










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkCiencia en Desarrollo
Print version ISSN 0121-7488
Ciencia en Desarrollo vol.5 no.2 Tunja July/Dec. 2014
Métodos estadísticos de riesgos competitivos: un estudio comparativo
Statistical Methods for Competing Risks: A Comparative Study
S. Yáñez Canala,*
C. M. Lopera Gómeza
M. C. Jaramillo Elorzaa
a Escuela de Estadística, Universidad Nacional de Colombia, Sede Medellín, Colombia.
* Autor de correspondencia: syanez@unal.edu.co
Recepción: 14-jul-13 Aceptación: 30-oct-14
Resumen
El tiempo de falla de un sistema con dos modos de falla puede ser modelado como un sistema en serie o un modelo de riesgos competitivos. Cada unidad tiene un tiempo potencial de falla asociado a cada modo de falla, el tiempo de falla observado es el mínimo de esos tiempos potenciales individuales. Si se ignoran los riesgos competitivos y sólo hay un evento de interés, se utiliza la función de riesgo de causa específico, la cual asume que los otros riesgos no existen. En estas condiciones trabajan los métodos clásicos de Kaplan-Meier, la prueba log-rank y el modelo de riesgos proporcionales de Cox, por lo tanto sus resultados responden preguntas relacionadas al efecto "puro" asociado a una sola causa. Ahora bien, si se consideran de manera simultánea los riesgos competitivos, se utiliza la función de subriesgo o la función de riesgo de la subdistribución. Así, se han desarrollado metodologías alternativas que dan cuenta de esta situación. Por ejemplo, la función de incidencia acumulada (FIA), las pruebas de Gray y de Pepe & Mori, y finalmente la regresión de riesgos competitivos como contraparte del modelo de Cox. En este trabajo, estos últimos métodos, son presentados e interpretados. Ellos son ilustrados mediante un caso real en Interconexión Eléctrica S.A. E.S.P. (ISA).
Palabras clave: Función de incidencia acumulada (FIA), Kaplan-Meier, Prueba de Gray, Prueba de Pepe & Mori, Prueba log-rank, Regresión de Cox, Regresión de riesgos competitivos.
Abstract
The failure time of a system with two failure modes can be modeled as a series system or a competing risks model. Each unit has a potential failure time associated with each failure mode; the observed failure time is the minimum of such potential times. If the competing risks are ignored and there is only one event of interest, the cause-specific hazard is used, which assumes that the other risks does not exist. This is the setting for the classical methods of Kaplan-Meier, log-rank test and Cox proportional hazards model, therefore their results answer questions related to the "pure" effect associated to a single cause. On the other hand if the competing risks are considered as working jointly, the subhazard function or the hazard of the subdistribution are used. Thus, alternative methodologies have been developed to take into account the latter situation. Such as, the cumulative incidence function (CIF), Gray's test and Pepe and Mori's test, and finally competing risks regression, as the counterpart of Cox model. In this paper these methods are showed and interpreted. They are illustrated with a real case in Interconexión Eléctrica S.A. E.S.P. (ISA).
Key words: Competing risks regression, Cox's regression model, Cumulative incidence function (CIF), Gray's test, Kaplan-Meier, Log-rank test, Pepe & Mori's test.
1. Introducción
Las causas o las diferentes maneras como puede fallar un sistema o unidad reciben el nombre de modos de falla. Existen muchos sistemas, subsiste-mas y unidades que tienen más de un modo de falla; en ciertas aplicaciones y para algunos propósitos es importante distinguir entre esos diferentes modos de falla, con el objetivo de mejorar la confiabilidad [13]. El tiempo de falla de un sistema con p modos de falla puede ser modelado considerando un sistema en serie o un modelo de riesgos competitivos, donde cada modo de falla es una componente del sistema en serie (ver figura 1), y cada componente tiene un tiempo potencial de falla. El tiempo de falla observado es el mínimo de esos tiempos potenciales individuales.
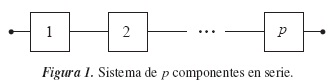
Muchas son las aplicaciones de riesgos competitivos en confiabilidad. Basu & Klein [1] obtuvieron algunos resultados en la teoría de riesgos competitivos; Nelson [15] presenta datos para el tiempo de falla (en horas) de calentadores industriales, que tienen dos modos de falla; Bedford & Lindqvist [2] trataron el problema de la identificabilidad en sistemas reparables cuando se presentan los riesgos competitivos; Bedford [3] muestra cómo modelar la confiabilidad en presencia de riesgos competitivos; Manotas, Yáñez, Lopera & Jaramillo [12], estudiaron el efecto en la estimación de la confiabilidad, cuando se asume el supuesto de independencia entre tiempos de falla en competencia que realmente son dependientes; Meeker, Escobar & Hong [14] usaron pruebas de vida aceleradas para predecir la distribución del tiempo de falla de un nuevo producto con dos modos de falla.
