











 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
Permalink1. INTRODUCTION
Vertical seismic profile (VSP) data belong to a class of borehole seismic measurements that are commonly correlated with surface seismic data to improve vertical resolution on imaging processes. In particular, VSP refers to measurements with geophones located inside a wellbore at different depths and a source of energy located at the surface near the well. When the source is near to the well surface location, the VSP is called Zero-offset VSP. Numerous techniques have been proposed for improving the VSP signal quality through interpolation and noise reduction, most of which are classified in three main categories: methods based on physical wave propagation modelling [1], predictive modelling based on the linearity of seismic events [2], and domain-transform methods based on the sparsity of seismic data in an auxiliary domain [3].
More precisely, domain-transform methods are based on the sparse signal representation in dictionaries that is a signal processing framework intended to represent the signal of interest as a linear combination of a few predefined or learned signals belonging to a dictionary [4]. In this sense, several algorithms have been developed in recent decades for estimating these sparse coefficients such as matching pursuit [5], orthogonal matching pursuit [6], basis pursuit [7], among others. Furthermore, in this context, dictionary training approaches have also been developed in order to build transformation bases that enable describing the signals at hand.
Domain-transform based methods for interpolation and denoising of seismic data are generally processed using one of the following transform-domains: curvelet[8], pocs[9] and dreamlet [10]. Additionally, dictionary learning approaches for noise reduction were reported in [11], [12] and [13]. In a previous work, Beckouche [14] designed a dictionary learning that only used one dataset. However, despite being a learning dictionary, statistical processes require more than one dataset for extracting important and accurate Signal-based data.
The purpose of this study is to examine a sparse representation technique for denoising and interpolation of VSP data and refraction seismic data. In this study, sparse representation uses the OMP algorithm and a dictionary trained with a 29 VSP datasets for denoising seismic signals. We acquire refraction data and apply the OMP algorithm to interpolation of traces randomly annulled. The results obtained through application of the OMP algorithm for interpolation are encouraging as after the signal is being denoised using data redundancy, the interpolation process takes place. Results obtained with synthetic traces, as well as for real VSP and refraction seismic data, validate the proposed application.
2. THEORETICAL FRAME
Sparse signal representation in over complete dictionaries is an analytic tool that has been satisfactorily implemented in multiple signal and image processing applications such as image compression [15], audio denoising [16], and seismic signal pre-processing [17]. Its principle basically consists in representing the signal of interest as a linear combination of a few columns from a previously specified redundant matrix called dictionary, where each column of this matrix is called an atom of the dictionary. To be precise, let us consider the discrete-time signal of interest denoted by the vector x G 5Rm; this signal can be represented as

where D ∈ 𝕽mxn with m<n is the dictionary matrix and a ∈ 𝕽m is the coefficient vector that generally contains just a few nonzero entries. Equation 1 leads to an underdetermined set of linear equations whose solution is known to be a combinatorial NP-hard problem. In general, a sparse signal representation can be obtained by implementing diverse estimation techniques such as matching pursuit (MP) [5], orthogonal matching pursuit (OMP) [6], basis pursuit (BP) [7], and many others. On the other hand, the dictionary training has involved a set of techniques enabling the design of dictionary atoms that better describe the signals at hand, where the KSVD algorithm [18] is the most representative method. In this work, we develop the interpolation and denoising of refraction and VSP seismic signals based on OMP and KSVD algorithms. Furthermore, when the sparse signal representation is used for denoising, it is assumed that the relevant energy of the noiseless signal can be obtained as a linear expansion of a small number of atoms of the dictionary. Therefore, after determining a sparse coefficient vector by implementing a reconstruction algorithm such as OMP, a noiseless version of the desired signal can be restored by using the linear operator of the Equation 1. Additionally, the denoising process can be performed using OMP because sparse representation implicitly implements a thresholding operation.
3. STATE OF THE TECHNIQUE
ORTHOGONAL MATCHING PURSUIT (OMP)
OMP algorithm belongs to the class of greedy algorithms that iteratively estimates the signal coefficient vector [6]. More precisely, this algorithm selects the dictionary atom that best correlates with a predefined residual, where the selected atoms are continually updated such that the signal is expanded in an orthogonal subspace. Furthermore, at each iteration, the residual is projected onto the orthogonal complement subspace expanded by the selected atoms. In sum, this method finds an approximate estimate of the true support set, which contains the indices of the columns contributing to the original sparse vector. The OMP algorithm gives an approximate solution to Equation 1 providing a solution to one of the following problems:
a. Sparsity-constrained coding problem, given by: are taken before and after this point.
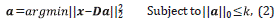
b. The error-constrained sparse coding problem, given by:
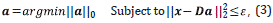
where k is the number of representation coefficients, and ε is the approximation error.
The OMP algorithm can be stated as follows: Firstly, initialize the residual r=x then select in each step, the atom D i with the highest correlation with to the current residual signal r, this step can be thought of as a comparison between each atom D,-to and the current residual. Once the atom D, is selected, the signal is orthogonally projected to the span of the previously selected atoms including D i the residual is recomputed, and the process is repeated from the beginning (see algorithm 1 in Table 1). The reader is encouraged to note that line 5 presents the greedy selection step, and line 6 shows the orthogonalization step. [17].

