











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
MÉTRICAS DIGITALES: DE LOS DIOSES DEL OLIMPO A LOS CONGLOMERADOS EN LA NUBE
La gran paradoja de nuestro tiempo
La estadística contribuyó a que los seres humanos nos liberáramos de la creencia de que los dioses gobernaban nuestras vidas desde lugares como el Olimpo. Se sumó a la idea del libre albedrío y se esforzó por demostrar que no existe la predestinación. Gracias a sus instrumentos se reforzó la idea de que los ciudadanos debíamos elegir a nuestros gobernantes a través del voto popular y de que las discusiones públicas alimentan la toma de decisiones colectivas.
Hoy, casi 400 años después, parece que hemos vuelto al punto de partida. Los avances de la estadística y la enorme capacidad de recolección y procesamiento de datos nos han llevado a creer en nuevos dioses digitales que gobiernan nuestras vidas, ya no desde el Olimpo, sino desde la “Nube” valiéndose de sus poderosos algoritmos. En la actualidad, los conglomerados digitales aseguran que pueden predecir nuestro comportamiento, que saben qué compraremos mañana y que, con el procesamiento que hacen de nuestros datos, podríamos no necesitar seguir deliberando y, eventualmente, podríamos prescindir de los sistemas democráticos. Esta situación es una de las grandes paradojas de nuestro tiempo: las herramientas que nos permitieron liberarnos de los dioses del Olimpo nos están llevado a ser prisioneros de los dioses digitales.
Iniciamos con un intento de “genealogía” de la probabilidad y la estadística, donde se enfatizan los aportes de este oficio al entendimiento del riesgo. Un aporte del presente artículo es reconocer a la estadística como un “invento” europeo, con aportes españoles, ingleses, franceses y alemanes. Luego presentamos cuatro aproximaciones sobre las métricas digitales que dominan hoy nuestras vidas; particularmente, en las redes digitales. De allí pasamos a describir la forma como los conglomerados digitales acumulan información de las personas y el uso que les dan, haciendo énfasis en la forma como, ante la falta de regulación, se han convertido en una industria extractiva de un material: la información personal, al que hoy las mismas personas tienden a no darle valor ni importancia. Cierra el texto una reflexión sobre las posibles implicaciones para la democracia y el sistema político del retorno de la idea de que los seres humanos somos predecibles.
Breve historia de la probabilidad y la estadística
Las matemáticas son una forma de lenguaje que existe hace más de 3.000 años. Fueron usadas por los fenicios, los chinos, los griegos y los árabes y, por supuesto, fueron conocidas en la Europa medieval. La estadística, una de sus derivaciones, surgió hace cerca de 400 años, en Europa. Mientras las matemáticas, el cálculo, el álgebra y la geometría giran en torno a las certezas y las seguridades, la estadística se fundamenta en las ideas del riesgo, el azar, la incertidumbre y, por supuesto, la probabilidad. Esta última implica la aceptación del riesgo, el reconocimiento del “error” y la existencia de anomalías.
La idea de la probabilidad provocó una ruptura frente a la forma como se entendía la vida. Antes de su aparición, los desastres naturales eran inevitables, y gracias a ella ahora se los puede gestionar, disminuir sus efectos y, en algunos casos, anticiparlos. Del conocimiento sobre las probabilidades se desprenden las llamadas matemáticas del estado, o estadísticas, como se las conoce en la actualidad. Estas sirven para que los Estados tengan un mayor conocimiento y control sobre sus poblaciones. En ese orden de ideas, las estadísticas pueden ser vistas como un dispositivo de poder que surgió junto a la idea de la Modernidad. De la idea de la probabilidad surge el lenguaje técnico y especializado de las estadísticas que, parafraseando a Michel Foucault, pueden ser vistas como un dispositivo de poder que surgió con la idea de la Modernidad (1986).
Durante la Europa renacentista, la probabilidad como técnica de gobierno contribuyó a que el poder soberano se concentrara no en quitar la vida, sino en evitar las hambrunas y en fomentar el crecimiento poblacional. En ese momento, el conocimiento de la población cobró más importancia que el de las leyes, y hasta el día de hoy la estadística es fundamental para el ejercicio del poder, el Estado y los gobiernos. Foucault sitúa los primeros ejercicios estadísticos documentados en tres lugares (Foucault, 1986):
Irlanda, donde William Petty (1623-1687) es conocido por haber acuñado la expresión aritmética política e inaugurar los intentos por calcular el valor general de la producción económica, que luego se convertiría en las Cuentas Nacionales.
Alemania, donde Gottfried Achenwall (1719-1772) acuñó el término estadística, en 1749. En ese entonces, los ejercicios de las matemáticas del poder se llevaban a cabo en territorios concretos y pequeños, porque aún no existían los instrumentos técnicos que permiten recoger pequeñas muestras de datos para expandirlas a grandes volúmenes de la población. Estos mecanismos aparecerían más adelante gracias al desarrollo de los cálculos matemáticos de la aleatoriedad.
En Francia, donde el trabajo colaborativo entre Pierre de Fermat (1601-1655) y Blaise Pascal (1623-1662) sentó las bases de la teoría clásica de probabilidad.