En la práctica es común ignorar los riesgos competitivos, de manera que se trabaja con un solo evento de interés, asumiendo que los otros eventos (riesgos competitivos) no existen; en estas condiciones trabajan los métodos clásicos de Kaplan-Meier, la prueba log-rank y el modelo de riesgos proporcionales de Cox, donde se utiliza la función de riesgo de causa específica. Por tanto, los resultados de estos procedimientos se concentran en el evento de interés, y solo pueden responder a preguntas pertinentes en contextos donde el objetivo sea estimar el efecto "puro" debido a una sola causa [18]. Ahora bien, si se considera el problema conjunto, que tiene en cuenta de manera simultánea todos los riesgos competitivos, se utiliza la función de subriesgo o la función de riesgo de la subdistribución. Por ello, se han desarrollado metodologías que dan cuenta de esta situación y son las contrapartes de las metodologías clásicas. Así, se tienen la función de incidencia acumulada, FIA [8], las pruebas de Gray [7] y de Pepe [16], y, finalmente, la regresión de riesgos competitivos [6], que sería la contraparte del modelo de Cox.
El objetivo de este trabajo es presentar y difundir las metodologías que tienen en cuenta los riesgos competitivos en la modelación de un sistema con dos modos de falla, y, adicionalmente, comparar estas metodologías con las técnicas clásicas a través de un caso real en Interconexión Eléctrica S.A. E.S.P. (ISA). La primera versión de este trabajo se presentó como comunicación en el Simposio Colombiano de Estadística [21].
En la sección 2 se presenta la base de datos que servirá para ilustrar los métodos para la modelación de un sistema con dos modos de falla. Los conceptos básicos de riesgos competitivos son presentados en la sección 3. Las secciones 4 y 5 presentan, respectivamente, los métodos para comparar curvas de incidencias de falla y el modelamiento utilizando covariables, que tienen en cuenta los riesgos competitivos. Finalmente, en la sección 6 se dan algunas conclusiones acerca de los métodos presentados, y de cómo sus resultados se diferencian de los obtenidos en los métodos clásicos, que no tienen en cuenta los riesgos competitivos.
2. Datos de interruptores en ISA
Para ilustrar los métodos presentados en este trabajo se consideran datos de la confiabilidad de interruptores tipo FL245 en Interconexión Eléctrica S.A. E.S.P. (ISA), que es una empresa colombiana cuya actividad principal es el transporte de energía eléctrica. Los interruptores de potencia (ilustrados en la figura 2) son usados para interrumpir el flujo de corriente y desconectar algún elemento de la sub-estación, para lo cual se pueden interrumpir tanto corrientes de carga normales como debidas a fallas eléctricas.

Los datos consisten de tiempos transcurridos hasta un evento de mantenimiento correctivo en este tipo de interruptores, recolectados durante el año de 1996. Se hizo un seguimiento a un total de 31 interruptores [11]. Los eventos de mantenimiento obedecen a fallas cuyas causas se clasifican principalmente en fugas de aceite en sistema hidráulico y fugas de gas. Durante el seguimiento se encontró que 4 interruptores presentaron solo fuga de aceite; 16, solo fuga de gas, y 7, ambos eventos. Los 4 interruptores restantes no presentaron evento mientras se observaron (dos llegaron al final del año sin evento y dos interruptores salieron del estudio antes de concluir el seguimiento), de manera que se consideran como censuras a derecha. Adicionalmente, se tienen características al inicio del estudio de los equipos observados, tales como: temperatura promedio del sitio donde está localizado el equipo, y el fabricante del equipo.
3. Métodos para datos de riesgos competitivos
Los datos de sobrevivencia en ausencia de riesgos competitivos se presentan, usualmente, como una variable aleatoria bivariada de la forma (T,C). La variable C es una variable de censura, cuyo valor es 1 si el evento de interés fue observado, y 0 en otro caso; cuando C = 1, T es el tiempo en el que el evento ocurrió, y cuando C = 0, T es el tiempo en el que la observación fue censurada.
Esta definición puede extenderse a la situación de riesgos competitivos, donde p ≥ 2 tipos de fallas o eventos son posibles. Los datos son de nuevo representados con el par (T,C), donde ahora C es una variable discreta que toma el valor de 0 si la observación es censurada, de i en el caso de que la observación no es censurada, donde i es el primer tipo de falla o evento observado (i = 1,2,..., p). Si C = i, entonces T es el tiempo en el que el evento de tipo i ocurrió, de lo contrario es el tiempo de censura [8, 5].