K-TIMES SINGULAR VALUE DECOMPOSITION
Sparse representation intrinsically implies that the signal can be reconstructed by using only a few numbers of atoms from a dictionary. This sparse coding can be easily obtained by designing a dictionary from a training data set. The learning dictionary shows a Local structure from seismic data and a sparse representation within a fixed dictionary. A fundamental question in the above formulation is the choice of an appropriate dictionary. For this purpose, a K- SVD algorithm is executed in order to design such a dictionary. The K-SVD algorithm requests for an initial dictionary D 0, iterations k, and a data set arranged in an X array. This algorithm searches for a good dictionary that best reproduces the signals X. This problem is formulated as follows:

The K-SVD algorithm initially calculates the coefficients for sparse representation in a matrix A followed by an update of the atoms in the dictionary; see algorithm 2 in Table 2. K-SVD uses OMP for sparse coding and the dictionary update is performed one atom at a time, thus optimizing the target function for each atom individually while keeping the rest fixed [18].

Letting i denote the indices of the signals in X, which use the j-th atom, the update is obtained by optimizing the target function.

over both the atom and its related coefficients in row A i. The resulting problem is a simple rank-1 approximation task given by
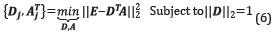
Where D j and A j means the j-th column of dictionary D and j-th row of coefficients matrix A, respectively; also E j=X j-Σ D j A j is the error matrix without the j-th atom , D k is the updated atom and AA Tis the new coefficient in row A j . This problem can be solved using SVD decomposition of the matrix E j =U∧V T ; the update D ¡ is a first column of U and the multiplication of the first eigenvalue ∧(1,1) and first column of V is used to update the coefficient AJ.
4. EXPERIMENTAL DEVELOPMENT
DICTIONARY LEARNING
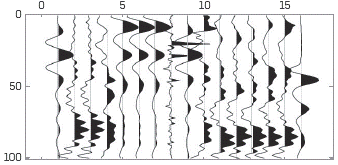
The set of training data for designing the dictionary is composed of 29 check-shot VSP dataseis. The matrix of training signals is a non-overlapping array containing samples of size 100 in time. In order to build an initial dictionary, 160 signals of the VSP dataseis are randomly selected. The dictionary has been trained based on the following parameters: k=15 iterations and K=5 number of coefficients for OMP sparse coding; these parameters are based on previous works found in literature, and 5 coefficients are the minimum coefficients that represented the signal with minimum error. Waveforms are shown in Figure 1 (zoom over 16 atoms), which are the best representation of VSP data as these dictionaries extract the main characteristics of training data.
DENOISING SYNTHETIC VSP DATA
Synthetic data are obtained from a visco-acoustic attenuation model and the source is modelled using a Ricker wavelet with 20 Hz as the dominant frequency a quality factor of 50, a wave velocity of 2000 m/s, and the geophones are placed in separate locations using regular distances. The synthetic signals are contaminated by additive white Gaussian noise with a SNR of 5 dB. For noise reduction, the OMP algorithm is implemented with a window of 100 ms and one sample shifted at a time. Additionally, five coefficients are used for the sparse coding using OMP. Figure 2 shows the seismic traces before being interpolated and denoised. After the interpolating and denoising process, the output traces have a SNR equal to 16 dB, showing an improvement of about 11 dB. We use Fourier bases on the interpolation process to compare reconstructed traces, using OMP with both dictionaries (Fourier bases and dictionaries trained) To determine performance of both approaches, we use matching by correlation between reconstructed traces and the original trace. The correlation of the original trace with the reconstructed trace with OMP using Fourier bases is 0.6170 and 0.6260 using OMP with dictionaries learned (DL).