En el libro El surgimiento de la probabilidad (2005), Ian Hacking emplea una metodología similar a la de Foucault para elaborar una genealogía de este dispositivo de poder. Hacking señala la necesidad de entender sus dos caras: “Por un lado, es estadística y le conciernen las leyes estocásticas de los procesos aleatorios. Por el otro, es epistemológica y se dedica a estimar grados razonables de creencia en proposiciones bastante carentes de un trasfondo estadístico” (Hacking, 2005, p. 24).
En esta línea de pensamiento, la probabilidad que alguien asigna a cualquier proposición particular es cuestión de su juicio personal, su opinión; pero el conjunto de todas sus asignaciones de probabilidad está sujeto a reglas estrictas de coherencia interna que se contrastan a la luz de la evidencia.
Hay un antecedente que Foucault y Hacking parecen desconocer, y es el aporte de España al desarrollo de la idea de la probabilidad; en particular, de la llamada Escuela de Salamanca. En su texto Rutas de incertidumbre. Ideas alternativas sobre la génesis de la probabilidad, siglos XVI y XVII (2015), Leticia Mayer Celis cuenta que en la Universidad de Salamanca se generaron: “Las primeras nociones de probabilidad en el sentido epistémico del término: cómo actuar de manera razonable en escenarios carentes de certeza, en otras palabras, en espacios donde la certidumbre es imposible, por lo que debe confiarse en elementos probables” (p. 13).
La idea de la probabilidad, propone la autora, surge con la expansión de Europa y el papel de las misiones en tierras lejanas al Mediterráneo. Los casuistas y los probabilistas europeos bebieron de los escritos de los misioneros de distintos suelos, y eso los llevó a muchas de sus reflexiones (Mayer, 2015). En ese sentido, los contactos culturales no solo cambiaron el mapa del mundo, sino que introdujeron la duda como episteme.
Puede decirse que la narrativa tradicional del surgimiento de la estadística se refiere a los desarrollos de los autores alemanes, franceses e ingleses. Frente a esta narrativa, Mayer propone el reconocimiento de los aportes españoles y muestra que se desarrollaron dos vertientes de pensamiento sobre la incertidumbre y el manejo que debería dársele: el probabilismo y el probabiliorismo.
Mientras que la primera vertiente recomienda seguir las sugerencias de hombres “probos” en escenarios de incertidumbre, la segunda únicamente acepta como forma segura de actuar lo que está plasmado en las escrituras. La hipótesis central de la autora es que en las discusiones sobre probabilismo se empezaron a crear las bases para el surgimiento de la idea de la probabilidad.
La probabilidad tiene que ver con el riesgo y la forma como este es percibido por las sociedades. No es independiente de las estructuras sociales y morales de cada contexto. Con el descubrimiento de América y las misiones en China, los españoles se enfrentaron y reflexionaron sobre un riesgo moral muy particular: la posibilidad de perder la vida eterna en el Cielo y condenarse en el Infierno por los siglos de los siglos (Mayer, 2015). Ese, y no la muerte, era el riesgo más importante que estos hombres sentían que podían correr en el siglo XVI. Mayer señala que el paso a la probabilidad aleatoria dado por Pascal y Fermat no habría sido posible “sin la existencia de una construcción sociocultural anterior: Las misiones fuera de Europa habían dado sentido a la incertidumbre profunda, a la noción del riesgo y a la probabilidad epistémica o teoría de las decisiones” (p. 21).
La teoría del probabilismo —o creencia en la opinión proba— abrió una ranura en el determinismo y permitió el desarrollo de la duda, la incertidumbre y el riesgo moral (Mayer, 2015). Francisco de Vitoria explica que el encuentro con esas sociedades tan distintas llevó a una reflexión sobre la posibilidad de reconocer formas distintas de ver y organizar el mundo y, en ese sentido, propició el reconocimiento del otro. Entonces, fue necesario romper el determinismo religioso y crearles significado epistémico a la duda, la incertidumbre y el azar, para que, posteriormente, la probabilidad aleatoria pudiera surgir (Mayer, 2015).
La idea de la probabilidad implicó romper las certezas medievales sobre la existencia. Así, el descubrimiento de América y las misiones en China abrieron el espacio para la reflexión sobre estos nuevos mundos y la introducción de la duda. En efecto, la necesidad de controlar las poblaciones impulsó la consolidación de la estadística como dispositivo de poder, pero sin duda, el reconocimiento del “otro” como alguien diferente y la idea de controlar la incertidumbre, no habría surgido.
Las métricas en el mundo contemporáneo: cuatro aproximaciones
En términos generales, las métricas son una forma del lenguaje y un dispositivo de gobierno que producen discursos sobre las realidades sociales y pueden inducir cambios en el comportamiento de las personas. En esta sección argumento que las métricas digitales se han convertido en una contranarrativa de las métricas estadísticas sobre las personas.
La visión clásica de la economía ofrece una primera aproximación para entender el gran volumen de datos digitales que circulan en la actualidad. Desde esta perspectiva, si los mercados tienen buena información pueden promover mejores decisiones de producción y consumo que se manifiestan en el precio de los bienes y los servicios. En ese orden de ideas, mientras más información exista, los agentes del mercado tomarán decisiones más costo-eficientes y los precios tenderán a disminuir en mercados más competitivos. En otras palabras, la existencia de muchos datos digitales supone un enorme beneficio para la sociedad, que compensa las molestias o los males causados por los individuos.