Para los datos de interruptores (ver tabla 1), T es el tiempo en días a la primera falla o censura observada, donde los tipos de eventos pueden ser: i = 1 para fallas debidas a fugas de aceite sin importar que luego ocurra o no una fuga de gas (evento de interés, al cual se hará referencia simplemente como fuga de aceite); i = 2 para las fallas provocadas por fugas solo de gas (riesgo competitivo, al cual se hará referencia simplemente como fuga de gas).

3.1. Definiciones básicas
Hay varias funciones de importancia en la teoría de riesgos competitivos, entre las cuales están las funciones de subdistribución, subsobrevivencia, subdensidad, subriesgo, riesgo de causa específica y riesgo de la subdistribución.
a) Función de subdistribución o de incidencia acumulada (FIA). Para un evento de tipo i, i = 1,2,..., p, la FIA se define como
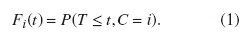
En otras palabras, la FIA es la probabilidad de que un evento de tipo i ocurra a lo sumo en el tiempo t. Note que la FIA solo puede tomar valores hasta P(C = i) debido a que l´ım Fi(t) = t→∞ P(C = i). La función de distribución total es la probabilidad de que un evento de cualquier tipo ocurra a lo sumo en el tiempo t, es decir, es igual a la suma de las FIA para todos los tipos de eventos, así:
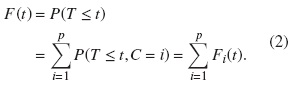
b) Función de subsobrevivencia. Es la probabilidad de que un evento de tipo i no ha ocurrido hasta el tiempo t
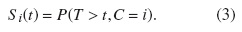
c) Función de subdensidad. Para eventos de tipo i, se define como
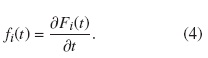
d) Función de subriesgo. En términos matemáticos, la función de subriesgo se define como:
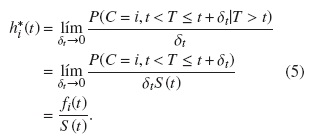
h*i(t) se interpreta como la tasa de falla instantánea de ocurrencia del evento de tipo i en el tiempo t dado que no había ocurrido ningún otro tipo de evento antes del tiempo t, en presencia de riesgos competitivos. El riesgo total de un evento de cualquier tipo puede ser calculado como la suma de todos los subriesgos, 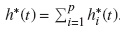 .
.
e) Riesgo de la subdistribución. Se define como:
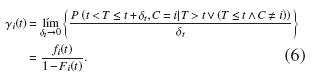
Note que el denominador no es una subsobrevivencia para eventos de tipo i.
f) Riesgo de causa específica. También conocido como riesgo de la distribución marginal, se define como:
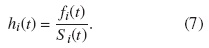
3.2. FIA
Sean t1 < t2 < ... < tr los puntos en el tiempo no censurados ordenados. En el caso donde no hay censura, una estimación empírica de la FIA para el evento de tipo i puede ser obtenida como

donde n es el número total de observaciones. Cuando se presentan censuras, la FIA puede ser calculada como la suma sobre todos los tj de las probabilidades observadas para el evento i en el tiempo tj, mientras que la unidad todavía está bajo riesgo. Esto es:
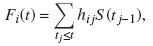
donde hij es el riesgo de causa específica para el evento i en tj. Intuitivamente, dado que una unidad no experimenta un evento de cualquier tipo hasta tj−1, la probabilidad de un evento de tipo i en el intervalo tj − δ a tj (para un δ> 0 pequeño) puede ser estimada como 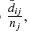 donde dij es el número de eventos de tipo i en el tiempo tj,y nj es el número de unidades a riesgo justo antes del tiempo tj. De aquí se sigue que
donde dij es el número de eventos de tipo i en el tiempo tj,y nj es el número de unidades a riesgo justo antes del tiempo tj. De aquí se sigue que
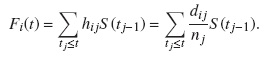
La FIA representa la probabilidad de que una unidad experimente un evento de tipo i a lo sumo en el tiempo t.
A continuación se muestran las FIA estimadas para los eventos de mantenimiento correctivos debidos al evento de interés fuga de aceite y al riesgo competitivo fuga de gas, en los interruptores FL245.