Figure 2 Signal contaminated (zoom 15 traces) with withe Gaussian noise with SNR=5 dB and removed 4 traces.
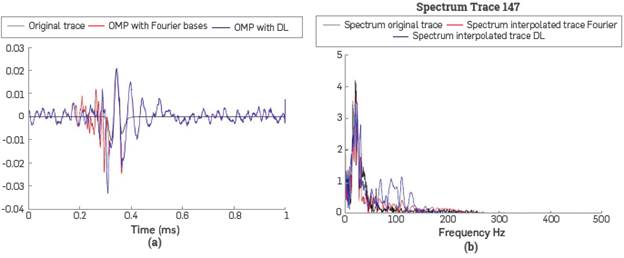
Figure 3a shows that seismic trace 15 from the synthetic data after the OMP process improve the spectral distribution of the signal and recover the amplitude and phase of the wavelet, showing that relevant content of the trace are preserved. It it also shows that the noise components at low and high frequencies are attenuated.
5. RESULTS
ON REAL VSP DATA RESULTS
Improvements in SNR relation and recovery of lost traces is material in VSP processing, considering that quality factor estimation based on logarithmic spectral ratio, centroid frequency-shift, and peak frequency-shift methods are very sensitive to amplitude spectrum distribution.
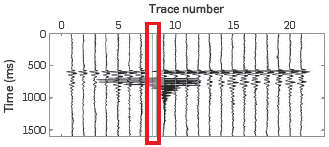
We design an experiment to evaluate the performance of the OMP algorithm on real data. In this experiment, we removed ten traces from the original data at random locations, as shown in Figure 4 simulating missing traces.
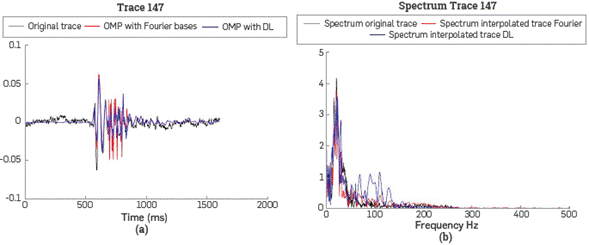
Assuming that bad traces and traces that first break do not correspond with neighbourhood traces, these are removed in the quality control stage. The application of OMP algorithm must restore these traces by interpolation and attenuate the noise in all the data, as show in Figure 5. Comparison at time and frequency domain between original and recovery traces by OMP is encouraging The correlation between original traces with reconstructed traces with OMP using Fourier bases is 0.6538 and 0.6668 using OMP with dictionaries learned (DL).
NEAR-SURFACE SEISMIC REFRACTION RESULTS
Acquisition in shallow seismic refraction to estimate a P-wave velocity-depth model requires the identification of first-arrival times associated with refracted waves [19]. Correct picking of first arrival is required for the tomography inversion process and it is affected by loss data and low S/N relation traces.
A further problem in land data is the restriction to locate receivers in regular areas; therefore, new data acquisition design based in sparse data is a possible solution. We acquire refraction data to test the performance of OMP algorithm for interpolation of randomly annulled traces.
The experiment acquired 160 different shots with only one trace by shot so as to have sufficient redundancy to build the trained overcomplete dictionary. This dictionary contains main characteristics (shapes) of this kind of signals, which allows representing a wide range of signal phenomena. Figure 6 shows a trained dictionary of 160 atoms (traces) of 100 samples each in time.
To evaluate this method on refraction seismic data, data was acquired using a sample rate of 0.5 ms and 24 different offsets. We remove 6 traces at random positions and used OMP for interpolation of these data.
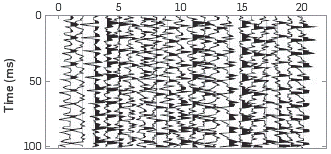
Figure 7a shows the data with 6 removed traces and the data after the interpolation process (Figure 7b). The correlation of the original traces with reconstructed traces with OMP using dictionaries learned is 0.6513.
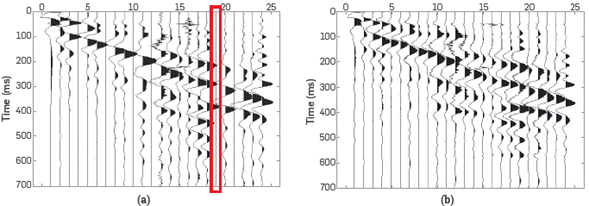
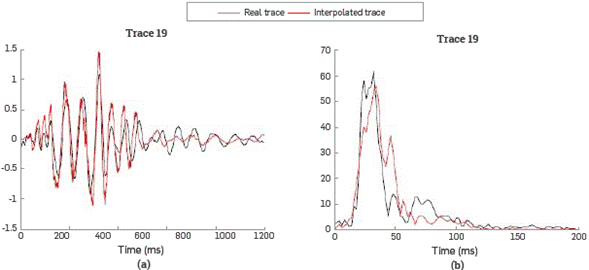
Figure 8 shows the original trace and the interpolated trace. The reconstructed traces show the same shape as the original data, and preserve the amplitudes and phases, which produce a very good alignment of the refraction event.
CONCLUSIONS
The main contribution of this work is the implementation and validation with real data of an Orthogonal Matching Pursuit (OMP) algorithm for interpolation and denoising. The advantage of the OMP technique in relation with other interpolation techniques is its robustness against the presence of noise, as it is based on a trained dictionary with redundant data.
Real VSP data test demonstrated that it is possible to accurately recover seismic signals from low signal to noise ratio data eliminating high frequencies through overlapping windows with only a few coefficients from its representation. This result must have an impact on quality factor estimation methods in frequency domain.
This technique works as a reconstruction method that promotes prior knowledge of the signal sparsity. Application to interpolation shows that traces missing randomly on refraction seismic data are recovered with high performance in amplitude and phase.