Sin embargo, tal supuesto es problemático por varios motivos. En primer lugar, omite la existencia de una gran asimetría de información: mientras que unas pocas empresas saben mucho de un gran número de individuos, los individuos saben muy poco de las empresas que acopian la información. En el marco de la economía clásica, dicha asimetría provoca mercados ineficientes. En segundo lugar, omite que las grandes corporaciones que acumulan datos digitales están consolidando una posición monopólica en el mercado. Finalmente, omite que dichas empresas violan los derechos a la intimidad de las personas. Las asimetrías de información, la creación de monopolios y las violaciones a la intimidad llevan a situaciones subóptimas de los mercados que, en la teoría clásica, exigen la intervención estatal.
La segunda aproximación se refiere al concepto capitalismo de vigilancia, desarrollado por autores como Byung-Chul Han (2022) y Shoshana Zuboff (2020). Hasta hace unos 30 años, el capitalismo extractivista se utilizaba para describir las economías mineras o agrícolas de enclave, que consistían en extraer los recursos de un territorio y generar una economía con pocos encadenamientos hacia delante o hacia atrás en las economías locales. Su función central era proveer a otros mercados de bienes a costos risibles, sin generar ningún tipo de sinergia con el entorno donde se generaba la producción.
Desde la concepción marxista del valor agregado, el concepto de capitalismo extractivista permite leer la forma como se generan las relaciones de producción de datos en el mundo digital. Las grandes corporaciones ofrecen un servicio —en principio, gratuito— a cambio de la entrega de datos que, para las personas, en su forma bruta, no parecen tener un valor de uso ni de cambio. En la medida en que dichos datos se vuelven masivos, se triangulan con otras fuentes de información y se procesan a bajo costo, para convertirlos en un bien con valor de uso y de cambio, y así provocar una situación de extractivismo económico. En términos sencillos, los individuos entregan sus datos de forma gratuita a corporaciones que los transforman y obtienen grandes ganancias valiéndose de ellos, lo cual les permite seguir sosteniendo la plataforma digital que las personas usan sin pagar. En este caso, aplica la máxima “Cuando usted tiene un servicio por el cual no paga, usted no es el cliente, es la mercancía”.
Debido a la relativa novedad de las redes sociales y el mundo digital, esta relación aún no es vista como una de producción, donde existe un tipo de vinculación laboral: yo genero unos datos que son su materia prima, la cual tiene valor agregado incluso antes de ser procesada, por lo cual debería recibir algún tipo de composición económica. Si esta visión se popularizara, la regulación de los mercados laborales intervendría las corporaciones digitales y la entrega de información por parte de los individuos.
Como señala Han (2022), “a diferencia del régimen de la disciplina, no se explotan los cuerpos y las energías, sino la información y los datos (…). El capitalismo de vigilancia que degrada a las personas a la condición de datos y ganado consumidor” (p. 10). En este caso, no aparecen conflictos de clase, porque el sujeto del régimen de la información se cree libre, auténtico y creativo. “Se reproduce y se realiza a sí mismo produciendo datos para las redes digitales” (Han, 2022, p. 10). Para el filósofo surcoreano, en la actualidad la visibilidad se invierte por completo, pues “no son los gobernantes quienes se hacen visibles, sino los gobernados” (Han, 2022, p. 10). En otras palabras, las personas se esfuerzan por alcanzar la visibilidad por sí mismas.
Por su parte, Foucault (2006) afirma que la estadística fue la nueva pastoral que reemplazó al cristianismo característico de la Edad Media para apoyar la biopolítica de los nuevos Estados nacionales modernos. Han retoma esta idea y propone que en la “nueva pastoral del saber los seguidores participan de una eucaristía digital. Los medios de comunicación social son como una Iglesia: el like es el amén. Compartir es la comunión. El consumo es la redención” (Han, 2022, p. 19).
El tercer marco de análisis que puede ser utilizado es la metáfora del panóptico, desarrollada por Foucault (1989). Desde esa perspectiva, la agregación de datos en el mundo digital funciona como las estructuras carcelarias donde unos pocos pueden ver y disciplinar el comportamiento de muchos que no están en posición de observar a quienes los disciplinan. Las métricas digitales, con sus grandes posibilidades de perfilamiento de usuarios, pueden generar la sensación de ser el gran hermano, de Orwell (2013), que, además de que todo lo ve y lo sabe, utiliza ese conocimiento como un dispositivo para la conducción de las poblaciones no solo en los espacios públicos, sino también, en los privados.
De allí se puede pasar al control estatal de la información, con lo cual los fines de control comercial se complementarían con fines policiales sobre todos los individuos. Hay un evidente crecimiento de este tipo de mecanismos: cámaras, posicionadores geográficos, mecanismos de escucha y lectores de rostros que empiezan a enfrentarse con los reclamos de habeas data y derecho a la intimidad. En Europa y Estados Unidos, algunos casos judiciales han mostrado los riesgos de estas prácticas.
El régimen de la disciplina solo disponía de información demográfica, lo que le permitía llevar a cabo una biopolítica. En cambio, el régimen de la información tiene acceso a información psicográfica, que utiliza para su psicopolítica. El llamado microtargeting utiliza perfiles psicométricos. La infocracia basada en datos socava el proceso democrático, que presupone la autonomía y el libre albedrío (Han, 2022, p. 36).