La figura 3 muestra las gráficas de las estimaciones de la FIA para cada tipo de evento: fuga de aceite y fuga de gas. Las probabilidades de falla debido al evento de interés en el año en que se realizó el análisis resultan siempre mayores que las probabilidades de falla asociadas al riesgo competitivo (fugas solo de gas); esto indica que la alta incidencia asociada al riesgo competitivo puede enmascarar la probabilidad de falla debida al evento de interés.
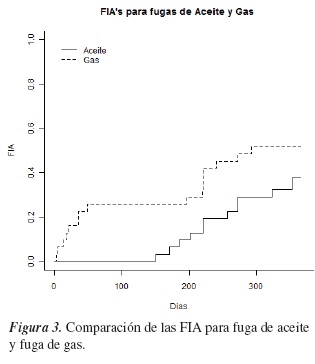
Todas las gráficas y resultados estadísticos mostrados en el artículo se realizaron usando el paquete estadístico R [20]. El código utilizado se suministra bajo pedido a los autores.
3.3. Comparación de la FIA con el estimador de Kaplan Meier
Para cualquier punto del tiempo tk, el complemento de la estimación de Kaplan-Meier (1 − KM) es mayor que la estimación de la FIA. Si tenemos dos tipos de eventos: el evento de interés, denotado por el subíndice 1, y el conjunto de eventos de riesgos competitivos, denotado por el subíndice 2, (1 − KM) para el evento de interés puede escribirse como:
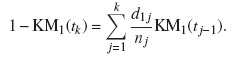
Por otro lado la FIA para el evento de interés es:
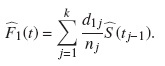
Hay que tener presente que KM1 es el Kaplan-Meier estimado cuando se utiliza solo el evento de interés y 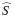 es el Kaplan-Meier estimado cuando se consideran todos los eventos (el evento de interés y los riesgos competitivos), es decir:
es el Kaplan-Meier estimado cuando se consideran todos los eventos (el evento de interés y los riesgos competitivos), es decir:
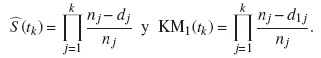
Por tanto, 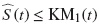 para todo t, con lo cual se concluye que:
para todo t, con lo cual se concluye que:
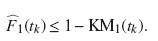
En la figura 4 se compara la probabilidad de falla de los equipos mediante el estimador (1 − KM1) y usando la FIA para el evento de interés.
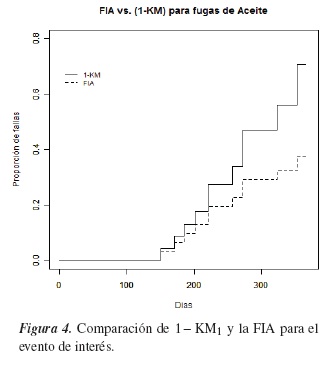
Se observa que ignorando los riesgos competitivos la probabilidad de falla estimada mediante (1− KM1) siempre sobreestima a la probabilidad de falla teniendo en cuenta los riesgos competitivos. Esto sugiere que se debe tener mucho cuidado al momento de dar una recomendación para la probabilidad de falla cuando los riesgos competitivos están presentes, ya que en este caso estaremos indicando que un equipo va a fallar antes del tiempo en el que realmente puede fallar.
4. Comparación de curvas de sobrevivencia en presencia de riesgos competitivos
Frecuentemente nos interesa evaluar si una aparente diferencia en la función de distribución o sobrevivencia entre dos grupos es real o se debe al azar. Cuando hay solo un evento de interés en presencia de una covariable que define dos grupos, el método usual para comparar curvas de sobrevivencia es la prueba long-rank; sin embargo, cuando se tienen riesgos competitivos el método long-rank puede no ser muy útil para comparar las curvas de sobrevivencia, debido a que no tiene en cuenta los riesgos competitivos. Puesto que tal comparación ignora que la probabilidad de falla del evento de interés (estimada por la FIA) puede depender no solo del riesgo de causa específica del evento de interés, sino también del riesgo de causa específica del riesgo competitivo, una alternativa para comparar las curvas de sobre-vivencia en presencia de riesgos competitivos son las pruebas desarrolladas por Gray [7] y por Pepe & Mori [16].
