level specification for the application and information coming from the hardware platform.
Optimization algorithm: Is related to the design space exploration process, which searches for the best tradeoff among the mapping objectives.
Nature of the mapping: The nature of the mapping process specify whether such process is going to be conducted in design time (static) or in run time (dynamic).
Target architecture: Refers to homogeneous or heterogeneous NoCs. The first kind refers to networks in which all the cores are of the same type. In heterogeneous NoCs each core may be different from each other.
Abstraction level: Is related to the way in which the input application is specified. Instances of this choice are the Transaction Level Modeling (TLM), or the Register Transfer Level (RTL).
Table 1 summarizes some of the more representative works reported in the subject of task mapping into a NoC system.
Table 1 highlights that most of the reported mapping solutions are aimed at working with wired NoCs. An approach aimed to WNoC is listed in such a table, but it is limited to homogeneous networks and to one single optimization criterion [44].
Though there are several reported works concerning Wireless and hybrid NoCs, none of them are devoted the mapping problem. The nearest reported approach to the mapping problem is related to the location of the wireless router [16], but it does not deal with static task mapping.
3. Methodology
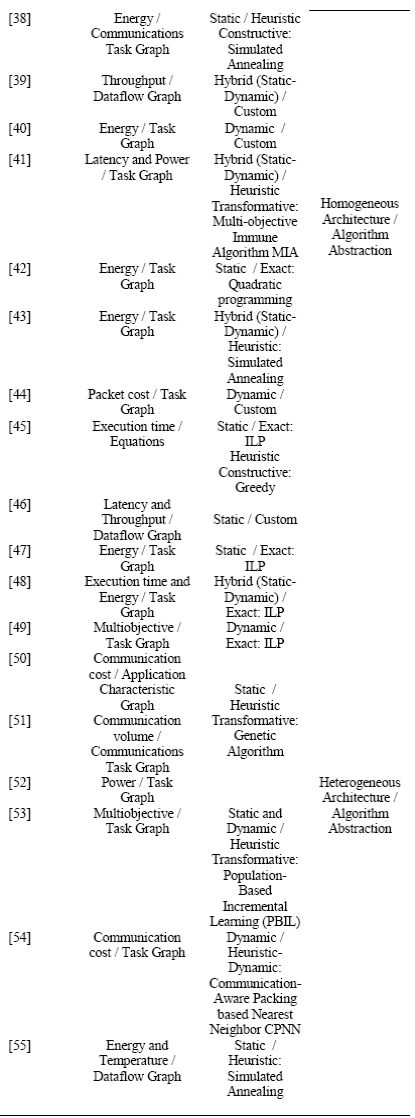
A model for the hardware platform based on a wireless architecture WiNoC of two levels, the first level is made up of four subnets with four nodes for each subnet, each subnet with wired mesh topology in two dimensions. The upper level has a star topology, which allows communication between different subnets at a faster rate, this level has a wireless connection. The communication architecture has five wireless routers (WR) and twelve wired (R), the routing algorithm used is the deterministic algorithm XY. The target architecture is heterogeneous, i.e. it has different types of processors (PE) and is modeled by an architecture graph, and applications are represented by task graph. Fig. 1 shows the communication architecture for a WiNoC of two levels, where the wired links are continuous arrows, and wireless links are dotted arrows.
The task mapping is performed at design time and is based on an algorithm of genetic optimization, working with three objectives, the maximum acceleration or speedup, the minimum energy consumption in communications in the nodes and the minimum bandwidth communication resources of the NoC. Given the application’s task graph and target architecture, the problem of tasks mapping can be defined as the search for better distribution of tasks, in order to optimize both maximum acceleration and minimum energy consumption and bandwidth of system implementation.

The genetic algorithm was implemented in Matlab and had initially some adjustable parameters such as the size of population (PZ), the maximum number of generations (MG), the mutation rate ( Rm ) and crossover ( Rc ), task graph (TG) application and the architecture graph (ArG) . This algorithm has five stages described by functions, as shown in Fig. 2.
Initialization-Population function. This function creates a random population of solutions of a specified size in the input parameter (size of population PZ). The population size is a compromise between convergence speed and solution quality.
Evaluation-Sorting function. Each solution of the population according to the optimization objectives is assessed: Acceleration or speedup, given by the ratio of the execution time of the application in the fastest node split on the execution time obtained in each mapping; Power consumption (nodes and communication architecture) and bandwidth (BW) resource in the NoC interconnect. The sum of these three normalized values represents the output of the multi-objective function known in the literature as fitness; the calculation is detailed in Eq. (1). In addition to assessing the fitness, the solutions, are ordered from more to less fit, according to this metric.
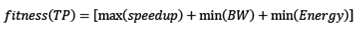 (1)
(1)
Selection function. Individuals capable for next generations are generated, for this task is used the proportional technique to the performance function (fitness), which is based on the probability distribution given in Eq. (2).
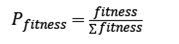 (2)
(2)
Once the probability vector is obtained ( Pfitness ), it is normalized and generates a random selection of future parents among random candidates within the population of solutions. This makes random selection able to choose less likely candidates, in order to maintain diversity in the population.
Crossover function. The crossing of individuals eligible to be generated in the selection function is performed. The crossing between two individuals generates two offspring and is done randomly across the amount of information of each individual. The number of individuals generated at the crossing is given by the ratio of the crossover rate ( Rc ) and the initial population size (PZ), this relationship is shown in Eq. (3).