Finalmente, el cuarto marco de análisis posible es la visión inversa de los mecanismos de control y vigilancia. Se trata de una lectura donde el principal elemento “disciplinador” no es la visibilidad desde el panóptico, sino el deseo de sobresalir para evitar la invisibilidad en las redes digitales. Si no me conecto, no interactúo, doy likes y hago presencia, me vuelvo invisible y mis relaciones sociales se minimizan. Desde esta perspectiva, el entendimiento del funcionamiento de las métricas digitales consiste en que la idea no es ser vigilado, sino ser visible. Dado que se premia la actividad en redes, los sujetos buscan ser tan activos como sea posible. Dentro de este marco de análisis, las métricas digitales motivan a los individuos a ser activos para obtener retribuciones emocionales. En palabras sencillas, quienes más publican fotos y obtienen más likes logran una mayor visibilidad en las redes. En contraste, quienes solo leen, se expresan poco y asumen posiciones poco radicales, terminan siendo invisibles en el mundo digital.
Con el advenimiento de la era digital, empezamos a tener a nuestra disposición métricas masivas sobre los temas que nos interesan, así como grupos de personas con los que nos identificamos. Nunca había sido tan sencillo acceder a tantos datos sobre sentimientos, emociones y acciones. Están, literalmente, a un clic de distancia.
La facilidad con la que podemos obtener información de todo tipo nos hace olvidar que los datos siempre son una abstracción de la realidad, y no la realidad misma. Lo cierto es que la información —aunque sea infinita— no es suficiente para alcanzar la universalidad, por lo cual las dudas sobre los significados y la incertidumbre sobre los acontecimientos futuros sigue siendo permanente. En otras palabras, los elementos centrales de la episteme de reconocer al otro siguen presentes, a pesar de que sintamos que los datos digitales nos llenan de certezas.
Edwards (2010) afirma que las infraestructuras son un proceso de construcción social, y las nuevas no reemplazan totalmente a las anteriores, sino que se complementan y se acumulan. Es posible formular la siguiente analogía frente a las métricas que existen sobre los seres humanos: los censos siguen siendo el marco de referencia de los universos de la población y las encuestas a los hogares siguen mostrando señales importantes, pero han dejado de ser la única fuente de información, pues se complementan con los datos de las redes sociales y las plataformas digitales.
¿De dónde extraen nuestros datos?
Los primeros datos que obtienen las diferentes corporaciones digitales de las personas hacen referencia a las tecnologías que usamos: el tipo de computador, el de teléfono celular, el operador de los servicios de voz y de internet y la dirección del IP. Todo esto es capturado cuando nos inscribimos en una red o usamos alguna plataforma digital. También los tienen las compañías de celulares y de conexión a internet.
La encuesta Polimétrica, realizada en octubre de 2020 por Cifras & Conceptos, incluyó un módulo destinado a recopilar datos empíricos para este artículo. La población objetivo de dicho módulo eran personas mayores de edad votantes activos y residentes de Bogotá, Medellín, Cali, Barranquilla, Santa Marta, Manizales y Villavicencio. Se produjeron 2.570 respuestas vía telefónica, y se estima que el universo representado es de 6,2 millones de votantes activos. Este módulo encontró que el 92 % de los habitantes de siete grandes ciudades consultan sus redes sociales desde su teléfono celular, el 42 % también lo hace desde su computador, y el 12 %, desde una tablet. Esto corrobora el enorme volumen de información que recolectan no solo las plataformas, sino también, las compañías de telefonía celular desde los dispositivos móviles (2020).
Posteriormente, algunas empresas obtienen información sobre hábitos digitales: horas de consumo, tipo de navegación, tiempo que duramos en cada ventana o en cada archivo. Sin embargo, nada de esto es solicitado de forma explícita: simplemente, es un “dado” que se asume. A nosotros no parece importarnos y las empresas no creen necesario pedir nuestra autorización, pues dichos datos, en principio, son “para brindar un servicio de mejor calidad”.
Las tabla 1 y tabla 2 muestran los resultados para las preguntas: ¿Cuántas veces al día consulta sus redes? y ¿Cuánto tiempo dedicó a cada consulta? En ellas queda clara la permanente interacción de las personas en las diversas redes sociales, así como el volumen de tiempo que ocupan en ellas.
Tabla 1 Número de veces al día que los colombianos consultan las redes sociales
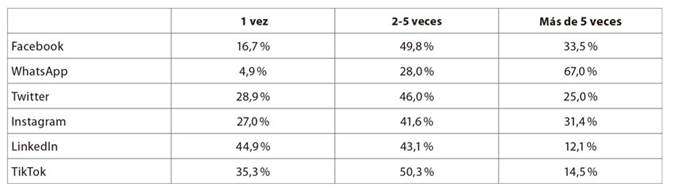
Fuente: Encuesta Polimétrica realizada por Cifras & Conceptos en 2020
Tabla 2 Tiempo promedio de cada consulta a las redes sociales
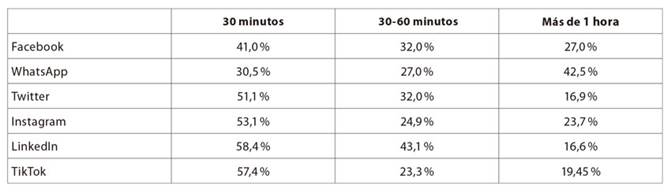
Fuente: Encuesta Polimétrica realizada por Cifras & Conceptos en 2020.