4.1. Método de Gray
La prueba para k muestras introducida por Gray [7] compara los pesos promedios de los riesgos de las funciones de subdistribución para el evento de interés. La forma general del score para el grupo i es:
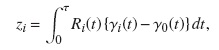
donde τ es el tiempo máximo observado en ambos grupos; Ri(t) es una función de ponderación; γi(t) es el riesgo de la subdistribución para el grupo i,y γ0(t) es el riesgo de la subdistribución para todos los grupos juntos. La función de ponderación, que representa el número de unidades a riesgo ajustado, es:
donde ni(t) es el número de unidades a riesgo en el tiempo t para el grupo i; 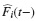 es la FIA del evento de interés justo antes del tiempo t para el grupo i; Si(t−)
es la FIA del evento de interés justo antes del tiempo t para el grupo i; Si(t−)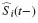 es el estimador de Kaplan-Meier para cualquier evento justo antes del tiempo t para el grupo i,y Ri(t) es el número de unidades en riesgo ajustado.
es el estimador de Kaplan-Meier para cualquier evento justo antes del tiempo t para el grupo i,y Ri(t) es el número de unidades en riesgo ajustado.
Puede observarse que ∑ zk = 0. El estadístico de prueba es una forma cuadrática de Z = (z1,...,zk)t con matriz de varianzas-covarianzas ΣZ . Bajo la hipótesis nula el estadístico de prueba se distribuye como 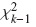 , esto es:
, esto es:
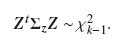
Supongamos que se desean comparar las FIA para el evento de interés en dos grupos. Sea Fk( j,t) la función de subdistribución para la falla de tipo j en el grupo k (k = 1,2).
• La hipótesis nula es:
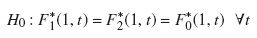
• Estadístico de prueba:
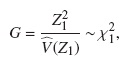
con
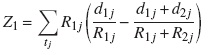
4.2. Prueba de Pepe & Mori
Pepe & Mori [16] proponen un método para comparar directamente las FIA. Esta basado en el trabajo de Pepe [17] donde propone una prueba para comparar dos curvas de sobrevivencia.
Pepe [17] probó que bajo la hipótesis nula
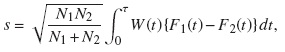
es asintóticamente normal con media 0 y desviación estándar σ. En esta fórmula, Fi(t) representa la FIA para el evento de interés en el grupo i; Ni es el número total de observaciones en el grupo i,y W(t) es una función de ponderación.
Para el caso discreto donde t1,t2,...,tn son los tiempos ordenados para todas las observaciones en ambos grupos. La fórmula anterior se convierte en:
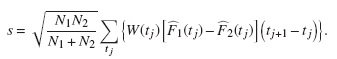
La función de ponderación está dada por
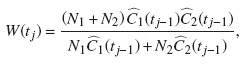
donde 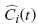 es el estimador de KM de la función de sobrevivencia con eventos definidos censuras o riesgos competitivos en el grupo i.
es el estimador de KM de la función de sobrevivencia con eventos definidos censuras o riesgos competitivos en el grupo i.
La varianza estimada de s es un promedio ponderado de las varianzas de los dos grupos
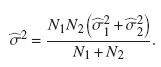
Lunn [10] extiende esta prueba a k grupos.
A continuación se muestran las diferencias que pueden existir entre aplicar el método log-rank ignorando los riesgos competitivos y usar las pruebas tanto de Gray como de Pepe & Mori. Para ello se quiere comparar la incidencia de falla debida al evento de interés, considerando dos fabricantes (A y B) del interruptor FL245. La siguiente gráfica muestra la comparación de las curvas estimadas por (1-KM) a través de la prueba log-rank; esto está ignorando el riesgo competitivo.
De la figura 5, al comparar las curvas de sobrevivencia para cada fabricante, se observan diferencias significativas (el valor-p asociado al estadístico longrank es 0.029); esto indica que la probabilidad de falla de estos equipos depende estadísticamente del tipo de fabricante. Vale la pena aclarar que la anterior comparación no tiene en cuenta los riesgos competitivos, es decir, estos son tomados como censura.
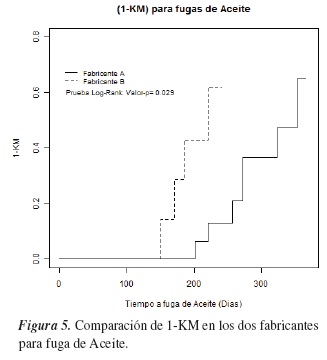
La figura 6 muestra las gráficas de las FIA para cada fabricante; en ella no se observan diferencias entre las probabilidades de falla de acuerdo con esta variable, lo cual es corroborado por el estadístico de Gray (valor-p = 0,296) y el de Pepe & Mori (valor-p = 0,15).