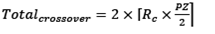 (3)
(3)
Mutation function. This function randomly selects several solutions and the initial population within each solution is randomly changed in one of its attributes. The number of individuals generated by the mutation process is defined by the ratio of the mutation rate ( Rm ), the size of the initial population and number of tasks ( Ntask ) application, this relationship is shown in Eq. (4).
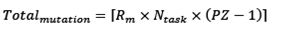 (4)
(4)
The stopping criterion of the algorithm is given by the ratio of the maximum number of generations or the extent of diversity of today's population, that is, when the solutions tend to be equal, the algorithm terminates.
4. Results and discussion
The genetic algorithm was written and verified in Matlab tool (R2012). Three types of tests for embedded systems were performed. Those test allowed to assess the algorithm regarding the task mapping problem. The first test was based on the application of MPEG-2 video decoder with 12 tasks. Profiling runtimes and bandwidth were taken from [4]. The second test was a random application with 16 tasks whose profiles of time, bandwidth and energy consumption were taken from the database Power- Struggles [56] and the third test was three synthetic applications of 50, 25 and 13 tasks each, generated through the tool called Task Graphs for Free (TGFF), which is a GNU tool used for embedded system applications. This tool provides information on execution times, bandwidth, and energy consumption.
The target architecture used for testing is a heterogeneous architecture represented by an architecture graph, which models four subnets 2x2 2D mesh, formed by processors and routers, the internal connection of each mesh is wired, and wireless interconnection between meshes is done through a star topology. The conditions of network traffic are simulated by the XY routing algorithm.
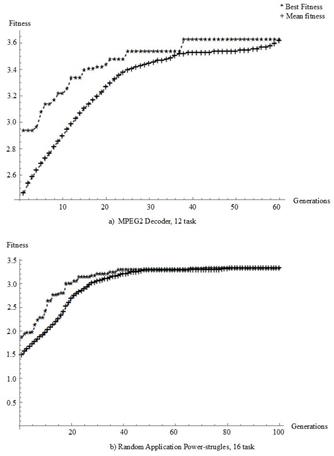
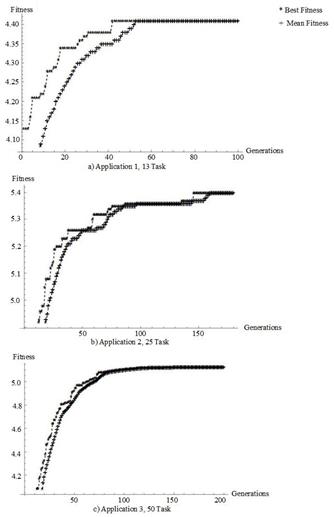
The results obtained for these tests: the best fitness value obtained and the average fitness is presented; these are shown in Fig. 3 for testing one and two and in Fig. 4 for test three.
As shown in Figs. 3, 4, the fitness values converge toward the maximum value as the algorithm proceeds through several generations or iterations.
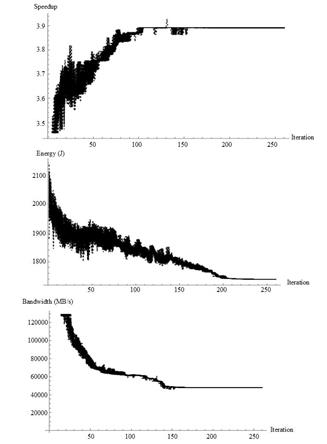
In Fig. 5, shows the evolution of the three objectives of optimization (maximum speedup, low energy consumption, and minimum bandwidth) as a function of the number of generations or iterations, these results correspond to the third test performed, which has 50 tasks.
As shown in Fig. 5, each optimization objective value reaches a stability point whilst the algorithm progresses. Maximum speedup is achieved from the 160th iteration; the energy reaches its minimum around the 190th iteration, and the bandwidth around the 150th iteration. The whole set of tests was performed over 300 generations.
As there are several optimization targets, and a single cost function (fitness) is required to assess the mapping solutions, an aggregation technique was used. Such aggregation is calculated just as the sum of all the objectives. Given that all the targets are equally relevant for the algorithm, equal weight was given to each objective. That is why the obtained results showed that none of the objective values were favored during the optimization process. A weighting strategy may be adopted in the aggregation, for the sake of giving more importance to one of the normalized objectives and treat it as the most important over the remaining ones.
5. Conclusions
A multi-objective genetic algorithm has been implemented and tuned for the sake of performing task mapping over a WiNoC architecture. The obtained results show that it is possible to perform the simultaneous optimization of several figures of merit in the mapping process, such as acceleration or speedup, power consumption, and network bandwidth. Obtained results are promising. They show that it is possible to compute an optimized mapping solution, in a few dozens of iterations, as derived from Fig. 3, 4. Performance of the mapping approach is a key feature, since despite that the mapping process initially was conceived as a design time procedure (static tasks mapping), it is possible to migrating it to runtime, in order to perform dynamic mapping optimizations.
Fig. 5 shows the evolution of the several objectives to be optimized in the tasks mapping process, and it can be concluded that the whole set of objectives describe an asymptotic behavior, approaching gradually to their optimum values. Despite the main objective of using a WiNoC architecture is to improve system performance, it is mandatory to consider other figures of merit, for the sake of avoiding bottlenecks in the actual system operation. Such bottlenecks would be related to network traffic congestions (which may be avoided by optimizing the bandwidth of the whole set of available links) and power concentrations (avoided by optimizing power consumption by node) which may damage or degrade the long-term operation of the system.
As a future work, novel optimization approaches will be explored and tested for the tasks mapping problem, in complex environments such as NoC and WiNoC systems. Since it is expected that the size of such systems continues to grow, the design of efficient mapping strategies shall be a more critical feature, with a very high complexity.