Las personas no tienen un comportamiento simétrico frente a sus redes; la de mayor intensidad es WhatsApp, con el 67 % de sus usuarios conectándose más de cinco veces al día, y permaneciendo más de una hora en cada consulta en el 42 %. En contraste, solo el 12 % de los usuarios de LinkedIn entra más de cinco veces al día, y el 17 % dedica más de una hora a cada entrada en la red. También es necesario enfatizar que el grueso de las personas se conecta desde sus dispositivos móviles (Cifras & Conceptos, 2020).
Luego están los datos sociodemográficos, que se nos solicitan de forma explícita y entregamos conscientemente: sexo, fecha de nacimiento, ciudad y dirección —esta última no es necesaria, porque la obtienen a través de la IP—. Algunas redes preguntan por temas de interés y hobbies.
Por otro lado, están las actividades en las redes o las plataformas digitales que usamos. Si se trata de Facebook o Twitter, lo fundamental son las personas que nos siguen y a quienes seguimos, y que casi siempre son afines a nosotros. Además, es importante considerar las actividades básicas que hacemos en cada red: comentar, dar “me gusta”, manifestar nuestro acuerdo o nuestro desacuerdo, compartir contenidos que nos parecen interesantes, verbalizar nuestros pensamientos y nuestras reflexiones por medio de frases cortas y expresar nuestros sentimientos por medio de emoticones o GIF. El contrato de adhesión que firmamos al suscribirnos a dichas redes y plataformas establece que todos esos datos son propiedad de las compañías. Así mismo, autorizamos que las corporaciones usen los contenidos que subimos en distintos formatos, como fotos, audios y videos. También están las cookies, un tipo de software que se instala en nuestros computadores y nuestros celulares —a veces, solicitando autorización, y a veces, sin preguntar— que permiten capturar nuestra ubicación espacial y las rutas que seguimos de forma cotidiana, aunque estemos en plataformas distintas.
Los más invasivos instalan mecanismos que activan los micrófonos y las cámaras para que podamos ser escuchados y observados de manera permanente, sin ningún tipo de autorización. Existe evidencia de que las grandes corporaciones usan cookies que se valen de una red inalámbrica para invadir e interceptar los demás equipos que se conectan a la misma red digital. Así mismo, existe la triangulación de datos de diferentes redes de la misma compañía u otras plataformas. El caso más emblemático es el de Facebook y WhatsApp, que gracias a los datos sobre los aparatos y la información sociodemográfica pueden cruzar actividades e información de las dos, sin que los usuarios hayan dado su autorización de forma explícita. En Colombia, una compañía de telefonía celular y un banco están haciendo exactamente lo mismo. Así mismo, existen cruces de información con compañías especializadas en recolectar datos como las centrales de riesgo crediticias, para precisar aún más la información de las personas. Nada de esto exige la autorización explícita de los usuarios.
No es de extrañar que las personas sientan que las grandes corporaciones digitales hacen un uso indebido de sus datos. Como lo respondieron 2.570 personas, que representan un universo de 6,2 millones, el 30 % sienten que las corporaciones digitales hacen al menos un uso indebido de su información personal, como lo muestra la tabla 3 (Cifras & Conceptos, 2020).
Tabla 3 Consideración de uso indebido de información personal

Fuente: Encuesta Polimétrica, realizada por Cifras & Conceptos (2020).
Estos resultados muestran que los usos indebidos de la información de los ciudadanos ocurren con el reconocimiento tácito por parte de las personas. El 49 % reconoce que las aplicaciones ya tienen identificado su lugar de residencia y que, además, en un porcentaje similar (47 %) entregan su información privada a otras empresas. Hay consciencia de los abusos y una aceptación de estos.
¿Qué hacen con nuestros datos?
Todos los datos recogidos digitalmente son procesados. Esto no significa que todos sean igual de útiles. Dicho procesamiento es realizado mediante algoritmos de tipo “Aprendizaje de Máquina”, desarrollados por cada compañía. El de Google es conocido como PageRank, y el de Facebook, como Edgerank. No se trata de una sola línea de programación, sino de múltiples algoritmos que son generados y utilizados por cada corporación.
El primer tipo de procesamiento —también, el más claro y más visible— es utilizado para dinamizar y mejorar la experiencia de los usuarios en las plataformas, para que las usen más. Su objetivo es hacer recomendaciones de contenidos y contactos que sean del agrado de los internautas.
Para lograrlo, perfilan a cada persona y hacen analogías con segmentos que tienen datos sociodemográficos y actividades pasadas en la plataforma. Esto quiere decir que, basándose en los datos de los usuarios que la compañía almacena, los perfila y asume que se comportarán como un segmento de la población con el cual se comparten características y comportamientos similares. Así, con base en el pasado, “predice” lo que les gustará en el futuro.
El segundo uso es la venta de publicidad. En este caso, se trata de mostrarles a los internautas productos en los que podrían estar interesados, con base en los datos que las plataformas tienen sobre ellos. Así, las personas con mascotas que dejan huellas digitales relacionadas con este tema empezarán a ver anuncios sobre seguros, comida para animales y veterinarios. En este caso, los datos permiten hacer una segmentación detallada que convierte a los usuarios en consumidores potenciales.