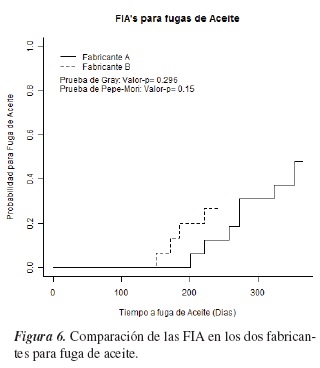
5. Modelo de regresión de Cox
El modelo de riesgos proporcionales introducido por Cox [4], es el más utilizado para representar los efectos de un conjunto de variables explicativas (covariable) sobre el tiempo de ocurrencia de un evento o, más bien, sobre la función de riesgo h(t). De manera clásica, el riesgo para una unidad i con un grupo de covariables x1i, x2i,..., xmi puede descomponerse en dos partes: una que involucra el tiempo, pero no las covariables, y otra que involucra las covariables, pero no el tiempo.
El modelo es:
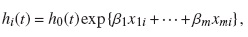
donde h0(t) es la función de riesgo base y β1,...,βm son los parámetros o los coeficientes que deben estimarse. Supongamos que tenemos t1 < t2 < ... < tr tiempos de falla ordenados. La estimación de los coeficientes β1,...,βm( se obtiene maximizando la verosimilitud parcial
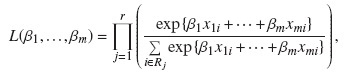
donde el producto es tomado sobre todos los tiempos de falla tj,y Rj representa el grupo de unidades que están a riesgo justo antes del tiempo tj.
En presencia de los riesgos competitivos, la regresión se centra en la modelación del riesgo de la FIA [6]. El modelo, llamado regresión de riesgos competitivos, está basado en
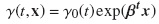
donde γ es el riesgo de la subdistribución, γ0 es el riesgo base de la subdistribución, x es el vector de covariables y β es el vector de coeficientes.
La forma de la verosimilitud parcial es similar a la usada en el modelo de riesgos proporcionales de Cox. Por ejemplo, para una covariable la verosimilitud parcial está dada por
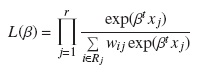
donde
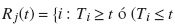 y el sujeto experimenta un evento de riesgos competitivos)®.
y el sujeto experimenta un evento de riesgos competitivos)®.
Así, aquellos que experimentaron otro tipo de evento permanecen en el grupo de riesgo todo el tiempo. Las ponderaciones son definidas como:
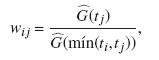
donde, 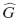 es el estimador de KM de la función de sobrevivencia de la distribución de censura.
es el estimador de KM de la función de sobrevivencia de la distribución de censura.
La distribución de censura es definida por (Ti, Ci), donde Ti es el tiempo al primer evento y

La estimación de β, 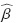 maximiza la función U(β)
maximiza la función U(β)
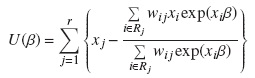
La predicción de la FIA puede calcularse para cierto valor de la covariable usando la fórmula
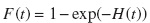
donde H(t) es el riesgo acumulado de la subdistribución. Esta función puede estimarse usando el estimador tipo Breslow:
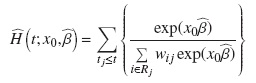
Para los datos de interruptores se toman el fabricante de estos y las mediciones de temperatura promedio del sitio donde está instalado el interruptor como covariables de interés para establecer el efecto de estas sobre el riesgo de ocurrencia del evento.
En la tabla 2 se muestran las estimaciones de los parámetros tanto del modelo de regresión de riesgos competitivos como del modelo clásico de riesgos proporcionales de Cox. Adicionalmente, se da el valor-p de la prueba de significancia asociada a cada parámetro estimado.
De los resultados mostrados en la tabla 2 se observa que al ignorar los riesgos competitivos, es decir, cuando el modelo de Cox es utilizado, el coeficiente estimado para la variable temperatura es altamente significativo (valor-p = 0,0028) sobre el riesgo de falla asociado al evento de interés. Sin embargo, cuando en el modelo se considera el riesgo competitivo (regresión de riesgos competitivos), la significancia de la temperatura se reduce (valor-p = 0,015), lo cual implica que la presencia del riesgo competitivo afecta la significancia de tal variable. Por otro lado, si se considera el riesgo competitivo como si fuera el evento de interés, se da el efecto contrario, es decir, la presencia de las fugas de aceite en la modelación del riesgo de falla debida a fugas de gas se torna más significativa al pasar del modelo de Cox al modelo de riesgos competitivos (valor-p = 0,011 a valor-p = 0).
Ahora, note que en los resultados asociados a la variable fabricante se observa que esta, en el modelo de Cox, es significativa para los dos tipos de eventos considerados (valor-p = 0,036 para el evento de interés y valor-p = 0,025 para el riesgo competitivo), pero cuando se hace la modelación conjunta de los dos eventos, en ambos casos (cuando el evento de interés es fuga de aceite y cuando el evento de interés es fuga de gas) se concluye que la variable no es significativa (valores-p de 0,48 y 0,94, respectivamente).