El tercer tipo de procesamiento tiene que ver con la venta directa de productos. En este caso, el perfilamiento de los usuarios es mucho más detallado, e implica triangular un gran volumen de información para determinar el nivel de ingreso, la ubicación geográfica, los tipos, los tiempos y los horarios de desplazamientos y consumos previos. La alianza entre una gran superficie y una plataforma digital permite generar un perfilamiento bastante preciso, que permite identificar compradores potenciales.
El cuarto uso consiste en que algunas instituciones financieras emplean los datos recopilados por estas plataformas para mejorar sus clasificaciones sobre el nivel de riesgo crediticio o de eventos adversos de las personas.
Finalmente, están los temas de control y vigilancia. Con la extensión de las redes digitales, la masificación de teléfonos inteligentes y la multiplicidad de mecanismos de monitoreo urbano, es posible hacer seguimientos detallados, primero de lugares, y luego, de las rutinas de las personas a lo largo de los escenarios urbanos digitalizados. Las organizaciones policivas se valen de este tipo de procesamiento. Así mismo, algunas compañías aseguradoras lo usan para evitar el pago de primas argumentando que existía evidencia de comportamientos peligrosos registrados en las redes sociales.
Las plataformas digitales presentan grandes retos para la democracia
Cuando había información escasa y su costo de recolección y procesamiento era relativamente alto, los datos disponibles daban cuenta del ciudadano promedio. En contraste, en la era digital, contamos con muchos datos y con una gran capacidad de procesamiento que suele representar individuos “extremos”, pues las redes acumulan más información de los usuarios más activos, lo cual implica que las personas que más usan las redes son las más visibles en el mundo digital.
Sin embargo, para lograr mayor visibilidad los algoritmos premian las posiciones radicales, y no las actitudes “políticamente correctas”, que, si bien pueden ser adecuadas, son “aburridas” y, por lo tanto, generan menos interacciones. Lo otro que permite mayor visibilidad son las emociones, y no las reflexiones. Mientras más emocional y menos reflexiva sea una persona, mayores posibilidades de ser visible tendrá.
De igual manera, el lenguaje escrito es menos visible que las imágenes y los videos, razón por la cual los sujetos textuales tienden a tener menos interacciones. Como el juego de las redes premia la visibilidad, los usuarios procuran presentar la mejor faceta de sí mismos, lo que creen que sus pares valorarán más. En este juego, la apariencia física, los lujos y los viajes conceden puntos extra a los usuarios.
En las redes digitales nos movemos en tribus, en grupos de personas que comparten pensamientos similares a los nuestros, razón por la cual tendemos a ver realidades homogéneas, las de aquellos que se parecen a nosotros. Esto hace que la representación de los sujetos digitales priorice no el promedio de las personas, sino los segmentos más extremos, radicales, emocionales y de mejor apariencia. Ese es el usuario, consumidor y comprador mejor segmentado en las redes sociales.
Usando la terminología de Foucault, las grandes corporaciones digitales, que suelen ser vistas como grandes ejemplos de emprendimiento, innovación y generación de valor, han creado una matriz de relaciones de poder que ponen en tensión muchos de los principios de la economía y la democracia liberales. Por un lado, dichas compañías tienen una posición dominante en los mercados digitales con fuertes tendencias de integración vertical. Se trata de un tipo de monopolios restrictivos que limitan la libre competencia de los mercados. Hace 120 años, un juez estadounidense obligó a la compañía Rockefeller a dividirse en lo que se conocería como “Las siete grandes hermanas”, porque había adquirido una posición monopólica en el mercado petrolero. En la actualidad, hay varios movimientos en distintas partes del mundo que proponen adoptar una medida similar con las grandes corporaciones digitales.
Por otro lado, es evidente que el modelo de negocios de estas compañías es altamente extractivista, pues recopila datos que le permiten lucrarse sin conceder ningún tipo de compensación a los usuarios. Los medios tradicionales y los creadores de contenido han visto caer sus ventas y sus utilidades, lo cual los ha impulsado a exigir medidas para que quienes se benefician de la información capturada por la plataforma paguen a quienes producen los contenidos que atraen y mantienen activos a los usuarios.
Lo sucedido en 1492 resulta iluminador para reflexionar en torno al valor de cambio y el uso de la información. En la actualidad, creemos que los indígenas pecaron de ingenuos al cambiar oro por espejitos, pero lo cierto es que para ellos el oro tenía valor de uso, pero no de cambio, y los espejos eran una innovación. En contraste, los europeos sabían que podían convertir arena en espejos y veían el valor de cambio del oro. Hoy en día, los usuarios no les conceden valor de cambio a sus datos ni a sus actividades en las redes sociales. Por eso, entregan despreocupadamente su información privada, sin reparar en que las corporaciones la procesarán y generarán ingresos valiéndose de ella. Nuevamente, aplica la máxima “cuando usted usa un servicio por el cual no paga, usted no es el cliente, sino la mercancía”. Probablemente, en un par de generaciones, nuestros descendientes creerán que fuimos ingenuos al cambiar oro —nuestros datos— por espejos —las redes sociales—. ¿Lograremos que los usuarios les concedan valor de cambio a sus datos y exijan una retribución a las grandes corporaciones?
Un ejemplo de regulación en otro sector permite visualizar algunas alternativas. A finales de los años setenta los bancos obligaban a los clientes a firmar contratos que incluían una serie de cláusulas consideradas leoninas; es decir, desequilibradas a favor de las entidades financieras. El regulador los obligó a cambiarlas para que fueran más transparentes. Así mismo, durante un tiempo el pago anticipado de los créditos tenía multas, lo cual evidentemente beneficiaba de forma desproporcionada a las entidades financieras y perjudicaba al usuario. Por fortuna, esta práctica fue prohibida. Tal cual ha sido estudiado por varias entidades, como las Fundaciones Karisma y Dejusticia, los contratos de las corporaciones digitales que operan en nuestro país son realmente desequilibrados y atentan contra los derechos de los usuarios. Habiendo dicho eso, es muy probable que en los próximos años el Estado colombiano, siguiendo las tendencias internacionales sobre habeas data, el derecho a la privacidad de datos sensibles y protección de los derechos digitales, aumente la regulación sobre estos contratos de adhesión, para proteger a las personas en sus interacciones en el mundo digital.
Como si fuera poco, las corporaciones digitales evaden impuestos, pues los anuncios que venden no se facturan con IVA y su ubicación legal se encuentra en paraísos fiscales, por lo cual tampoco pagan renta. Adicionalmente, las condiciones laborales de plataformas como Uber y Rappi son paupérrimas. No en vano, han sido descritas como “unicornios desalmados”.
Finalmente, estas plataformas violan la privacidad y la intimidad. Por mandato constitucional, la correspondencia de las personas es inviolable y las comunicaciones de voz solo pueden ser interceptadas o escuchadas por orden de un juez, pero actualmente nuestra actividad digital está en manos de un grupo de conglomerados internacionales que emplean sistemas de vigilancia no consentida. Dichos sistemas también deberían ser objeto de regulación.
Para terminar esta sección, expondré los argumentos de Han, Habermas y Zuboff sobre los peligros que presenta la imposición de las métricas sociales como contrapoder a las encuestas, en palabras de Foucault. Han (2022) cuenta que Rousseau, entusiasmado con el método estadístico del siglo XVIII, propuso una racionalidad aritmética sin comunicación. El filósofo sostenía explícitamente que la determinación de la voluntad general debería llevarse a efecto sin comunicación; es más, debería excluirla, pues, según él, toda comunicación deforma la imagen de la voluntad general.
Rousseau fue, para Han, el primer dataísta de la historia, pues creía que mientras más datos hubiese, más auténtica sería la voluntad general determinada. En contraste, creía que el discurso distorsionaba el resultado. En la actualidad, los dataístas creen que el big data y la inteligencia artificial son suficientes para tener una mirada global que capta con precisión todos los procesos sociales y los optimiza para el bien de todos. En contravía de la teoría de la acción comunicativa de Habermas, proponen una teoría comportamental de la información, que prescinde del discurso. Así, entienden las sociedades como sistemas totalmente predecibles (Han, 2022, p. 61).
Shoshana Zuboff también se opone a la perspectiva dataísta:
Si queremos renovar la democracia en las próximas décadas, necesitamos un sentimiento de indignación, una sensación de pérdida de lo que nos están quitando (...) lo que aquí está en juego es la expectativa que cada ser humano abriga de ser dueño de su propia vida y autor de su propia experiencia. Lo que está en juego es la experiencia interior con la cual conformamos nuestra voluntad de querer y los espacios públicos en los que actuar de acuerdo a esta voluntad. (Han, 2022, p. 69)
Siguiendo la idea de genealogía propuesta por Foucault, podría decirse que el libro como fuente de información era el medio dominante en los inicios de la democracia. Allí se plasmó y se difundió el discurso racional de la Ilustración. Después llegaron los medios de comunicación masiva, en los que lo importante no era la consistencia de los discursos ni la racionalidad de las ideas, sino el performance de los actores. De acuerdo con Han,
En esta estructura anfiteatral las masas son espectadores. Ahora en el siglo XXI los medios digitales y las redes sociales se presentan como el gran medio de información e interacciones. Ellas no tienen un centro y por lo tanto la esfera pública se desintegra en espacios privados. (2022, p. 33)
Como señalan los autores, los postulados de Habermas sobre la acción comunicativa suponían que el pensamiento que lleva a la formación de la opinión pública es genuinamente discursivo. En él es necesario la existencia del otro. “Sin su presencia y respeto como actor válido, mi opinión no es discursiva, no es representativa, sino autista, doctrinaria y dogmática” (Han, 2010, p. 46).
Según Eli Pariser (2011), lo que está destruyendo el espacio público es la personalización algorítmica de la red, pues cuanto más tiempo paso en internet, más se llena mi filtro de información que me gusta y refuerza mis creencias. “Por eso, la personalización de la red es una amenaza a la propia democracia” (Han, 2022, p. 48).
En las redes la información no es un recurso para obtener nuevo conocimiento, sino para reafirmar la propia identidad. “Abandonar las propias convicciones supone la pérdida de la identidad. La pretensión de validez de las tribus digitales como colectivos identitarios no es discursiva, sino absoluta, porque carece de racionalidad comunicativa” (Han, 2022, p. 54). Para Han, la tribalización de la sociedad pone en peligro la democracia, porque conduce a una dictadura tribalista que carece de toda racionalidad comunicativa. Es decir, en vez de argumentos y discursos, tenemos una guerra de identidades. En últimas, la democracia es una comunidad de oyentes y la comunicación digital destruye la política basada en escuchar.