Es importante notar que hay una gran diferencia entre los modelos considerados, ya que en los parámetros estimados hay grandes cambios, entre los que se destacan: 1) el coeficiente estimado para el efecto de la temperatura sobre el riesgo de incidencia de eventos de fugas de aceite, cuando se considera el riesgo competitivo, tiene signo negativo, mientras que si se ignoran los eventos de fugas de aceite el coeficiente es positivo; esto indica que al considerar conjuntamente los dos eventos se llega a conclusiones en sentido opuesto a lo que indicaría el modelo de Cox; y 2) los coeficientes estimados para la temperatura cuando se considera como eventos de interés las fugas de gas se tornan mayores en magnitud al pasar del modelo de riesgos competitivos al modelo de Cox, lo cual puede estar asociado a que la ocurrencia de eventos de fuga de aceite enmascara la ocurrencia de eventos de fugas de gas.
A continuación se presentan algunos gráficos que permiten evaluar el supuesto de riesgos proporcionales para el modelo de Cox.
La figura 7 muestra que el comportamiento de log(-logS ) vs. log(tiempo) [9] es aproximadamente paralelo, indicando que el supuesto de riesgos se puede asumir como proporcional para el modelo de Cox. También se pueden evaluar gráfica y analíticamente los residuales Schoenfeld [19], cuyos resultados se muestran a continuación.

Observe que en la figura 8 la forma funcional de ambas variables (temperatura y fabricante) se puede aproximar mediante un valor promedio, lo que indica que el supuesto de riesgos proporcionales para el modelo de Cox es válido. También, con base en los residuales Schoenfeld se puede realizar una prueba analítica [19], cuya hipótesis nula es que el supuesto del modelo de Cox se cumple; para esta prueba se tienen valores-p de 0,698 y 0,922 para las variables fabricante y temperatura, respectivamente. Esto indica que se acepta la hipótesis de riesgos proporcionales del modelo de Cox.

Infortunadamente, el modelo de riesgos competitivos aún no posee muchas alternativas para validar el supuesto de riesgos proporcionales. La figura 9 permite visualizar el comportamiento de log(− log(1 − FIA)) vs. log(tiempo), de manera similar a lo que se hace en el modelo de Cox.
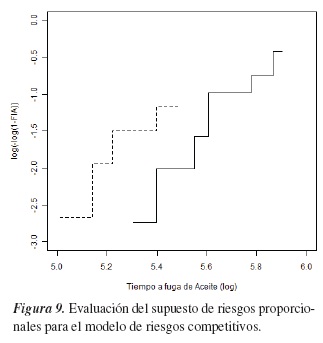
Note que en este gráfico las curvas representadas son aproximadamente paralelas, indicando que el supuesto de riesgos proporcionales se puede asumir para el modelo de riesgos competitivos.
6. Conclusiones y recomendaciones
A continuación se establecen algunas conclusiones generales de la comparación de los métodos tradicionales con los que incorporan riesgos competitivos. En estas condiciones vale la pena destacar que el ejemplo con datos reales es solo una ilustración de las metodologías, que no invalida el carácter general de los resultados.
Hay que tener mucho cuidado al momento de dar una recomendación de la confiabilidad para un evento de interés cuando se tienen riesgos competitivos, ya que si estos son ignorados la incidencia del evento es sobreestimada en relación con la que se obtiene al modelar teniendo en cuenta los riesgos competitivos.
Cuando se considera una covariable que determina las formación de grupos, y si el interés del investigador se centra principalmente en establecer las diferencias entre las incidencias del evento de interés en los diferentes grupos, entonces lo ideal es comparar las FIA utilizando el estadístico de Gray o el estadístico de Pepe & Mori. Por otro lado, si lo que se quiere establecer es el mecanismo de falla, entonces puede usarse una prueba log-rank.
Cuando los riesgos competitivos están presentes, las estimaciones de los parámetros de regresión de Cox cambian en relación a las estimaciones del modelo de Cox cuando no tienen en cuenta los riesgos competitivos. El fenómeno consiste en que los efectos estimados son mayores en el modelo de Cox, lo cual puede ser consecuencia directa de que la incidencia de un tipo de evento no permite observar la incidencia del otro tipo de evento. Lo anterior afecta el modelamiento del riesgo de la FIA, pero no el riesgo de causa específica.