En la actualidad, el discurso está siendo sustituido por los datos, y los argumentos, por los algoritmos. La inteligencia artificial no razona, sino que computa. Mientras los argumentos pueden afinarse en el proceso discursivo, los algoritmos simplemente se optimizan. En el mundo digital, la racionalidad es reemplazada por el machine learning.
La verdad ejerce una fuerza centrípeta que mantiene unida una sociedad. Y la fuerza centrífuga inherente a la información tiene un efecto destructivo sobre la cohesión social. El nuevo nihilismo se gesta dentro del proceso destructivo en el que el discurso se desintegra en información, lo que conduce a la crisis de la democracia (Han, 2022, p. 73). El carácter deliberativo de la comunicación no se da cuando se logra un consenso —que es, en realidad, inalcanzable—, sino cuando los participantes hacen aportes razonables y argumentados. Así mismo, el debate debería tener efectos comprobables en las vidas de los ciudadanos, que deberían experimentar mejoras concretas en su vida relacionadas con los asuntos discutidos.
Habermas (2011) hace énfasis en que el sistema de los medios es fundamental para la generación de opiniones públicas contrapuestas que cumplan con los estándares de la política deliberativa. El aumento en el uso de las redes sociales dificulta esto, pues las plataformas son todo menos neutrales: se trata de empresas que siguen los dictados del capital y pertenecen a conglomerados cuyos rendimientos se miden en términos de su valor bursátil.
Las redes sociales no solo atomizan aún más las discusiones públicas, sino que eliminan la diferencia entre lo público y lo privado. Mientras se espera que las decisiones políticas de los ciudadanos sean el resultado de la tensión entre el interés propio y el bien común, a los usuarios de las redes no puede exigírseles algo similar, porque no lo tienen ni se sienten parte de “lo común” o del debate colectivo. Es evidente que las empresas compiten por la atención de los usuarios valiéndose de estrategias que antes eran dominadas por la prensa sensacionalista; a saber, el entretenimiento, el melodrama y la personalización.
En definitiva, las redes sociales se han convertido en la nueva arena pública de discusión, pero su funcionamiento dificulta reflexionar y contenerse antes de opinar. Además, los pocos que se esfuerzan por usarlas de forma serena y crítica son menos emotivos y, por ende, menos visibles para el algoritmo, lo cual implica que su capacidad para tener impacto en el diálogo público es menor. En ese orden de ideas, atomizan las discusiones públicas y dificultan que las personas tengan debates serenos basados en argumentos racionales. En muchas ocasiones, la conversación gira en torno a conseguir likes, y no a encontrar soluciones constructivas.
CONCLUSIÓN
Las estadísticas son las matemáticas de la incertidumbre, del escenario donde los seres humanos reconocen los márgenes de error y la existencia de imperfecciones en el mundo. Su consolidación contribuyó a negar la predestinación y la prevalencia de la idea del libre albedrío. Pero luego de 400 años de contribuir a que los seres humanos escapáramos de la idea de dioses que decidían el destino de los hombres, está siendo utilizada para “vender” la idea de que un grupo de corporaciones son capaces de predecir el futuro, y por ello su promesa de valor se basa en la capacidad para anticipar lo que queremos y compraremos mañana.
Aunque los avances en la estadística y la capacidad de procesamiento de datos han sido muy significativos en las últimas décadas y han permitido a las empresas y los gobiernos tomar decisiones más informadas y eficientes, es importante recordar que estas herramientas son solo eso: herramientas que no pueden reemplazar el pensamiento crítico ni la deliberación democrática. Además, contrariamente a lo que quieren hacernos creer los conglomerados, la capacidad de la estadística para predecir el futuro es limitada, y afirmar que se trata de una herramienta todopoderosa implica adoptar una perspectiva reduccionista y simplista de la realidad que, paradójicamente, va en contravía de la esencia de esta disciplina; es decir, la aceptación de la incertidumbre. Lo cierto es que las predicciones estadísticas siempre tienen un margen de error y, por tanto, no garantizan el éxito en el mercado.
Resulta preocupante pensar que los conglomerados acumulen tanto poder sobre nuestras vidas que nos lleven a prescindir de los sistemas democráticos, pues la democracia —entendida como una forma de gobierno que se basa en la participación ciudadana y en la toma de decisiones colectivas— es esencial para garantizar la libertad y la justicia en una sociedad.
Es necesario reconocer que, además de que los algoritmos y las técnicas de análisis de datos tienen sesgos y limitaciones importantes, las grandes compañías emplean técnicas de recolección de datos que atentan contra el derecho a la privacidad y se lucran de dicha información sin otorgar ningún tipo de reconocimiento económico ni simbólico a los usuarios.
Es indispensable evaluar las implicaciones éticas del uso de estas técnicas, así como las consecuencias de corto y largo plazo para todas las partes involucradas. Es un grave error pasar por encima de los derechos de los usuarios con el único fin de maximizar las ganancias de grandes conglomerados económicos.
En síntesis, la estadística y el análisis de datos fueron herramientas sumamente valiosas para la toma de decisiones que nos permitieron liberarnos del yugo de los dioses del Olimpo. Paradójicamente, los grandes conglomerados están valiéndose de dichas herramientas para forzarnos a adorar a los poderosos de la Nube. Es hora de llamar la atención y reconocer los riesgos que las prácticas ejercidas por estas corporaciones representan para la democracia y los ciudadanos, pues solo así podremos idear estrategias para confrontar a los nuevos dioses del siglo XXI y liberarnos de sus designios.