En resumen, se puede decir en general que los métodos clásicos basados en el riesgo de causa específica al comparar grupos o probar la significancia de covariables estiman el efecto "puro" de un tipo de evento (asumiendo que los demás tipos de eventos no existen). De manera que, con base en ello, se debe saber cuándo las preguntas de investigación en un estudio llevan a realizar análisis utilizando los métodos clásicos y cuándo, por el contrario, el interés principal obliga a incluir en las estimaciones a los riesgos competitivos.
Agradecimientos
Los autores agradecen a los árbitros y al editor por sus valiosos comentarios que enriquecieron el manuscrito. Este trabajo fue financiado por Colciencias, Colombia; es parte del proyecto de investigación "Characterization of dependence in competing risks models in industrial reliability", código 110152128913.
Referencias
[1] Basu, A. and Klein, P., "Some recent results in competing risks theory, Proceedings on survival analysis". IMS monograph series, vol. 2, pp. 216-229, 1982. [ Links ]
[2] Bedford, T. and Lindqvist, B., "The identifiability problem for repairable systems subject to competing risks", Advances in Applied Probability, vol. 36, no. 3, pp. 774-790, 2004. [ Links ]
[3] Bedford, T., Competing risk modelling in reliability. In: Modern statistical and mathematical methods in reliability, World Scientific Books, United Kingdom, 2005. [ Links ]
[4] Cox, D., Regression models and life-tables, Journal of the Royal Statistical Society. Series B, vol. 34, no. 2, pp. 187-220, 1972. [ Links ]
[5] Crowder, M., Classical competing risks, Chapman & Hall/CRC, Boca Raton, FL, 2001. [ Links ]
[6] Fine, J. and Gray, R., "A proportional hazards model for the subdistribution of a competing risk", Journal of the American Statistical Association, vol. 94, no. 446, pp. 496-509,1999. [ Links ]
[7] Gray, R., "A class of k-sample tests for comparing the cumulative incidence of a competing risk", The Annals of Statistics, vol. 16, no. 3, pp. 1141-1154, 1988. [ Links ]
[8] Kalbfleisch, J. and Prentice, R., Statistical analysis of failure time data, John Wiley & Sons, New York, 1980. [ Links ]
[9] Lawless, J., Statistical models and methods for lifetime data, John Wiley & Sons, New York, 1982. [ Links ]
[10] Lunn, M., "Applying k-sample tests to conditional probabilities for competing risks in a clinical trial, Biometrics, vol. 54, no. 4, pp. 1662-1672, 1998. [ Links ]
[11] Manotas, E. and Lopera, C., Metodología para el análisis de datos de recurrencia aplicada a los interruptores FL245, Documento DGM2004-I-S-ET-023-V1, Interconexión Eléctrica S.A. E.S.P., pp. 1-145, 2004. [ Links ]
[12] Manotas, E., Yáñez, S., Lopera, C. and Jaramillo, M., "Estudio del efecto de la dependencia en la estimación de la confiabilidad de un sistema con dos modos de falla concurrentes", Dyna, vol 75, no. 154, pp. 5-21, 2008. [ Links ]
[13] Meeker, W. and Escobar, L., Statistical methods for reliability data, John Wiley & Sons, New, 1998. [ Links ]
[14] Meeker, W. and Escobar, L. and Hong, Y., "Using accelerated life tests results to predict product field reliability", Technometrics, vol. 51, no. 2, pp. 145-161, 2009. [ Links ]
[15] Nelson, W., Accelerated testing: Statistical models, test plans and data analyses, John Wiley & Sons, New York, 1990. [ Links ]
[16] Pepe, M. and Mori, M., "Kaplan-Meier, marginal or conditional probability curves in summarizing competing risks failure time data?", Statistics in Medicine, vol. 12, no. 8, pp. 737-751, 1993. [ Links ]
[17] Pepe, M., "Inference for events with dependent risks in multiple endpoint studies", Journal of the American Statistical Association, vol. 86, no. 415, pp. 770-778, 1991. [ Links ]
[18] Pintilie, M., Competing risks: A practical perspective, John Wiley & Sons, United Kingdom, 2006. [ Links ]
[19] Therneau, T. and Grambsch, P., Modeling survival data: Extending the Cox model, Springer-Verlag, New York, 2000. [ Links ]
[20] R Core Team, R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing, Vienna, Austria, 2010. http://www.R-project.org/. [ Links ]
[21] Yáñez-Canal, S., Lopera-Gómez, C.M. and Jaramillo-Elorza, M.C., Métodos de riesgos competitivos para la modelación de un sistema con dos modos de falla, Memorias del Simposio de Estadística, Universidad Nacional de Colombia, Bogotá, 2010, pp. 131-149, 2010. [ Links ]
